
플로라도의 data workout
EECS 498-007 Lecture 8: CNN Architectures 정리 본문
EECS 498-007 Lecture 8: CNN Architectures 정리
플로라도 2024. 4. 2. 01:05
이번시간에는 CNN의 아키텍쳐에 대해서 다뤄본다.
게시물 작성 시점인 2024년 기준으로
강의 내용에서 소개된 모델 이외에도, 더욱 효율적이고 정확도면에서 우수한 모델들이 다수 발표되었고(2019년, EfficientNet)
2020년 VisionTransformer의 발표 이후에는 ViT계열 모델들이 매우 대두되던 시기가 있었다.
(2020년; DETR, 2021년 ; SwinTransformer)
하지만 Transformer계열 모델들은 리소스가 크고 학습양을 상당히 필요로 하기 때문에, 이후 다시 CNN계열로 Transformer계열을 잡을 수 있지 않을까? 하는 생각으로 CNN계열 모델이 다시금 연구되었다. (ConvNext, ResNest)
하지만 모든 CNN계열의 아키텍쳐들은 이전 모델들의 아이디어를 기반으로 조금 씩 더 발전된 양상을 보임으로 꼭 알아야할 부분이다.

지금까지 살펴본 Convolutional Neural Networks(CNN)의 구성요소들이다.
결국 어떻게 이 요소들을 조합해 모델을 만들어야 하는지가 문제가 되겠다.
그러기 위해서, 이전 모델들에 대하여 역사적인 맥락을 살펴보려고 한다.

이 주제에 관해서 논의할때는 ImageNet Classification Challenge를 살펴보는 것이 좋은 방법이다.
ImageNet Classification Challenge는 컴퓨터 비전의 발전을 견인해왔다.
(ImageNet Classification Challenge는 Large Scale Visual Recognition Challenge (ILSVRC) 라고 부른다.)
지난 1,2강에서 이야기했던 ImageNet dataset에 관해서 떠올려보면, 총 120만장에 1,000여개의 클래스로 구성된 아주 아주 큰 데이터셋임을 안다.
2010년 , 2011년 ILSVRC의 첫 두 해 우승자는 Neural Network 디자인이 아니었고, 이전에 살펴보았든 손수 만든 feature와 Linear Classifier를 가장위에 배치해 사용한 형태였다.

2012년에는 여러번 언급했듯, AlexNet의 등장으로 NerualNetwork가 컴퓨터 비전계의 메인스트림으로 자리잡게 되었다.

지금은 그다지 Deep한 Network가 아닐지 모르지만, AlexNet은 5개의 층으로 구성된 Convolutional layer와 Max pooling 이후 3개 층의 FC layer와 nonliearity로 ReLU함수를 사용하였다.
AlexNet에서 ReLU함수를 처음으로 사용하기 시작하였다.
지금은 그다지 사용하지 않는 'Local response normalization'이라는 방법도 사용하였고 (지금은 BatchNorm으로 완전히 대체 되었다.
또한 당시의 그래픽카드는 GTX580이 가장 좋은 하드웨어 였으나 단지 VRAM이 3GB였기 때문에 AlexNet을 학습시키려고 두대를 병렬구성하였다고 한다. 그래픽카드를 병렬 구성하는 방법은 지금도 널리 쓰이는 방법이다.

실제로 논문의 그림을 보면 227x227의 input으로 부터 두개의 위아래 chunk로 나뉘는 모습을 볼 수 있다.

AlexNet의 논문의 인용수의 추이를 보여주는 차트이다. 2012년 발표 이후에 인용수는 지수적으로 증가하는 모습을 보인다. 약 46,000회 이상 인용되었다.

다른 과학 분야의 논문들의 인용수를 가져왔는데, 다윈의 '종의 기원'이 50,000회, 정보이론의 기원의 된 샤넌의 논문이 69,351회 등인 것을 보면 사실 인용수 자체가 그 중요도를 의미한다고 볼 수는 없지만,
AlexNet이 컴퓨터 비전 영역뿐만 아니라 데이터 사이언스의 여러 분야에서도 발전으로써 널리 중요하게 인식된다는 점은 주목할만 하다.

AlexNet 아키텍쳐의 구성 요소를 살펴보자. 첫번째 레이어인 Convolution layer를 conv1으로 표기하였다.
RGB 3채널의 hieght,width가 각 227인 이미지를 input으로 받게 된다.
레이어의 하이퍼 파라미터로는 커널사이즈 11, stride 4 ,pad2 그리고 필터의 갯수가 64임으로

#Num output channel은 conv1 레이어의 필터 갯수와 같고

레이어를 통과 한 이후의 spatial size는 (W-K+2P)/S+1에 의해 227에서 56으로 줄게된다. (W= width, K=kernel size, P = paading size, S = stride)

이때 output tensor의 총 요소의 갯수는 CxHxW인 64*56*56 = 200,704개가 되고
32비트 IEEE754 부동소수점 표현방식에 의해 각 요소당 4바이트의 길이를 갖게 된다.
따라서 output tensor가 차지하는 메모리의 크기는 200,704 * 4 / 1024 = 784KB이다.

여기서 가중치인 필터,커널의 shape은 필터의 spatial size인 11x11에 input tensor의 채널수를 고려하여 3을 곱하고, 필터의 갯수이자 output tensor의 channel수인 64를 곱한 64x3x11x11 의 4D tensor이다.
또한 필터마다 bias가 존재함으로 bias는 필터의 갯수인 64개가 존재한다.
따라서 전체 가중치 요소의 갯수는 64x3x11x11 + 64 - 23,296개이다.

