
오늘은 새로운 종류의 신경망인 RNN에 대해서 다룬다.
본격적으로 시작하기 전에, 우리가 지난 강의 딥러닝의 소프트웨어와 하드웨어를 다룬 장에서
파이토치와 텐서플로우를 비교한적이 있었는데
현재 강의하고 있는 전후인 19년도 10월 10일에, 파이토치 1.3이 업데이트 되었다.
파이토치가 더 선호되면서도, 텐서플로우보다 모바일에서 배포하기 까다로운 단점이 여전히 있던 문제가 있었는데
이제는 금번 업데이트로, 이론적으로 모바일에서도 배포하기 좋은 환경이 되었다!
이렇게 한 학기에도, 심지어 1~2주전에 다룬 내용이 outdated되는 걸 볼 수 있는게 바로 딥러닝 분야이다.!
우리는 지난 두번의 강의에 걸쳐 신경망 학습의 기본 전략(nuts and bolts)에 대해서 자세히 다루었다.
이제 우리는 ConvNet을 학습시켜서 image classification과 같은 task를 다루는 것에 대해서는 상당한 전문가라고 볼 수 있을 것 같다.
이제는 더 나아가 image classification뿐만 아니라, 딥러닝으로 또 다른 문제를 해결해보려고 한다.
그것이 오늘의 주제인 Reccurent Neural Network에 관한 것이다.
지금까지 우리가 논의 했던 feed forward network는 convolutional layer나 batch normalization과 같은 fancy layer들을 포함하는 구조로, input으로 single image가 들어가서 output으로 해당 이미지의 label을 뱉는 구조였다.(이를 one-to-one이라고 한다.)
빌딩 블록과도 같은 ConvNets은 여러 딥러닝의 분야에서 중추적인 뼈대를 수행하는 장치로 캡슐화되어 있기 때문에 상당히 중요하다고 할 수 있다.
하지만 image classification같은 problem말고도 딥러닝으로 풀고자 하는 문제가 상당히 많이 있는데,
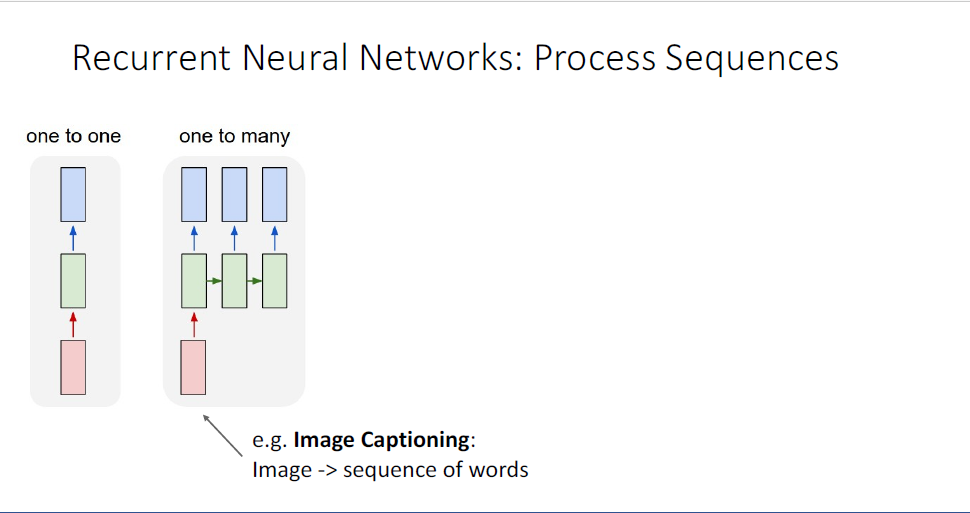
예를 들어, 우리가 풀고자 하는 문제가 one-to-one의 형태가 아니라 one-to-many의 형태일 수가 있다.
여기서 input은 여전히 single image와 같은 것들이지만 output이 label이 아니라 sequence형태인 것이 그것이다.
이것의 대표적인 예시가 image Captioning task이다.
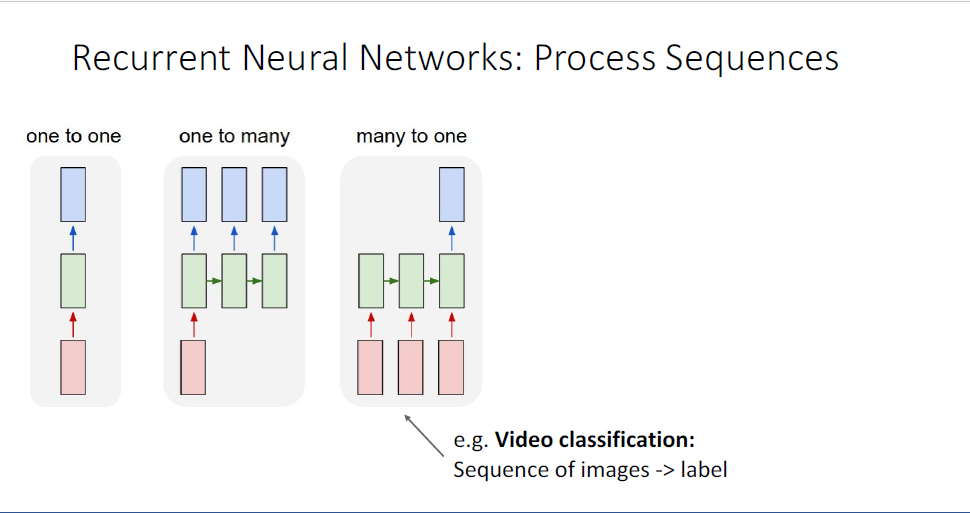
또 다른 형태는 many-to-one task이다.
many to one으로는 Video Classifcation task가 있다. 여기서의 input은 video를 구성하는 video frame의 sequence이고,
비디오 내에서 어떤 타입의 이벤트가 발생했는지와 같은 정보의 single label이 output이 된다.
