
플로라도의 data workout
EECS 498-007 Lecture2 : Image Classification 정리 본문
EECS 498-007 Lecture2 : Image Classification 정리
플로라도 2024. 3. 4. 12:58
Image Classification은 컴퓨터 비전에서 가장 핵심적인 task이다.
그러나 그것이 쉽지는 않다. 컴퓨터는 고양이 이미지를 보고 단박에 고양이('cat')라고 알 수 없다.
(Computer can't get holistic idea of cat)

컴퓨터가 보는 것은 단순히 [0,255] 픽셀 값으로 이루어진 숫자 그리드 형태이다.
이것을 "고양이"라는 의미론과 대비되는 "Semantic Gap"이라고 한다.

심지어 고양이가 조금 움직인다면, 고양이가 서있다가 앉아있게 된다면, 픽셀값은 전부 변하게 된다.
이러한 변화에도 사람은 여전히 고양이라고 알 수 있지만, 컴퓨터가 이것을 여전히 같은 고양이라고 말하는 것은 쉬운일이 아니다. (-> 이러한 변화에 robust한 모델을 만드는 것이 목표가 된다.)

사진 속 다양한 앙증맞은 고양이들은 모두 서로 다른 픽셀값을 갖는다.
같은 종이라도 정도의 차이가 있다.(variation)
이러한 variation에도 여전히 고양이라고 인식하는 것도 어려움 중 하나이다.

또 다른 문제는 시각적으로 비슷하게 보이는 고양이들을, 서로 다른 종으로 분류하기 원할 때이다.
세분화된 카테고리를 나누는 것은 무척이나 어렵다.
실제로 가장 큰 어려움이며, 여전히 어떤 올바른 알고리즘을 써서 픽셀을 변화시켜야 되는지에 대해서는 명백하지 않다.

때때로 우리는 위장과도 같은 상황, 배경과 매우 유사해서 가려진 상황에서도 잘 구분해 낼 수 있어야한다.

또한 우리는 scene의 조도의 변화에도 robust할 수 있어야한다. 같은 object에 대해 다양한 lighting condition에 대해서 동일하게 판단해야 할 수 있을것이다.

때때로 우리가 인식하기 원하는 물체가 같은 물체인데 매우 다른 포즈를 취할때가 있다.

Occlusion (가려진 상황)
우리는 고양이가 보통 집에 살아서 어디 밑으로 숨어가길 좋아한다던지, 하는 생각이 있기 때문에 우측과 같은 꼬라 하나만을 보고도 단박에 직관적으로 고양이라고 알 수 있다.
그러나 이미지 자체로만 본다면 저 꼬리만 보고 고양이라고 판단하는 것은 매우 crazy하다. 라쿤이라고도 말할 수 있는것이 아닌가? (그러나 라쿤은 보통 집에 살지 않는다) 이러한 추론적인 상황이 올바른 이미지 판단에 포함되기 때문에 매우 매우 challenge하다.

지난 시간에도 봤던 장표이다. 과학적인 분야에서 image classification은 매우 매우 유용한데, medical image에서 악성 종양인지 양성 종양인지 분류한다던지, 고래의 종류가 뭔지 분류한다던지, 은하를 분류한다던지 등 scientific application에서 매우 유용하다고 소개한다.

이번에는 다소 덜 직관적일 수도 있는 내용이다.
우리가 다루는 컴퓨터 비전의 알고리즘의 대부분에 image classificaiton이 매우 근본적인 building block이라는 것이다.
그 한 예시가 "object detection"인데, object detection은 이미지 내의 물체가 무엇인지 판단하는 것 뿐만 아니라 어디에 위치해 있는지 까지 알아내길 원한다. image classification은 object detection과 같은 더욱 complex application에 대해서 sub part로서 작동한다.

object detection의 실제 수행을 예를 들면, sliding window방식을 통해 각 image의 sub region을 classification 한다.

object detection에서 해당 window는 person으로 classification된다.

"Image Captioning" Task 또한 image classifcation problem의 일종으로 볼 수 있다.
Image Captioning은 주어진 이미지에 해당하는 자연어 형태의 문장을 ouput으로 뱉길 원하는 task이다.
object detection과 마찬가지로 sequence of image classifcation이다.