부동소수점 연산(Floating point Operation ; FLOP)을 계산하는 것은 오늘날에도 매우 중요하다.
부동소수점 연산은 multiply+adds라는 단일의 연산 처리 방식을 사용 한다고 하는데
따라서 output요소의 갯수와 각 요소당 필요한 연산의 갯수를 곱하면 전체 FLOP을 알 수 있다.
따라서 (64x56x56) x (3x11x11) = 200,704x 363 = 72,855,552 FLOPs
conv1에 필요한 연산량은 약 73M에 해당하는 것을 알 수 있다.

convolutional layer 이후에는 활성화 함수인 ReLU가 뒤따르고, 그 이후 pooling layer가 뒤따르게 된다.

첫번째 pooling layer인 pool1의 경우 max pooling이 사용 되었고, max pooling을 통과한 output tensor의 shape과 메모리 사용량은 동일한 방식으로 계산할 수 있다.

pooling의 경우 학습가능한 파라미터가 없으며

max pooling의 경우 max연산은, 3x3 그리드에 대해서 총 9번의 연산을 수행하게 된다.
(3x3은 곧 pooling layer의 kernel size와도 같다.)
따라서 output tensor의 요소 하나는 3x3의 그리드로부터 생성되고, 각 그리드는 9번의 연산을 포함함으로
pooling layer의 연산량은 위와 같게된다.
73MFLOPs인 convolutional layer와 비교하면 매우 적은 연산량이기 때문에 pooling layer의 연산량은 이를 생략하여 적기도 한다.
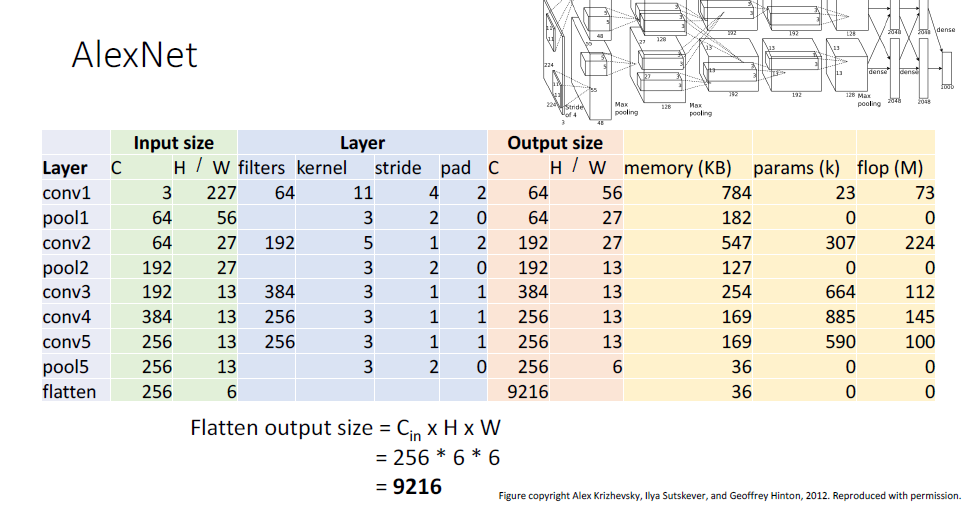
이어지는 conv2 pool2 conv3 conv4 con5 pool5도 동일하게 계산할 수 있고,
마지막 pool5를 통과한 output tensor를 1D shape로 펴기 위한 flatten층은 output tensor의 shape의 요솟값들을 모두 곱한
9216차원의 1D tensor의 형태를 취하게 되고

9216차원의 1D tensor를 fc6 레이어에 통과시키는데 (이때부터는 classifier의 영역이다.)
FC layer의 파라미터 수는 input Channel수와 output Channel수의 곱과, 그리고 Channel수 별로 bias term이 하나씩 더해짐으로 9,216*4,096+4,096 = 37,725,832이고
FLOPs의 경우 output tensor의 요소당 곱연산이 진행됨으로9216*4096 = 37,748,736이다.

AlexNet의 경우 ImageNet dataset을 사용하여 총 1000개의 class를 분류하기 위해 제작되었음으로 마지막 fc8에서의 output은 1000차원의 1d tensor이고, 나머지 값들을 채워넣으면 위와 같다.

그래서 지금까지 각 conv layer에서 하이퍼 파라미터가 가지는 의미와, 그에 따르는 메모리 사용량, 파라미터수, 필요한 연산량을 알아보았다.
그런데 이러한 NeuralNet의 디자인을 어떻게 했다는걸까?
아마도 AlexNet을 포함한 많은 NeuralNet의 디자인에는 수많은 시행착오가 있었을 것이다.
AlexNet의 정확한 구성을 어떻게 달성했는가에 대해서는 밝혀지지 않은부분도 있지만
아무튼 실전에서 매우 잘 동작했다고 한다.
사람들은 NeuralNet을 디자인할때 수많은 시행착오 끝에 찾은 적절한 하이퍼 파라미터를 사용했는데,
새로운 아키텍쳐를 디자인할 때 각 layer에 대한 필터 사이즈나, stride와 같은 전반적인 모든 부분에 대해서 시행착오를 줄이고 싶어 했다.

사람들은 AlexNet뿐만 아니라 NeuralNet 공통으로 적용되는 몇가지 주요한 특징을 잡아냈는데
우선 한가지는 앞서말한대로 Pooling Layer는 부동소수점 연산이 거의 필요로 하지 않는다는 점이었고,

AlexNet의 레이어별 메모리 사용량, 파라미터수, FLOPs의 표를 막대 그래프로 시각화 하여 봤을때
첫번째 차트, 메모리 사용량은 초반부의 convolutional layer를 동작하는데 대부분 사용되는 것을 알 수 있다.
초기 conv layer에는 공간적 정보가 보존된 input tensor가 들어가기 때문이다.
두번째, 파라미터 차트를 보면 fc6에서 우뚝 솟은 모습인데
생각해보면 마지막 conv5의 output은 256x6x6이고 이를 9216차원으로 flatten시킨 뒤
fc6는 이러한 9216차원의 긴 벡터를 4096차원의 벡터로 만드는 연산이다.
이에 필요한 FC layer의 파라미터 수는 9216x4096 = 37,749M이며 conv layer에 비해 압도적으로 많게된다.
또 세번째 차트를 보면, fc layer들은 conv layer에 비해 연산량이 매우 적게 든다는 점을 알 수 있다.
이러한 특징들은 AlexNet에 국한된 것이 아니며 이후 더 효율적인 아키텍쳐를 디자인할때 명심해야되는 부분이 되었다.