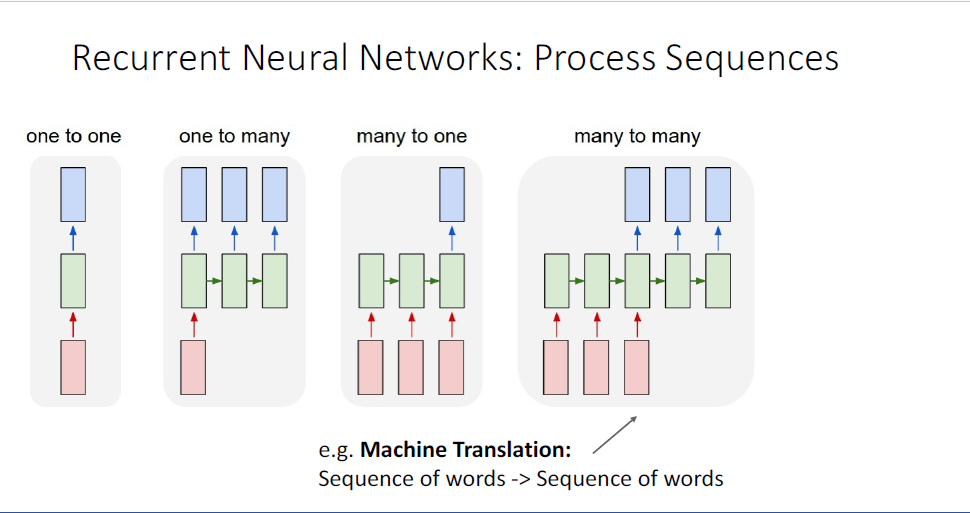
many to many는 input의 형태가 시퀀스이고, 아웃풋의 형태 여전히 시퀀스인 task이다.
이러한 task의 예로는 기계 번역(machine translation)이 있다.
English의 문장 시퀀스를 input으로 받아 French의 문장으로 ouput을 뱉는 예가 될 수 있겠다.
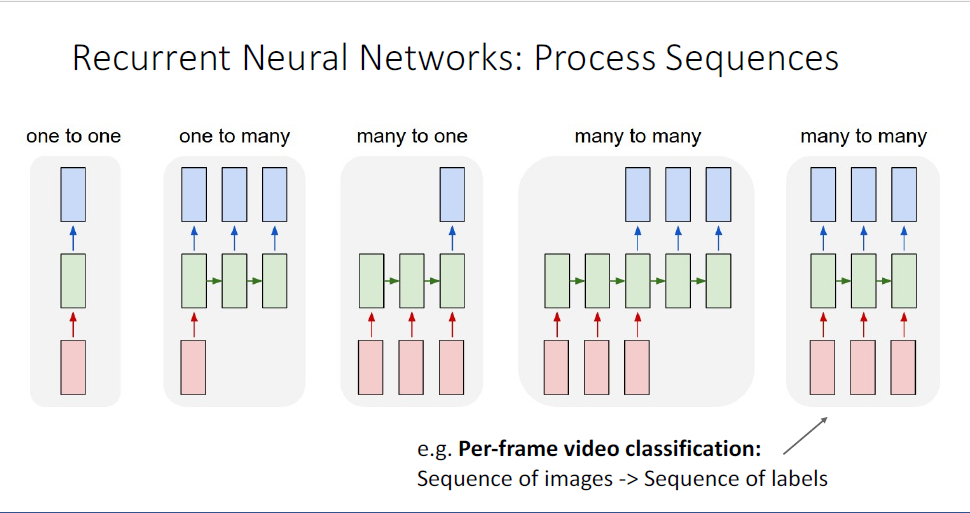
그리고 또 다른 many to many의 형태로는 sequence의 input마다 output을 뱉는 형태인데, 예를 들면
video frame sequence로부터, 첫 세개의 프레임은 농구공을 드리블하고 있는 사람의 장면, 다음 10개의 프레임은 농구공을 슈팅하는 장면등 비디오의 내용 전체에 대해서 하나의 라벨을 output으로 뱉는 것이 아니라, 프레임마다의 label을 뱉는 task가 되겠다.
지금 것처럼, 단일 이미지를 input으로 받아, 단일의 라벨을 내뱉는 것이 아니라, 시퀀스를 입력으로 받아 시퀀스를 출력하는 형태를 처리할 수 있다면 더욱 많은 task를 다룰 수 있다는 것을 안다.
그렇게 하기 위한 딥러닝의 보편화된 도구이자 새로운 신경망의 형태가 바로 Reccurent Neural Networks이다.
우리는 RNNs이 각각의 개별적인 시퀀스의 길이에 대하여 처리해줄 수 있기 때문에 더이상 시퀀스의 길이를 개별적으로 체크하거나 개별적으로 다룰 필요가 없게되었다.

그런데 RNN은 꼭 시퀀셜 데이터에 대해서만 다루는 것이 아니다.
사람들은 시퀀셜 데이터가 아닌 데이터를 처리할때도 RNN을 사용하는데,
이때는 non-sequential데이터를 sequential processing을 하는 것이다.
예를들어 이미지에 대해서라면, 원래는 single image를 input으로 받아 원하는 label을 뱉는 one to one의 형태가 바로 Image Classification task였지만
이미지를 시퀀셜한 입력으로 처리하여, 이미지의 multiple glimpse를 취하는 것을 목적으로 한다.
sequential processing으로 취한 multiple glimpse를 통해 네트워크는 최종적인 이미지 내의 객체가 무엇인지 classification decision을 취하게 된다.
전체 네트워크의 decision process는 매 타임 스텝마다 이미지에서 extracted된 이미지의 condition에따라 결정되게 되는 것이다.

writing decision
underlying task가 sequential task가 아님에도 불구하고

sequential processing뿐만 아니라 non-sequential 데이터에 대해서도 새로운 방법으로 문제를 풀 수 있는 열쇠를 제공하였다. 이것은 RNN에 대한 좋은 motivation이 될 것이다.

그래서 RNN이 무엇이고 어떻게 작동하는가?
기본적인 아이디어는 앞서 언급했듯, sequential data를 만드는 것이다.