처음 'man'을 고르고, 다음 단어로 'riding'을 고르고

문장을 만들기 위한 단어를 모두 고른뒤 종료한다.

Go를 위한 AI 시스템에서도 image classification이 사용된다.
input은 보드의 state에 postion이 포함된 image이고 output은 다음에 내가 어떤 돌을 놓아야 하는가?에 대한 답이다.
이러한 relatively unasumming problem에서 image classification은 컴퓨터 비전 task의 매우 매우 강력한 building block으로서 작동한다.

좋은 Image Classifier를 만들어야 할텐데
giant grid pixel of images와 label을 input으로 집어 넣어 어떠한 연산을 통해 cat이라고 뱉어낼지,
저 파이썬 함수안에 어떤 그러한 매직 블락을 작성해서 고양이를 잘 분류해낼 수 있을지는 분명하지 않다.
일단 가장 해볼만한 첫 접근은 우리의 지식을 활용해서 분류해보는 것이다.
지난시간에 이미지의 edge가 이미지에서 갖는 중요함에 대해서 배웠다.
우리는 고양이의 특징적인 귀나, 수염 등의 edge를 검출하고 이를 통해 판단하는 hard algorithm을 통해 이러한 문제에 대해서 접근 할 수도 있을 것이다.
이러한 방식은 어떠한 특정 corner case에 대해서 cat인지 일일히 코드로 적는 것이다.
그러나 고양이중에는 고양이 수염이 있는 고양이도 있을 것이고, 아닌 고양이도 있을 것이고,... 너무 많은 corner case가 존재한다.
게다가 우리는 심지어 은하를 분류하길 원한다. 모든 정보를 알고리즘에 포함시키는것은 매우 힘든일이다.
따라서 이러한 방법은 좋은 방법은 아니다.
우리가 원하는 것은 강건하며, 확장성이 있어야하고, 모든 human knowledge를 일일히 코드로 적는 일이 없어야한다.

우리는 이제 머신러닝이라는 접근을 하게 된다.
머신러닝의 아이디어는, 어떠한 object가 어떻게 생겼다 라는 human knowlege를 explicitly encode하기 보다는
data - driven approach이며, 알고리즘은 어떻게 이미지를 recognize해야하는지 데이터로부터 학습한다.
이러한 머신러닝 파이프라인의 첫 단계는
첫째로, 큰규모의 이미지 데이터셋을 모은다.
두번째로는 이미지에 알고리즘이 predict하길 원하는 레이블링 작업을 한다.
머신러닝 모델이 데이터로부터 extract한 statistical dependency를 통해
우리는 새로운 이미지로부터 classifier에 대해 평가를 할 수 있다.
여기에는 train과 predict라는 두가지 API가 있다.
train에는 image와 label를 input하면 머신러닝을 통해 statistical model을 return한다.
predict에서는 train을 통해 획득한 모델을 통해 new image에 대해 label을 내뱉는다.
아마도 바라옵건데, 만약에 은하를 분류하길 원한다면, 머신러닝 알고리즘 코드를 재작성할 필요 없이 은하에 대한 데이터를 모으면 되는 것이다. 데이터가 바뀌면 프로그램의 행동이 바뀌는 것이다.
이것이 image classification을 포함한 대부분의 classification에 대부분에 적용되는 패러다임이다.

가장 유명한 이미지 데이터셋인, MNIST 데이터셋이다 10개의 클래스이며, 28*28의 grayscale을 갖고 있다.
5만장의 이미지가 trainset, 만장의 이미지가 testset으로 구성되어 있다.
toy dataset처럼 보이지만 이전 강의에서 설명했듯 80년대부터 이러한 hand written data에 대해 실용적으로 매우 매우 유용했던 데이터셋이다. 또한 머신러닝 알고리즘의 발전에 큰 도움이 되어왔다.