AlexNet이후 ILSVRC의 우승자는 모두 NeuralNet이 차지하게 된다.
2013년의 우승자는 AlexNet과 동일한 8layer를 사용한 ZFNet이라고 불리는 것인데,

ZFNet은 AlexNet을 단순히 조금 더 크게 만든 형태라고 말할 수 있을것 같다.
더 많은 시행과 착오는 더 줄인셈이다.
CONV1을 11x11, stride 4 디자인에서 7x7 ,stride 2 의 디자인으로 바꾸었다.
AlexNet대비 CONV1을 통과한 이후 더 많은 공간적 정보를 갖고 훨씬 더 많은 수의 필터를 사용하였다. (384,384,256 -> 512,1024,512)
따라서 AlexNet 대비 파라미터 수가 훨씬 많고 연산량도 더욱 많게되었다.
AlexNet에서 ZFNet으로 오면서 생각해볼 점은,
더 큰 네트워크가 더 잘 작동했다는 점인데, 이 당시에는 네트워크를 크게 만들거나 작게 만드는 것에대 한 어떤 원칙적인 기준이 존재하지는 않았다. 대신 각 개별 레이어의 하이퍼파라미터를 어떻게 튜닝할지에 대한 시도들이 있었다.

이후 발표된 2014년, ImageNet Challenge의 우승자 VGG라고 불리는 네트워크 아키텍쳐는 매우 흥미롭다.

AlexNet과 ZFNet같은 경우 레이어의 구성 자체는 어떤 특별한 목적을 위한 방식(Adhoc-way)이었지만, 각 개별 레이어의 하이퍼 파라미터는 독립적인 시행착오를 거쳐 완성된 것이었고, 이러한 이유로 네트워크 전반의 크기를 키우거나 줄이는 것이 무척 어려웠으나
2014년 VGG 이후로 오면서, 네트워크 전체 디자인에 대해 어떠한 원칙을 세워지게 되는데,
특히 VGG 같은경우 디자인 원칙은 매우 간단하고 명쾌한데, 단순히 모든 Conv는 3x3 필터, stride1, pad1을 사용하고
모든 max pool은 2x2 , stride2를 사용하고, pooling이후에는 channel 수를 두배로만 증가시키는 방식을 선택했다.

AlexNet에서는 Conv layer가 5개였었는데, VGGNet에서는 Conv "Stage" 라고 불리는 것이 5개로 구성되었다.
Conv Stage는 어떤 하나의 블럭단위라 볼 수 있는데, 여러개의 Conv layer로 구성한 것이다.
[conv-conv-pool] 이 하나의 스테이지, 블럭이 되어 이것이 5번 반복된다.
(VGG-19에서는 stage4,5에 conv layer가 하나씩 더 추가된다.)
VGG Net은 왜 이러한 디자인으로 설계되었을까?

우선 첫째로 단지 3x3필터 사이즈만 갖는 convolution layer로 구성한것이 어떤 의미를 가지는가에 대해서 살펴보자.
AlexNet과 ZFNet에서는 커널 사이즈가 하이퍼 파라미터로서, 사람들이 각 레이어 마다의 커널 사이즈를 개별적으로 조정하여 사용하는데,
여기서 두가지 옵션을 비교해보자.

첫번째 옵션은 5x5 커널 사이즈를 가지는 Conv이고 두번째 옵션은 3x3 커널사이즈를 갖는 Conv를 두개 쌓은 것이다.
각각의 파라미터 수와 연산량은 $25C^2$, $18C^2$ 그리고 FLOPs는 output tensor의 요소의 개수* 요소당 연산 횟수임으로
$25C^2HW$ , $18C^2HW$이다.

여기서 흥미로운 점은, 두가지 옵션 모두 output tensor의 한 요소가 바라보는 input의 영역인 receptive field가 동일하다는 점이다.
따라서 receptive field의 관점에서, 옵션2가 동일한 영역을 고려하는데 더 적은 파라미터수가 듬은 물론,
활성화함수 ReLU등이 최대 두번까지 포함될 수 있기 때문에 더 많은 표현이 가능하다.