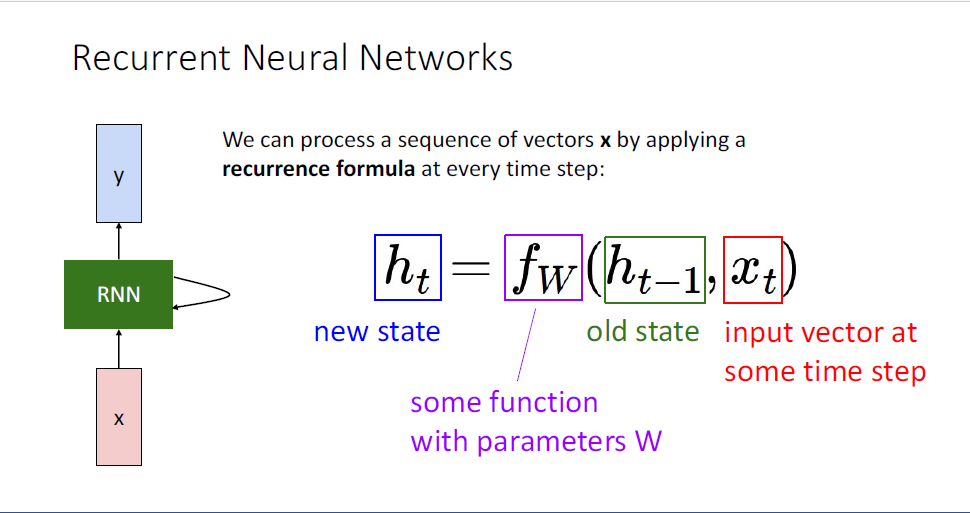
reccurence relation이 도입된다.
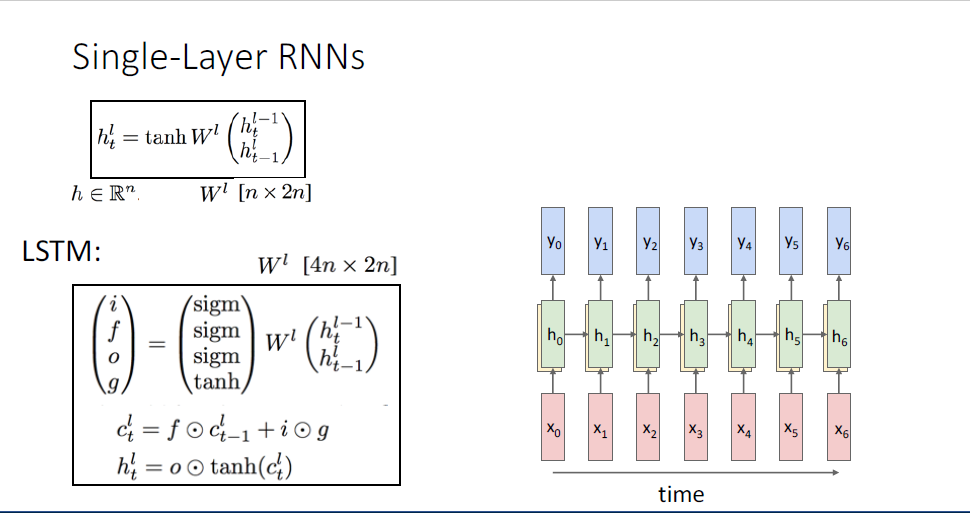
여기서 hidden state의 벡터는 지금껏 보아왔던 feed forward network의 벡터와 동일하다.
각각의 hidden state들은 이전 타임스텝의 hidden state들과 서로 다른 대수적 공식(algebric formulation)을 통해 연결되어 있는 것을 알 수 있다.
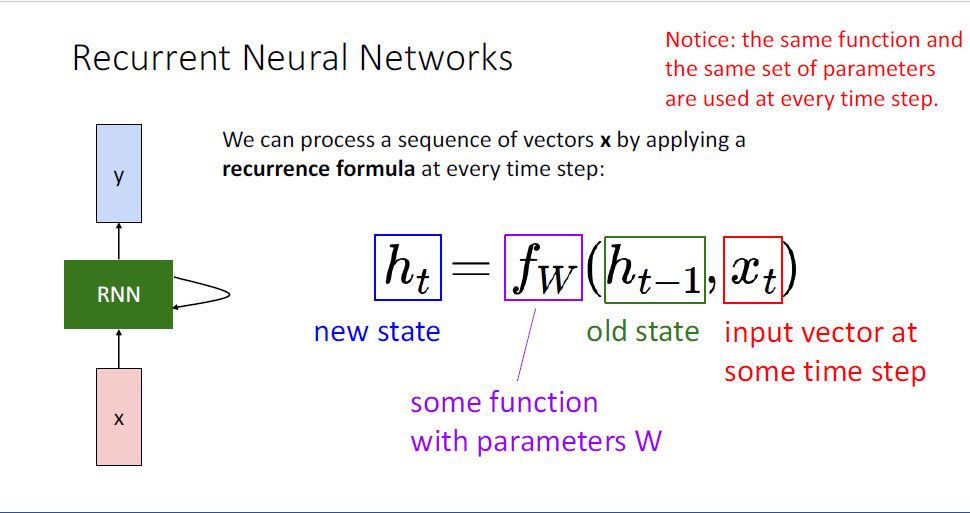
여기서 중요한 것은
즉 다시말해 정확히 동일한 weight matrix를 공유한다. 정확히 동일한 shape의 weight matrix를 통해, 개별적인 시퀀스의 길이를 다루게 되는 것이다.
여기까지가 Reccurent Nueral Network에 일반적인 정의이다.
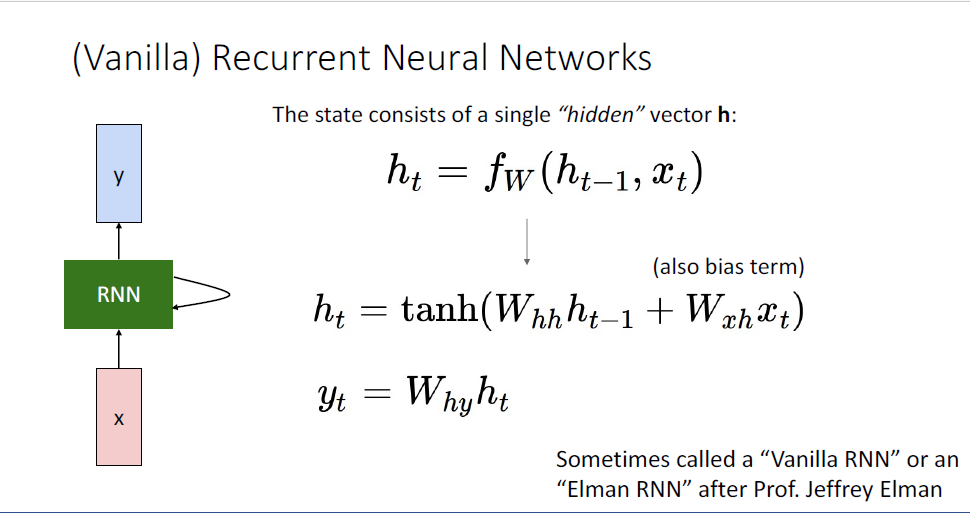
RNN을 좀 더 구체적으로 살펴보기 위해 ,일반적으로 (Vanilla) RNN이라고 불리는 신경망을 통해 RNN을 알아본다.