MNIST 데이터셋은 때때로 컴퓨터비전계에서 "초파리"라고도 불린다.
생물학자들이 초파리를 가지고 가장 먼저 실험을 하듯이, 머신러닝 실험자들도 MNIST에 대해서 새로운 아이디어를 가장 먼저 실험해본다.
그러나 MNIST는 너무나 일반적이고 어떤 reasonable한 머신러닝 모델이기만 하면 너무나 좋은 성능이 나오기 때문에 MNIST에 대한 검증만으로는 충분하지 않다는 점을 명심해야 한다. 단순히 개념의 검증(PoC)용으로 사용해야 한다.

또 다른, 일반적으로 사용되는 데이터셋은 CIFAR 10이다. 역시 32*32 의 작은 사이즈이고, 그러나 grayscale이 아닌 color다. 그러나 label들이 분류하기 힘든편에 속하는 것들로 이루어져 있다.

확장된 CIFAR100도 있다.

지난 강의에서도 언급한, ImageNet이다. Image Classification에 대한 Gold Standard다. (논문을 쓰는데 ImageNet에 대한 결과가 없다면 반드시 reject될 것이다. 라고 농담삼아 언급) 매우 매우 중요한 벤치마크 데이터셋인 것이다. CIFAR10에 비하면 매우 큰 이미지 데이터셋이다.

ImageNet은 인터넷으로부터 다운로드 된 다양한 해상도의 이미지의 모음집인데, 256*256으로 Resize했다. (훈련때는 224*224로 Resize해서 훈련시키기도 한다.) label에 약간 noise가 있어서 , Performance metric으로 Top 5 Accuracy를 살피기도 한다. 가장 확신하는 5개의 카테고리중에 정답이 속해있느냐를 판단하는 성능 지표다.

ImageNet이 Object에 집중했다면 MIT Places는 이름처럼 scene type에 집중한 Data Set이다.

표에서 보면 알 수 있듯이, 시간이 지나면서 데이터셋의 크기는 점점 증가하는 경향이 있다.

그러나, 이와 반대로 각 카테고리에 20개의 이미지밖에 되지 않는 데이터셋인 Omniglot 데이터셋도 있는데, 오히려 모델이 robust하게 적은 수의 데이터에 대해서도 잘 작동하는지 확인하기 위해 사용된다.

처음으로 다뤄볼 Classifier는 Nearest Neighbor다
Learning이라는 말이 조금 무색하게, train 단계에서는 단지 데이터를 저장할 뿐이다. 어떠한 처리도 하지 않는다.
predict에서는 test image와 저장된 train data간에 거리 계산, 유사도 계산등을 통해 비교를 통해 label을 할당한다.

similarity를 계산하는 가장 대표적인 방법은 L1과 L2 distance다.
위의 사진은 4*4 픽셀 이미지를 가장한 간단한 L1 distance를 이용한 similarity계산이다.
맨하탄 거리라고도 불리는 L1 distance는 각 픽셀값의 차의 절댓값을 모두 더함으로써 similarity를 판단한다.
L1 distance는 간단하지만, distance metric이면 만족해야할 조건들
같은 이미지면 값이 distance가 0이고, triagle inequality와 같은 수학적 rule도 모두 만족하고 있다.

코드상으로 살펴보면, 말했듯 train단계에서는 단순히 input data를 저장하기만 하면 된다.

predict에서는 각 test image에 대해서 가장 가까운 train image를 찾고, nearest neighbor의 라벨을 할당한다.

그러나 Nearest Neighbor classifier에는 문제가 있다. 우리는 머신러닝 시스템을 배포할때, train은 길어도 괜찮을지 몰라도 predict가 빠르길 원한다. 그러나 오히려 반대인 상황이다.

위의 결과는 CIFAR10 데이터셋에 대해서 Nearest Neighbor를 적용한 결과이다.
좌측 테스트 이미지에 대해서 유사도가 높은 우측의 결과를 표현하고 있다.
초록색 박스가 맞춘것이고 빨간 박스가 맞추지 못한 것이다. L1 metric으로는 매우 유사한 이미지라고 판단하였지만 정답이 아닌것이 6개나 된다.