VGG 디자인의 두번째 요소는 모든 맥스 풀링은 2x2, stride2를 사용하였고, 풀링 이후에 채널수는 2배로 증가시켰다는 점이다. 이 원칙이 어떻게 적용되는지 두개의 스테이지를 통해 비교해보자.
첫번째 stage와 두번째 stage의 연산을 비교해보면, spatial size는 pooling에 의해 절반씩 줄어들고 (2H-> H) 채널은 (C-2C) 두배가 되면서 메모리는 절반, 파라미터수는 4배가되지만 FLOPs는 동일한 것을 알 수 있다.
이러한 두가지 원칙은 VGG이후에 발표된 많은 아키텍쳐에 계속 적용되었다.
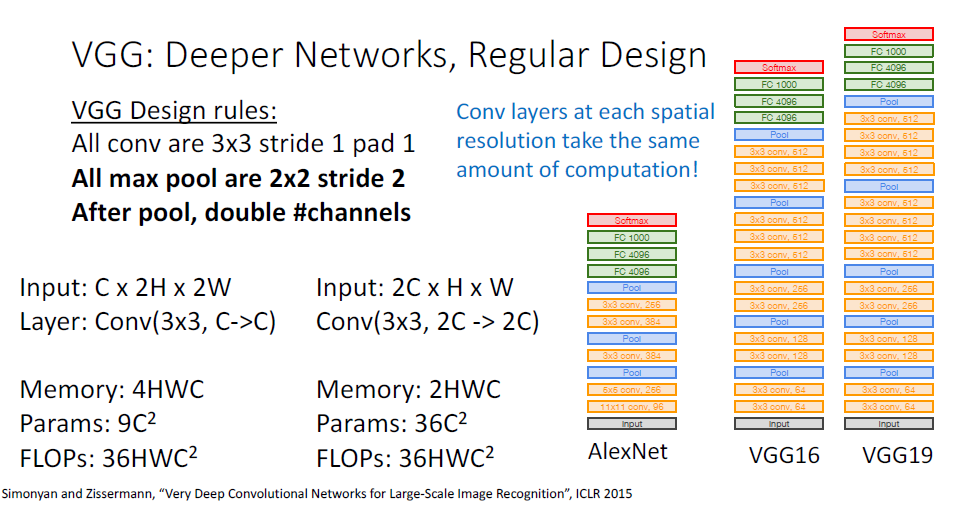
첫번째 stage와 두번째 stage의 연산을 비교해보면, spatial size는 pooling에 의해 절반씩 줄어들고 (2H-> H) 채널은 (C-2C) 두배가 되면서 메모리는 절반, 파라미터수는 4배가되지만 FLOPs는 동일한 것을 알 수 있다.
이러한 두가지 원칙은 VGG이후에 발표된 많은 아키텍쳐에 계속 적용되었다.

AlexNet과 VGG-16의 면면을 비교해보면 위와 같다. VGG-16는 AlexNet에 비하면 매우 큰 네트워크이다.

사실 2014년 ImageNet Challenge의 우승자는 Google에서 발표한 GoogLeNet이라는 네트워크인데,
Error rate를 6.7퍼까지 줄이는데 성공했다.
Google이 가진 많은 컴퓨팅 리소스를 생각하면 VGG를 발표한 대학원생과 연구진들은 굉장히 대단한 성과라고 생각되고, 컴퓨팅 리소스를 비교하면 VGG가 가지는 의의를 이해할 수 있다.
GoogLeNet이라는 이름이 굉장히 특이한데, 이는 초창기 모델중 하나인 LeNet을 만든 Yann LeCun을 오마주해서 결정했다고 한다.

GoogLeNet이 집중한것은 효율성이다. 구글 팀은 모바일에서도 적용 가능한 좀더 효율적인 CNN 아키텍쳐를 원했고,
연산량이 적으면서도 동등한 성능을 내기를 원했다.

GoogLeNet은 두가지 혁신적인 아이디어를 제공 했는데,
하나는 Stem network라고 불리는
공격적으로 downsampling한 네트워크의 초기 부분이 있다.
AlexNet과 VGGNet에서 초기 conv에 대부분의 연산량이 집중된 것을 떠올려보면,
GoogLeNet에서는 이를 피하기 위해서매우 가파른 downsampling을 적용하고 light weight를 채용했다.
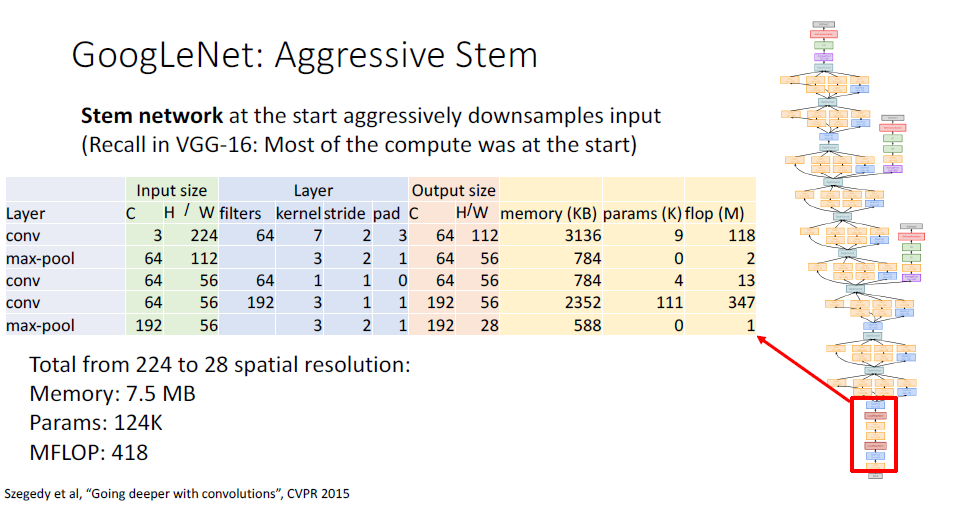
Stem network의 상세사항은 다음과 같다.

동일한 정도의 spatial size로 줄이는 연산량을 VGGNet과 비교해보면 거의 18배나 차이가 나게된다.

두번째로 GoogLeNet의 특징적인 점은 Inception 모듈이다.
당시 레이어를 깊게 쌓은데서 Inception이라는 이름을 붙인것 같다.
VGGNet에서 conv-conv-pool 이라는 Conv Stage를 여러번 반복해서 활용한 것 처럼
GoogLeNet에서는 Inception module이라는 Local Network를 네트워크 전반에 걸쳐 반복적으로 활용하게 된다.

VGGNet과 동일하게 커널 사이즈를 하이퍼 파라미터로 고려하는것을 피하고 싶어했는데
VGGNet에서는 이를 3x3의 커널의 필터만을 사용하였다면
GoogLeNet에서는 다른 접근 방식으로
아예 여러 사이즈의 커널 사이즈를 전부 활용하는 방식을 채택했다.
Inception모듈에는 4개의 parallel한 branch가 존재한다. 서로 다른 필터의 사이즈의 conv에는 1x1 conv가 추가적으로 쌓이게 되어 채널수를 조정하는 역할을 맡게된다.
마찬가지로 이러한 정해진 Inception 모듈을 사용함으로써 각각의 커널 사이즈에 대해서 튜닝할 필요는 없게된다.