여기에 또한 learnable bias term을 추가해서 (편의상 슬라이드에서는 생략되었다.) non-linearity로는
RNN 요소를 좀 더 명확히 설명하였다.

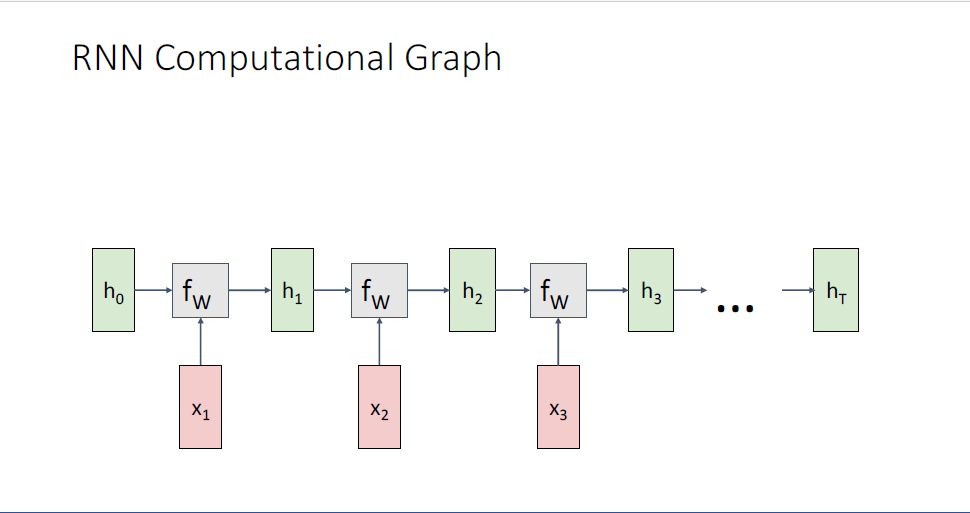
Recurrent Nueral Network가 어떤식으로 데이터를 처리하는지 살펴보기 위해서 또 다른 방식으로
RNN의 구조를 풀어헤쳐(unrolling) Computational Graph가 어떤 형태를 취하고 있는지를 살펴본다.
일반적으로 initial hidden state
가끔은 initial hidden state를 learnable paramter로 만들어 이를 학습가능하게 만드는 네트워크를 별도로 두는 경우도 있는데, 이는 implentation 디테일 차이이다.
우선은 모든 initial hidden state

initial hidden state
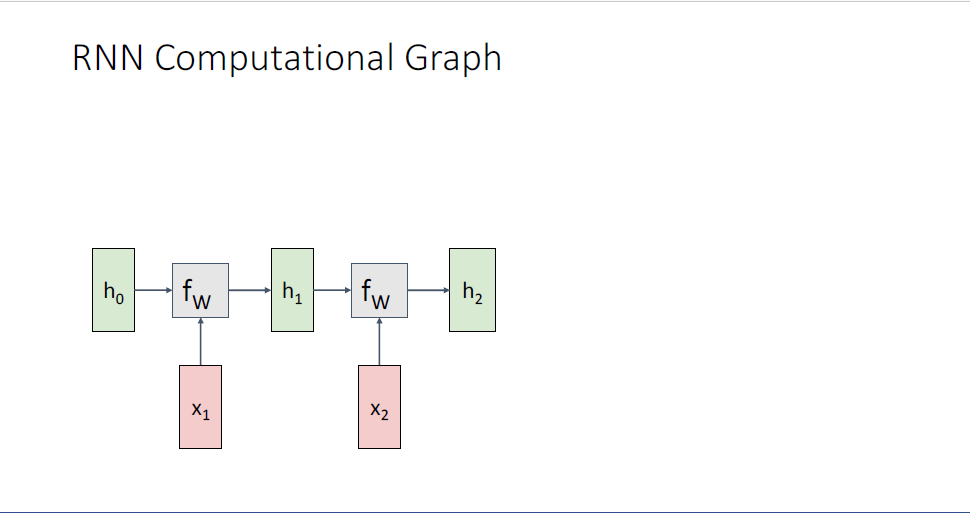
다시 동일한 함수인
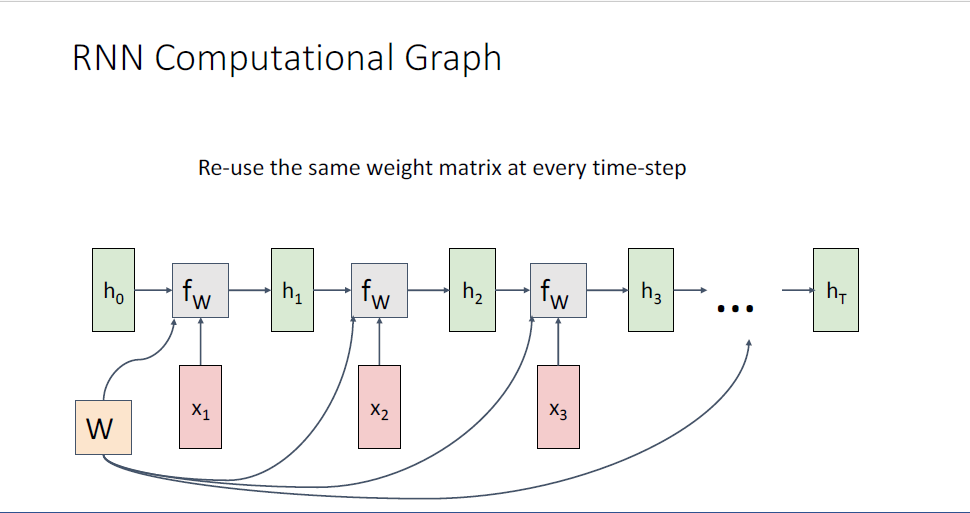
여기서 중요한 것은 Computational graph가 보여주듯이, 정확히 동일한 Weight Matrix
이전 backporpagation에서 배웠듯이 copy node같은 경우에는 gradient가 더해지는 성질이 있다.