Decision Boundary 개념을 위한 2픽셀 이미지를 가정한 시각화이다.
각 x축과 y축은 픽셀의 intensity ( 0~255)를 표현한 것으로 생각하면된다. 각 점은 개별 train image를 나타내고 각각의 색깔은 서로 다른 카테고리에 할당된 것이다. 배경의 색은 새로운 test image가 들어오면 classify를 수행할 decision region space다.
그러나 동그라미 친 부분을 잘 살펴보면 이러한 decision boundary는 상당히 noisy한 것을 볼 수 있다. 단 한개의 outlier train data때문에 저러한 noise가 발생한 것이다. 그렇다면 decision boundary를 smooting하는 전략에는 어떠한 것들이 있을까?

첫번째로 가장 간단한 아이디어는, 더 많은 이웃을 사용하는 것이다.
가장 가까운 이웃의 카테고리를 직접 할당한것이 아니라 여러개의 이웃에 대해 majority vote방법을 통해 (다수결) 카테고리를 할당하게 된다. 이웃의 수를 k로 표현하고 k-Nearest Neighbors라고 부른다.

k=1일때와 k=3일때의 decision boundary의 비교이다. 같은 데이터셋에 대해서 decision boundary가 좀 더 smooth해진 것을 볼 수 있다.

또한 아웃라이어에 의해 결정되는 performance의 효과도 감소하였다.

그러나 K가 1 보다 크게 되면 tie가 발생할 수 있다. 그래서 어떠한 category로도 예측하지 못하는 경우가 생기고, 이러한 conflict를 해결하기 위한 휴리스틱한 방법을 강구해야한다.

이미지 유사도 비교를 위해 Nearest Neighbor를 사용할때, 지금 껏 비교해왔던 L1외에 L2 Metric을 사용할 수 있다.
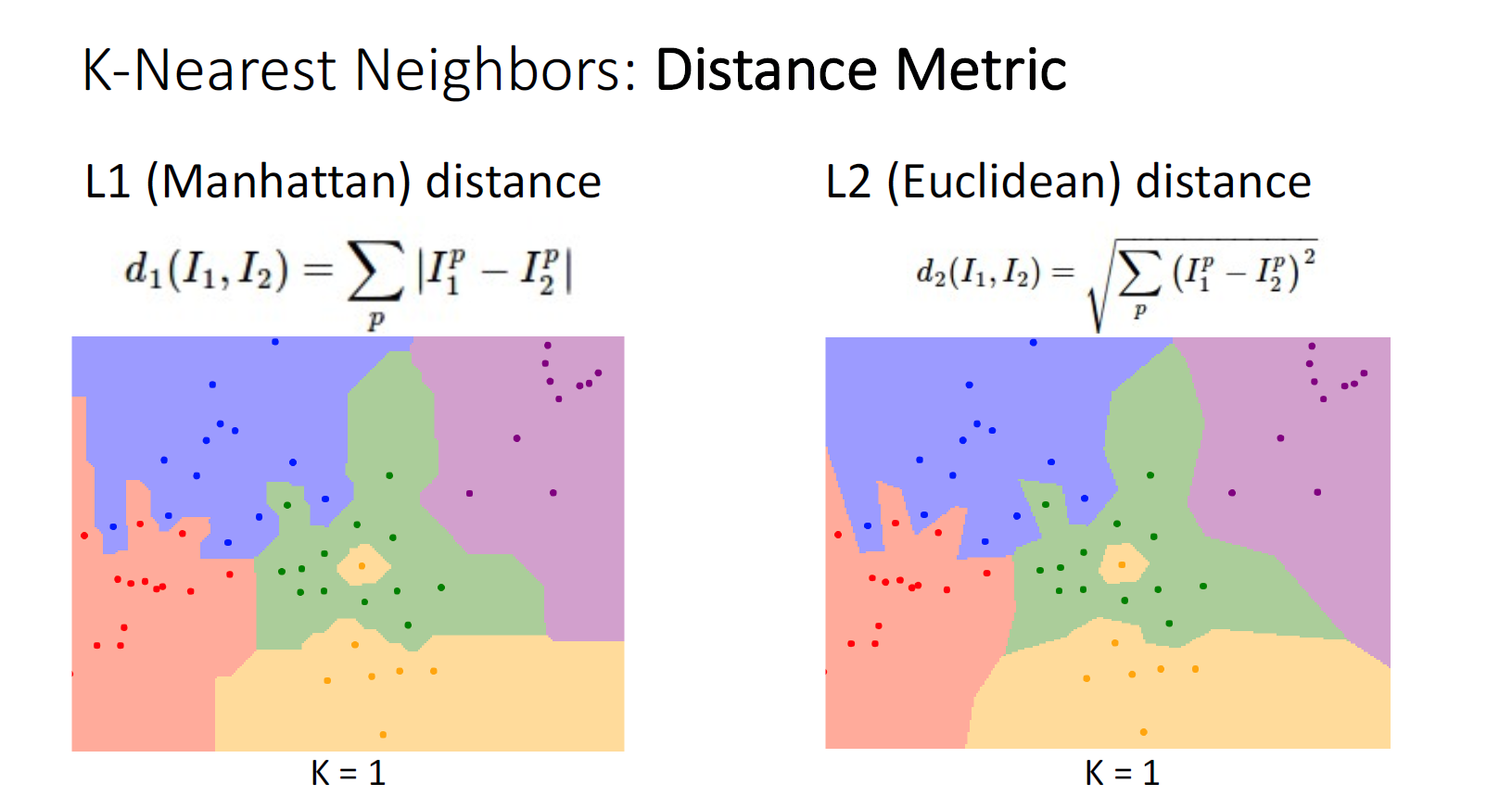
L1 metric의 경우 decision boundary는 linear하며 특히 horizontal, vertical, 45도의 각도를 자주 보이는 것을 알 수 있다.
L2 metric의 decision boundary의 경우 여전히 linear하지만 , 그 외의 다른 방향을 갖는 것을 알 수 있다.
그러나 아직 여전히 L1과 L2의 차이가 어떠한 semantic한 차이를 불러오는지에 대한 직관은 불명확하다.