GoogLeNet의 또다른 혁신은 네트워크의 제일 끝단에 사용된 Global Average Pooling이다.
GoogLeNet이전의 네트워크들을 다시 복기해보면, Classifier 부분의 FC layer에 대부분의 파라미터수가 집중되었었는데, GoogLeNet는 연산의 효율을 위해서 FC layer를 Global Average Pooling으로 대체했다.
FC layer는 conv layer를 통과한 마지막 tensor를 하나의 거대한 벡터로 flatten시킨 뒤 이를 다루게 되었는데
GoogLeNet에서는 공간적 정보를 파괴하여 다루는 것은 동일하지만 flatten을 시키는 것이 아니라 마지막 tensor에 대해 동일한 shape를 받아 Global Average Pooling을 처리하고 ,마지막 output tensor의 spatial size는 7x7이고 채널수는 1024인데, 7x7그리드에 대한 평균값을 뱉어냄으로서 각 그리드당 하나의 값으로, 1024차원에 해당하는 정보만을 남기게 된다.
Global Average Pooling은 학습가능한 파라미터가 없고, output이 1024개의 요소만을 갖기 때문에 연산량이 거의 없다시피 하게 되고, Global Average Pooling을 통과한 결과물을 FC layer의 input으로 활용하여 다음 layer의 파라미터수는 마찬가지로 ImageNet 데이터셋에 맞추어 1,000개의 클래스를 분류해야 함으로, 1024x1000이 되게 된다.

마지막으로 GoogLeNet의 흥미로운 점 또 한가지는 Auxiliary Classifiers(보조 분류기)이다.
GoogLeNet은 BatchNormalization이 발표되기 이전에 발표된 아키텍쳐라서 당시에는 10 layer가 넘는 깊은 아키텍쳐를 학습시키기 너무 어려워서 GoogLeNe에서는 Auxiliary Global Average Pooling을 사용하게 되었다.
일반적인 최종단계의 Classifier에서 class score를 얻는것 뿐만 아니라, Auxiliary Classifier부분에서 중간단계의 class score 2개를 추가로 얻어, 총 3개의 class score를 다루었다.
Auxiliary Classifier는 동일하게 loss를 계산하고, backprop을 진행하는 방식이어서 gradient가 좀 더 효율적으로 전파될 수 있도록 하였다. 진행 자체는 전체 네트워크의 수렴을 위해서 이전에 학습되어 수렴된 layer를 이용하기 위함이었다.
네트워크를 학습시키고 수렴시키기 위해서 굉장히 다루기 힘든 네트워크 구조의 아이디어와 기법을 사용한 모습이다.

다행히 2015년이 되었다. (NeuralNet에 아주 혁명적인 해이다.)
사람들은 BatchNormalization을 통해서 이러한 기법 없이도 VGG와 GoogLeNet을 스크래치부터 효율적으로 학습시킬 수 있게 되었다.
그뿐만아니라 2015년의 ImageNet Challenge의 우승자 ResNet, Residual Network도 발표되었다. ResNet은 NeuralNet 전반에 걸쳐 매우 혁신적이 중요한 아키텍쳐 디자인 아이디어이다.
Error rate가 3.6%로 거의 절반이나 줄이게 된 것뿐만 아니라, 152layer라는 매우 깊은 네트워크를 쌓게되었다.

우리는 2015년 BatchNorm을 갖게되고나서, 10층 이상의 레이어도 학습시킬 수 있게 되었는데, 레이어를 더 깊게 쌓으면 무슨 일이 벌어질까?

그래프에서 보는 것처럼 더 깊은 네트워크가 얕은 네트워크보다 성능이 더 좋지 않은 모습을 보인다
(56-layer가 20-layer보다 Test error가 더 높다.)
사람들은 이러한 현상을 보고 처음에 생각하기를, 더 깊은 네트워크는 트레인 데이터에 오버피팅 될 수 있기 떄문에 그런게 아닐까라고 추측했지만,

Training Error또한 56-layer가 20-layer보다 더 높은 모습을 보이면서, 이는 단순히 trainingset에 오버피팅된 것이 아니라
더 깊은 네트워크임에도 불구하고. underfitting상태에 빠진 것을 알게 되었다.

근데 생각해보면 더 깊은 네트워크라는 것은, 얕은 네트워크를 충분히 카피하고도 추가적인 표현력이 있을 것이라고 기대되는 부분이 있다. 예를 들면 얕은 모델의 네트워크 전부를 그대로 카피하고 나머지 레이어를 항등함수(identitiy function)으로 학습한다면 동일한 형태의 네트워크일테니 말이다.
따라서 더 깊은 모델이 최소 얕은 모델만큼의 성능이 보장되어야한다는 생각이 있는데, 이러한 언더피팅의 이유에 관해서
"Optimization"이 제대로 되지 않은 문제라고 가설을 세우기 시작했다. 레이어가 더 깊어질수록 네트워크 전체를 최적화시키기 어렵고, 특별히 얕은 모델을 모사하기위해서 identity function을 학습하는 것 자체가 어렵다는 것이다.