이 것은 RNN의 implentation에서 중요한 성질이다.
input으로 어떤길이의 시퀀스를 입력받더라도, 이러한 단일의 RNN layer로도 원하는 만큼의 시퀀스 길이를 output으로 만들 수 있다.
그러면 아까 살펴본 많은 one to one, one to many ... many to many와 같이 다양한 타입의 task들을 이러한 Baisc RNN으로 어떻게 다루게 되는걸까?
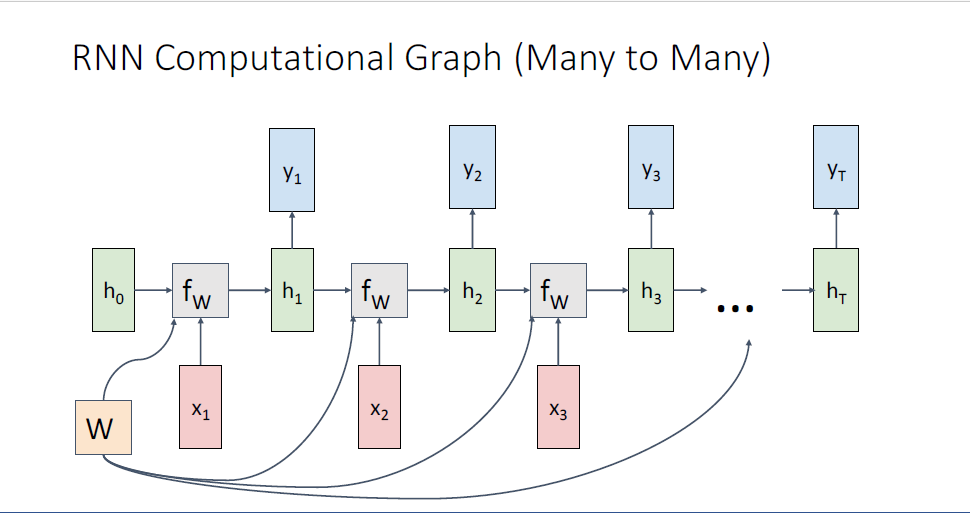
보이는 그림은 Many to Many로,
video classification과 같은 task의 모습이다.
output
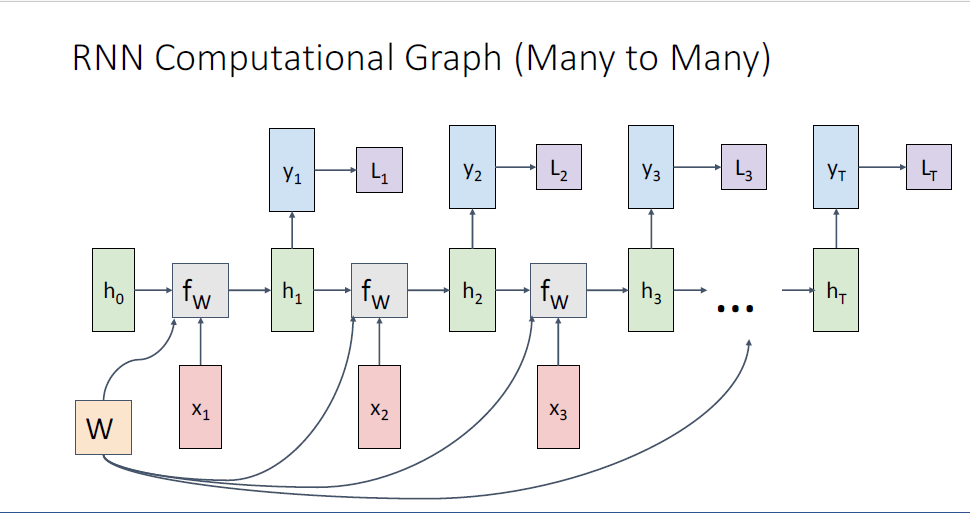
학습을 시킬때에는 label이 필요하고 , CrossEntoryLoss등의 loss function을 통해 시퀀스의 매 타임스텝마다의 loss를 구하게 된다.
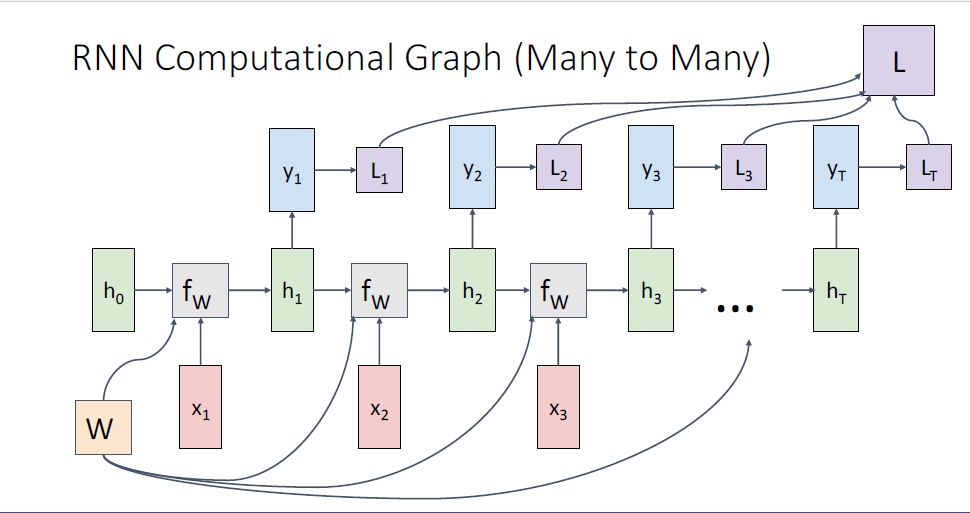
이후 매 타임스텝의 loss를 모두 더하여 total loss를 구하고 backpropagation을 수행한다.