distnace metric에 대한 적절한 선택으로 여러 적용이 가능하다.
한 예시는 knn retrieval이다.
실제로 arxiv-sanity라는 웹사이트에서는 논문에 대한 표절 검사를 tf-idf distance metric을 이용한 knn retrieval으로 진행하고, 매우 잘 동작한다.

K-NN을 적용할때에는 domain-knowlege와 잘 작동하는 K와 distance metric을 골라야한다. 이러
한 값들을 하이퍼 파라미터라고 한다. 이러한 하이퍼 파라미터의 선택은 problem-dependent한데, 어떠한 하이퍼 파라미터가 우리의 데이터와 task에 잘 작동하는지는 살펴봐야 할것이다.
이러한 하이퍼 파라미터 세팅에 대한 몇가지 전략이 있다.

첫번째 아이디어로는 train data의 accuracy가 가장 높은 하이퍼 파라미터를 선택하는 것이다.
그러나 이러한 접근은 절대 절대 하면 안된다. k-nn을 예시로 들면 간단히 k=1 이라고 하는 것과 같은데, k=1 인 knn classifier는 training data에 대해선 100%의 accuracy를 보이겠지만 이전 예시에서 보였듯 decision boundary를 smoothing 하기 위해 더 큰 k값을 채택해야 한다.
두번째 아이디어로는 training set과 test set의 두 요소로 분리하는 것이다. training set으로 학습을 시키고 test set에 대한 정확도를 본다. 첫번째 아이디어에 비해 unseen data에 대한 성능을 확인하는 것임으로 머신러닝의 목적에 부합한다.
그러나 이 접근의 문제는 hyper parameter 세팅에 있어 test set에 대해 적합한 하이퍼 파라미터를 고르게 됨으로써,
test set에 대한 cheeting을 하는 것과 같고, test set이 더이상 unseen data가 아니게 된다. 따라서 이 방법 역시 사용하면 안된다.
세번째 아이디어로는 train set과 validation set 그리고 test set 세가지 요소로 분리하는 것이다. 여기서 evaluation은 validation set을 통해서 진행하고 이를 통해 하이퍼 파라미터를 업데이트하면서 test set에 대한 unseen 상태를 유지해야 한다. test set을 절대 건들이면 안된다.