그래서 이러한 "Optimization" 문제에 대한 해결책으로, 추가적인 레이어가 identtity function으로 학습이 용이하도록 네트워크의 구조를 변화시키게 되는데,

그것이 바로 "Residual Networks"이다. Residual Network에서는 기존 "Plain" Block형태에서는 conv(relu)-conv- 형식으로 레이어가 쌓여져 나갔다면, "Residual" Block형태에서는 conv(relu)- conv에 원래의 input 정보 x가 더해진 형태가 다시한번 relu를 통과하여 다음 블락으로 전달되게 된다.
이때 레이어의 연산을 $F$라고 하고, 블럭 전체의 연산을 $H$라고 하면, Residual Block에서는 다음 레이어로 전달되는 정보 $H(x)$는 ,$H(x) = F(x) + x$로 전달되게 되는 것이다.
이때 원래의 input정보 "x"가 전달되는 경로를 특별히 shortcut, 혹은 연결관계를 skip connection이라고 부르며
Residual Networks이후의 딥러닝 아키텍쳐에 매우 매우 중요한 역할을 한다는 것을 강조한다.

이러한 추가적인 $x$를 흘려주는 shortcut의 아이디어는 네트워크(블럭)가 어떻게하면 identity function을 잘 학습할 수 있을까?에 대한 물음에 대한 답으로 출발하였다. 만약 블럭의 네트워크 전체가 identity function으로 학습하길 원한다면, $F$의 가중치들은 모두 0으로 초기화되고 단순히 $H(x)= F(x)+x = x$가 되어 identity function이 달성이 쉬워질 것이라는 이야기다.
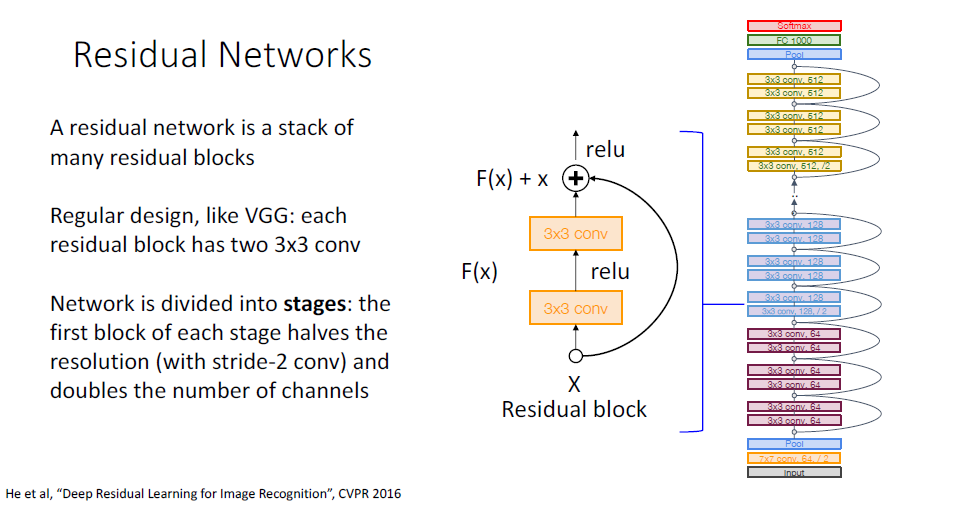
기존의 block에 shortuct을 추가한 "Residual" Block을 활용한 ResNet은 이전 VGG처럼 이러한 Residual Block을 수없이 쌓는 형태로 출발하게 된다.
VGG의 디자인 원칙처럼 3x3 conv를 사용하여 block을 구성하였고, block내의 첫번째 conv에서는 spatial size를 절반으로 줄이는 역할을, 두번째 conv는 channel수를 두배로 늘리는 역할을 하는 것으로 디자인 되었다.

또한 ResNet은 이전 GoogLeNet처럼 stem network를 활용하였다.
Residual Block을 적용하기 전에 conv와 max-pool로 input $x$의 spatial size를 4배줄이게된다.

또 전체 네트워크의 마지막 단에서는 GoogLeNet처럼 Classifier의 부분에 fc layer여러 층을 쌓은 것이 아니라
global average pooling을 활용하여 단 한차례의 1000개의 클래스에 대한 확률을 표현하기 위한 단일의 fc layer만을 사용용하여 연산량을 크게 줄이게 되었다.

ResNet은 VGG와 GoogLeNet의 디자인 원칙을 물려받았고, ResNet-18의 아키텍쳐는 위와 같다.

ResNet-18과 스테이지별 conv레이어의 갯수를 달리한 ResNet-34버전을 비교해보면 다음과 같다.

ResNet-34는 VGG-16대비 더 우수한 error rate를 보이면서도, 연산량은 더욱 적게되었다.

ResNet은 VGG의 3x3필터의 원칙을 차용하긴 했지만 블럭 디자인을 약간 수정한 버전도 사용하게 되었다.

ResNet에서 일반적으로 활용하는 Basic Block은 3x3 conv 사이에 ReLU와 BatchNorm이 포함된 일반적인 형태라고 볼 수 있고, conv layer의 FLOPs만 계산하면 $18HWC^2$이 되게 된다.

약간의 수정을 가한 "Bottleneck" Blcok은 , 첫 conv와 마지막 conv가 1x1 conv가 사용되었다.
첫 conv1는 채널수 4C->C로 줄이고, conv3는 채널수 C-> 4C로 늘이는 역할을 한다.

이 둘의 연산량을 비교하면 Bottleneck design이 더 적게드는 것을 알 수 있다.
이렇게 3개의 conv를 쌓은 형태로 non-liniearity를 더 잘 표현할 수 있게 됨으로
Bottleneck의 활용은 레이어를 깊게 쌓을때, 연산량을 크게 증가시키지 않으면서도 다양한 함수의 표현을 가능하게 하는 방법이다.