위의 그림이 시퀀스의 매 타임스텝마다 output을 만들어내는 many to many task의 full computational graph이다.
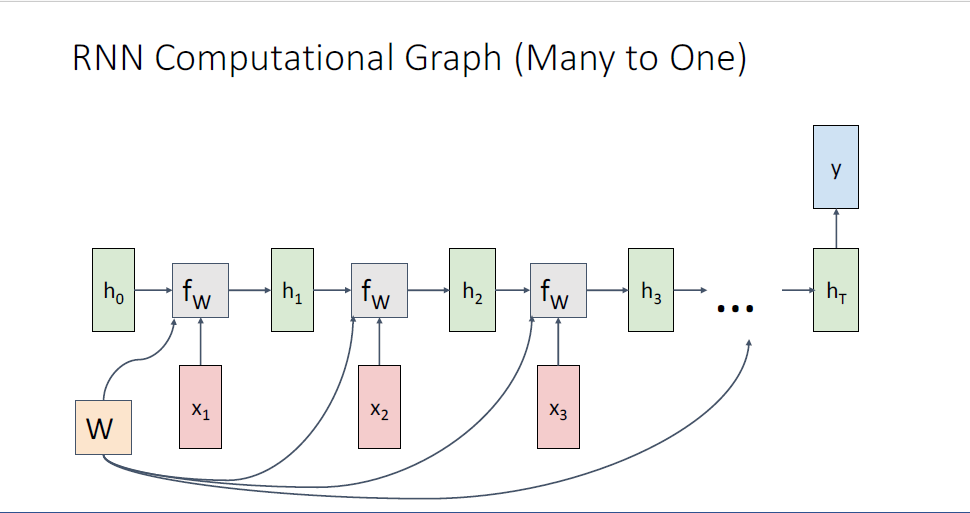
이번에는 Video Classification과 같은 Many to one같은 경우, Video content 내용에 관한 단 하나의 레이블이 필요하고
모델이 single prediction을
모델은 final output을 만들기 위한 과정이 모두 캡슐화 되어있다.
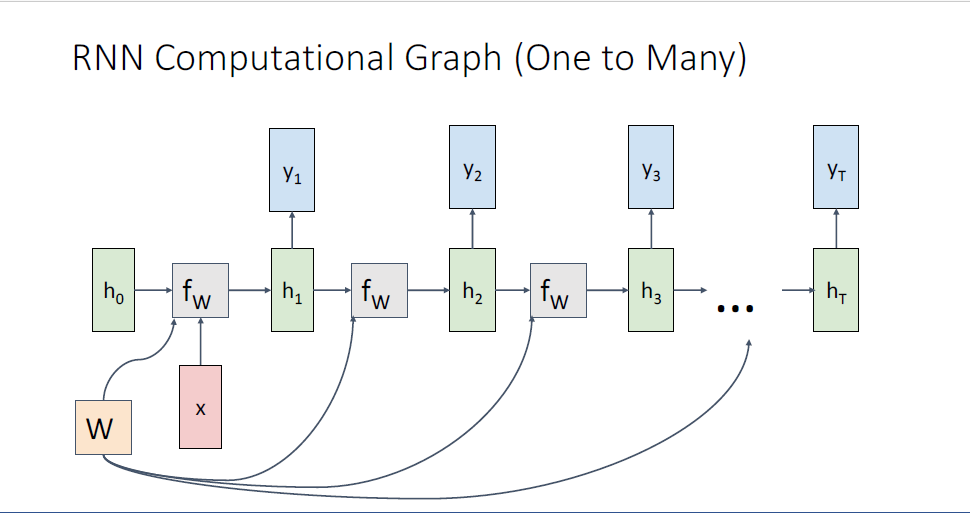
image captioning과 같은 one to many의 상황에서는 아마도 single image를 input으로 주게되고, image를 묘사하는 단어 시퀀스를 output으로 내뱉는다.
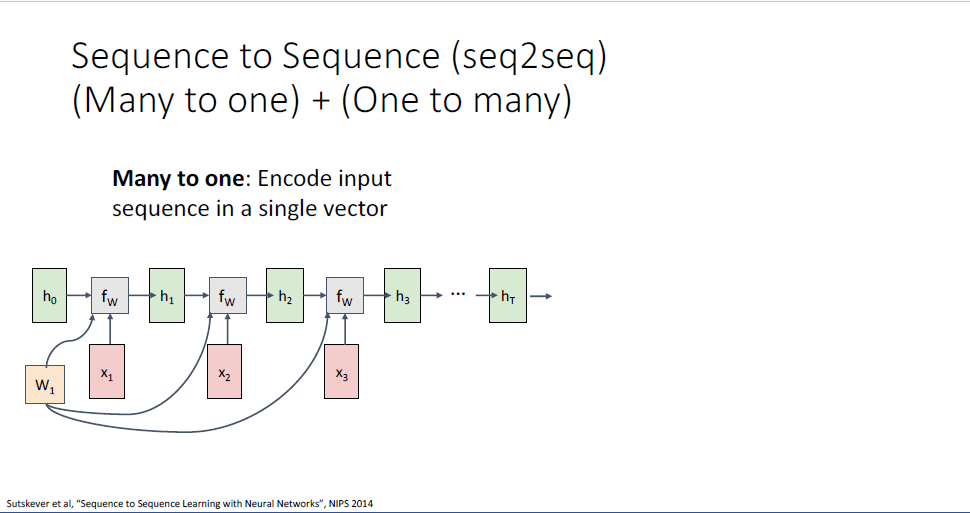
그리고 RNN을 통해 일반적으로 활용하는 또 다른 것중에 하나가 seq2seq라 불리는 것인데,
machine translation과 같은 task가 그 예가 되겠다.
input으로 어떤 문장의 sequence가 주어지고 output으로는 다른 언어이고, 개별적인 길이의 시퀀스를 뱉기를 원한다.
아마도 영어 문장을 input으로 주어지고 프랑스어를 output으로 뱉길 원한다고 할때, 두 언어의 시퀀스의 길이가 일치하지는 않을 것이다.
이러한 seq2seq는 Many to one RNN과 One to many RNN의 결합이다.
Many to one RNN의 결과물을 곧바로 One to many RNN에 활용하는 구성이다.