네번째 아이디어는 Cross-validation이다. 데이터셋을 fold라 불리는 chunk로 나누고 fold가 5개라면 알고리즘은 5번의 iteration을 돌게 된다. 학습하는 데이터량의 많고, validation하는 데이터가 다양해지기 때문에 더욱 generalize하기 좋다.
연산량이 매우 크기 때문에 적용하기 힘든 점도 있지만, 작은 데이터셋과 작은 모델에 대해서는 적용하면 좋을 것이다.

각 k값에 따른 cross-validation accuracy를 평가한 그래프이다. k=7에서 주어진 데이터에 가장 잘 작동하는것을 보인다.

kNN 알고리즘의 흥미로운 또 다른 특징중 하나는 Universal Approximation이다. KNN은 함수의 표현에 있어 어떠한 가정도 하지 않는다. 트레이닝 샘플이 무한대로 많아지면 어떠한 함수도 표현할 수 있다.
x의 픽셀값을 통해 y의 float를 예측하는 kNN regressor의 예시다. 파란색 그래프는 underlying true function이고 우리의 머신러닝 모델이 학습하기 원하는 tartget이다. 그러나 트레이닝 샘플이 5개 밖에 없는 상황에서의 Nearest Neighbor function은 각 샘플에 대한 한정적인 예측을 할 수 밖에 없다.



그러나 트레이닝 샘플을 증가시키면 증가시킬수록 underlying true function을 매우 잘 근사한다. 어쩌면 k-NN을 통해 모든 함수를 표현할 수 있으니 필요한 유일한 알고리즘일지도 모른다. 그러나 여기서 한가지 애로사항이 있다.

그 애로사항은 바로 Curse Of Dimensionality (차원의 저주) 이다.
지금까지의 예시는 1-dimension이었지만 만약 여러 특성이 존재하면 문제가 된다.
feature space의 dimension이 uniform하게 증가 할때, 같은 coverage를 유지하기 위해서는 데이터의 샘플이 지수적으로 필요하다.

만약 32*32해상도의 binary 픽셀을 가진 이미지라고 한다면 가능한 이미지의 경우의수는 10^308인데 이는 너무나도 큰 숫자이다. (관측가능한 우주의 소립자의 수가 10^97 정도라고 하니 얼마나 큰 수인지 짐작조차 안간다.) 그러나 실제로 우리는 binary 이미지를 다루는것이 아니라 0-255픽셀값을 갖는 real valued- RGB이미지를 다루게 된다.

KNN이 매우 nice한 것 같아 보였지만 앞서 언급한 머신러닝 모델의 목적에 부합하지 않는 점, 바로 test time이 너무 느리다는 것과 feature space를 cover하기 위한 data가 너무나 많이 필요하다는 점, 세번째로는 distance metric이 이미지의 의미론에 부합되지 않다는 점이다.
위의 사진을 보면 가장 좌측의 이미지와 우측 세개의 이미지는 서로 다른 이미지임에도 불구하고 각각의 L2 distance는 모두 같은 값을 보인다.
좋은 metric은 shifted image는 다른 이미지들 보다 Original image와 거리가 가깝다고 말해야 할 것이다.

하지만 ConvNet을 통해 구한 feature vector를 통해 K-NN retrieval을 수해하면 비교적 유사한 이미지를 잘 찾을 수 있다고 한다. k-NN은 raw image pixel에 대해서는 거의 사용되지 않는다.


이번 강의의 요약이다.

다음 강의는 Linear Classifier에 대해서 다룬다.
'기초 노트 > EECS 498-007 (ComputerVision)' 카테고리의 다른 글
| EECS 498-007 Lecture 05 : Neural Networks 정리 (0) | 2024.03.17 |
|---|---|
| EECS 498-007 Lecture 04 : Optimization 정리 (0) | 2024.03.15 |
| EECS 498-007 Lecture3 : Linear Classifiers 정리 (0) | 2024.03.04 |
| EECS 498-007 Lecture1 : Introduction (0) | 2024.02.21 |
| EECS 498-007 : Deep Learning for Computer Vision 소개 (0) | 2024.02.14 |