ResNet-18과 ResNet-34버전에서는 BasicBlock만을 활용하여 네트워크를 구성하였고

ResNet-50버전은 BasicBlock을 전부 BottleneckBlock으로 전부 교체하여 사용하였다. 이를 ResNet-34와 비교해보면 GFLOP이 큰 차이가 없음에도 불구하고, 층 자체가 더욱 깊어지고, error rate역시 더 나아진 모습이다.
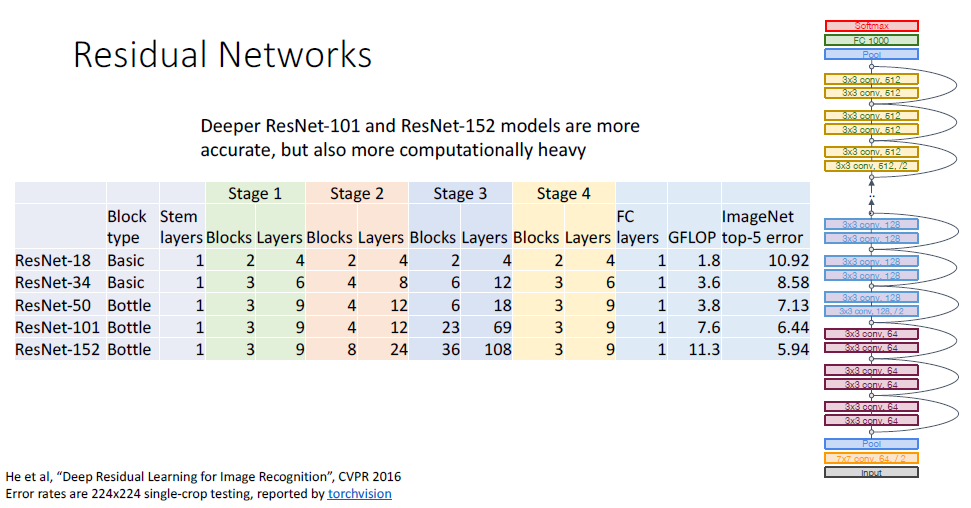
이 외에도 ResNet-101, ResNet-152가 있는데 동일하게 Bottleneck을 사용하였고, 드디어 더 깊은층이 더 나은 성능을 보이게 되었다.!

이전의 컴퓨터비전의 대회들에서는 각 대회마다 우승 모델이 각기 달리 존재했었는데 2015년 ResNet은 판도를 바꾸었다.
모든 분야의 컴퓨터 비전 Challenge에서 압도적인 차이로 우승을 휩쓸었다.

ResNet에서 또 다른 아이디어로는 블럭 디자인을 변경하는 시도들이 있었는데, Conv, BatchNorm과 ReLU의 순서를 바뀌어보는 것이었고

조금 더 나은 정확도를 보여주는 경우도 있었으나 실제로 그렇게 많이 사용되지는 않고있다.

지금까지 배운 아키텍쳐의 error rate와 연산량을 알아볼 수 있는 그래프이다. ResNet에 인셉션 모듈을 더한 Inception-v4가 더 나은 정확도를 보이고 있다.
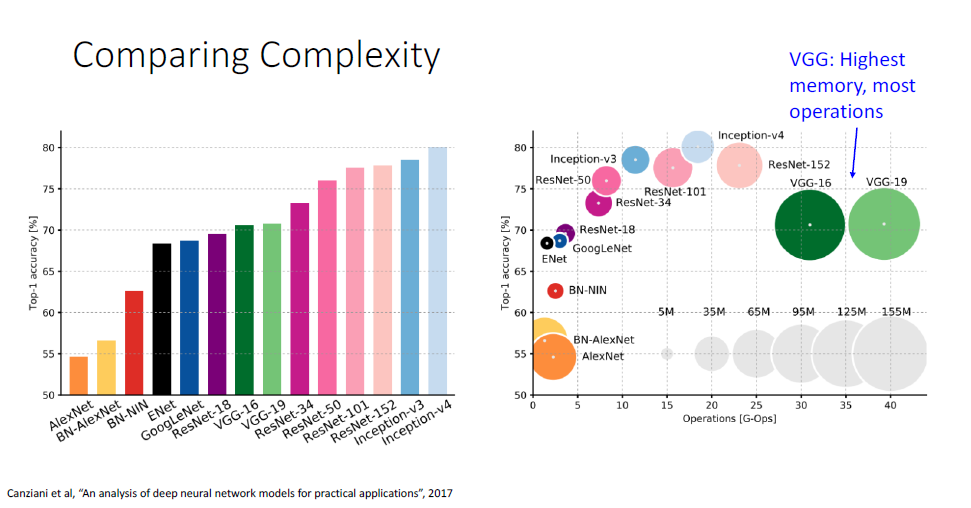
VGG의 경우 엄청난 연산량과 메모리 사용량을 가지는데 비해 가장 높은 정확도를 보이진 않는다.
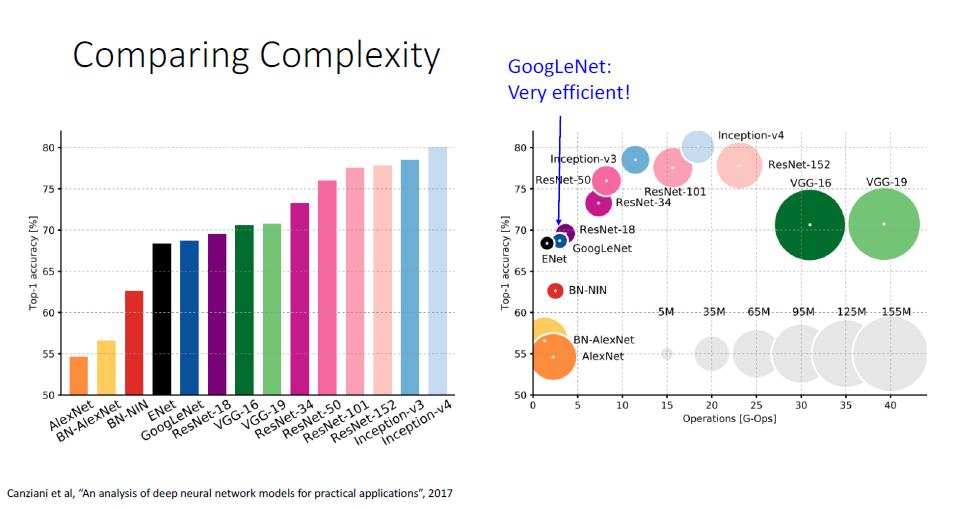
구글넷은 높은 정확도는 아니지만 압도적인 효율성을 자랑한다.
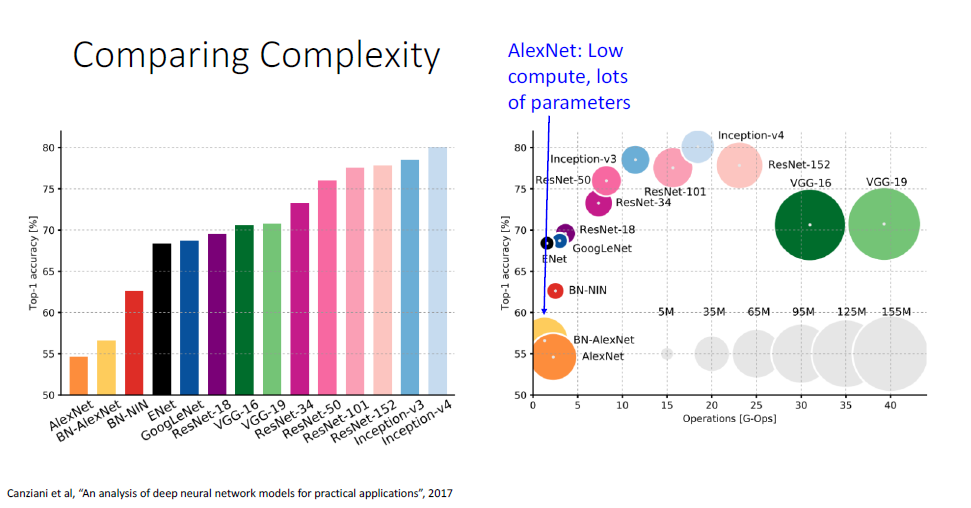
가쟝 초기단계인 AlexNet은 연산량은 적지만 파라미터의 갯수가 매우 많다.