예를 들어 영문장이 input으로 주어지게 되면,
시퀀스의 끝 히든스테이트에 이러한 영문장에 대한 요약정보가 담기게 된다.
이 과정을 수행하는 앞단의 RNN을 Encoder라고 부른다.
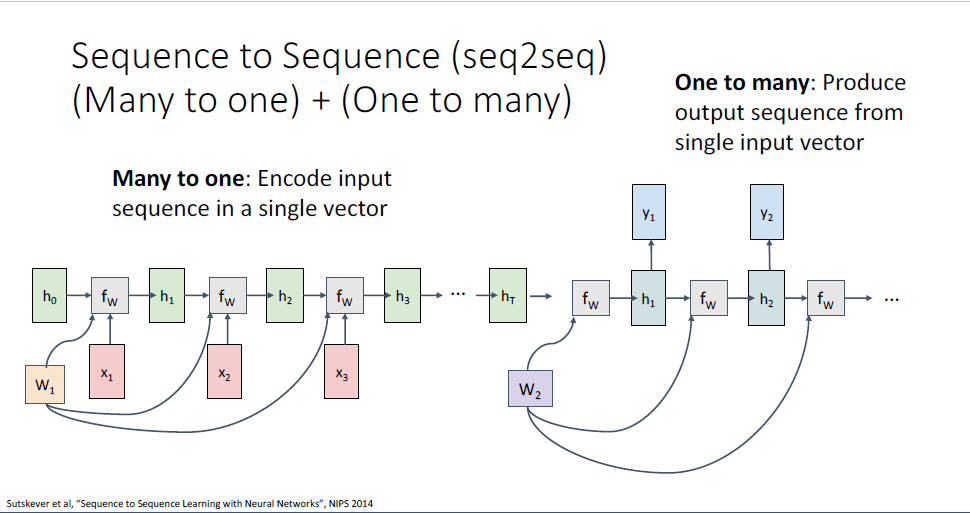
Encoder sequence의 벡터를 뒷단의 RNN에 single input으로 feed한다.
이 떄 두번째 RNN을 decoder라고 부르고 one to many의 구조를 갖고 있다.
Encoder와 Decoder는 서로 다른
여기서 하나의 RNN이 아니라 Encoder, Decoder의 두가지 구조로 나눈 것에 대한 질문이 있을 수 있다.
이러한 이유는 우리가 input 시퀀스 토큰에 대응되는 output 시퀀스 토큰의 길이를 모르기 때문이다.
그렇다면 Decoder를 별도로 사용하여 별도의

이것이 어떻게 작동하는지를 Language Modeling Task를 통해 구체적으로 살펴보고자 한다.
input으로는 무한한 길이의 데이터가 주어지고, 매 타임마다 다음 문자(Character)가 무엇인지 예측하게 하는 구조이다.
이러한 task를 수행하기 위한 setup으로는 정해진 vocabulary가 필요한데, vocabulary에는 각 문자가 포함되어 있다.
학습의 초기에 이러한 vocabulary가 결정되어야 한다.
위의 예시에서는 h-e-l-l-o, 즉 "hello"라는 단어를 각각의 문자의 시퀀스로 표현하고
각 시퀀스는 4개의 요소를 가진 원핫벡터로 인코딩한다.
"h"가 "[1, 0, 0, 0] ", 즉 시퀀스의 첫번째 슬롯에서 1의 값을 갖는 이유는 우리의 vocab에 첫번째 문자에 해당하는 h가 포함되어 있기 때문이다.
우리는 이러한 원핫벡터를 네트워크에 feed 하게된다.

RNN은 sequcne of vector를 통해 sequence of hidden state를 만들고,
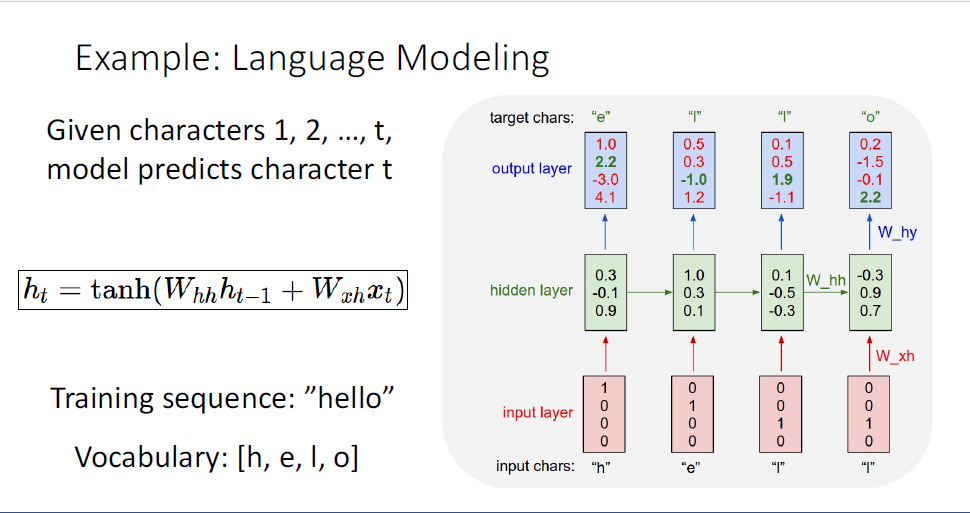
매 타임스텝마다 vocabulary에 포함된 글자들의 output distribtuion을 만들게 된다.