ReNet은 간단한 디자인 구조로, 효율성과 정확도를 모두 챙겼다.

2015년 BatchNorm과 ResNet이후 2016년은 혁신적인 발표가 있던것은 아니었고

2016년의 우승자는 캐글에서도 많이 보이는것 처럼, 단순히 모델 앙상블한 것이어서 특별히 크게 새로울 것은 없었다.



하나의 parallel block이 새로운 채널 $c$에 해당하게 되고

이차방정식을 풀어보면
어떤 네트워크 구조의 디자인에 관한 또 다른 관점을 제시한다는 것이다.
이전까지는 채널수를 조정하는 것이 주요 요소 였다면, 이제는 parallel pathway의 수를 조절하는 것이 그 방법을 대신할 수도 있게 되었다.





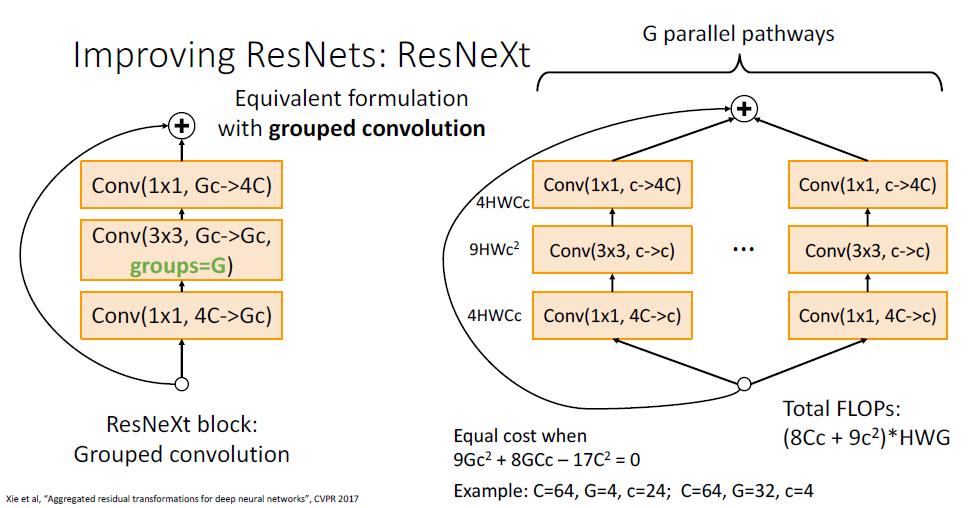

ResNext 아키텍쳐는 ResNet대비 동일한 연산량을 유지하면서도, parallel pathway를 추가하는 것으로 더 나은 error rate를 보이는 것을 보여준다.




concatenation shortcut을 활용하였다

높은 정확도를 유지하면서도, 연산량을 중요하게 다루게 되었고,
하나의 예시가 MobileNet이다.

모바일기기에 적합한

이러한 아키텍쳐를 디자인하는데 있어서 인기를 끈 방법중하나가





'기초 노트 > EECS 498-007 (ComputerVision)' 카테고리의 다른 글
| EECS 498-007 Lecture 12: Recurrent Neural Networks 정리 (0) | 2024.04.29 |
|---|---|
| EECS 498-007 Lecture10: Training Neural Networks Part1 정리 (0) | 2024.04.04 |
| EECS 498-007 Lecture 07 : Convolutional Networks 정리 (1) | 2024.03.25 |
| EECS 498-007 Lecture 06 : Backpropagation 정리 (0) | 2024.03.21 |
| EECS 498-007 Lecture 05 : Neural Networks 정리 (0) | 2024.03.17 |