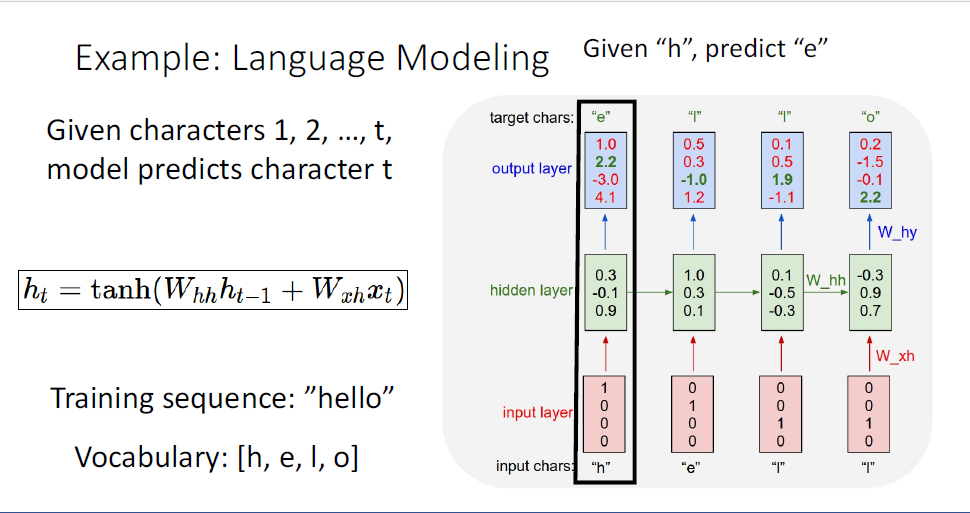
이 task에서는 매 다음 단어를 예측한다고 했는데, 처음 input이 "h"였기 때문에 output으로 "e"를 예측하게 되고
이 때 CrossEntropyLoss등을 사용한다.
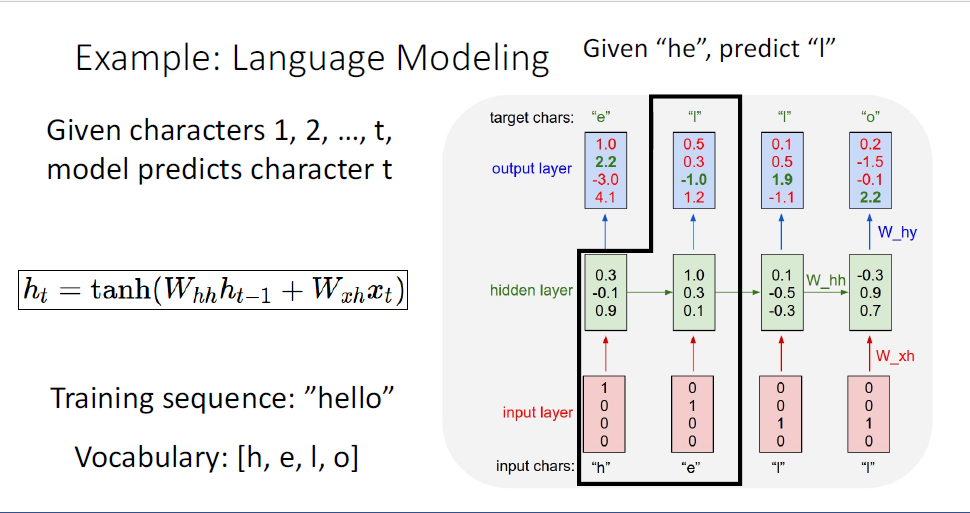
다음의 예측으로는 input으로 h,e까지 받았기 때문에 세번째 글자인 "l"을 예측한다.
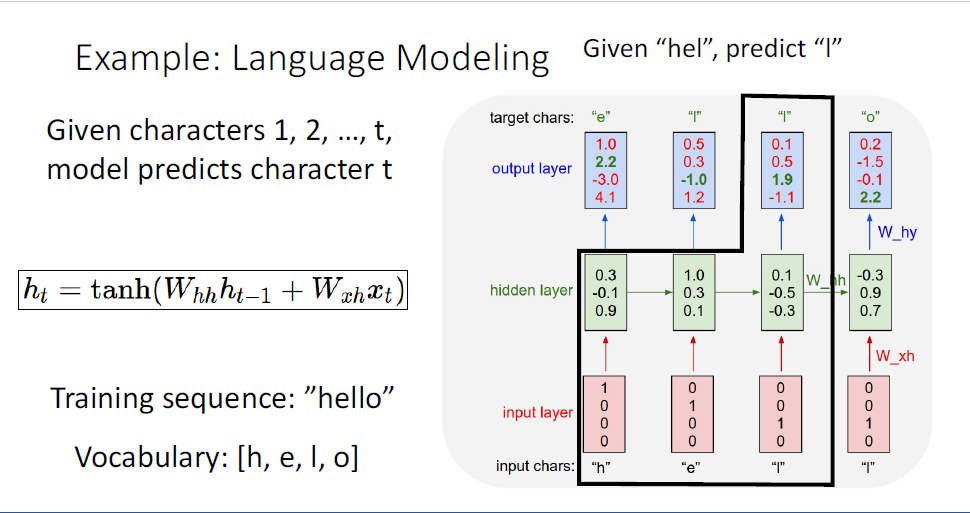
같은 과정이 반복되고,
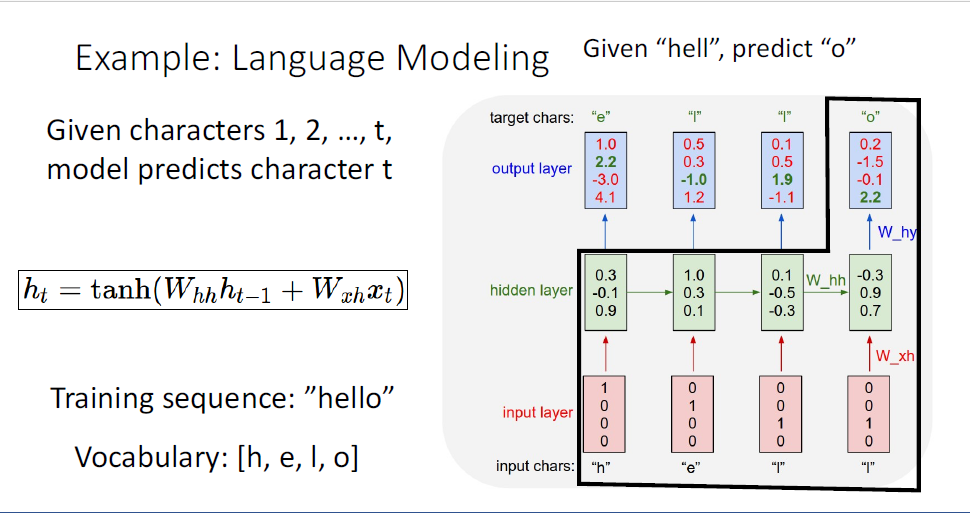
여기까지의 과정이 Launguage model이 학습하는 과정이며,
정리하자면 input으로는 "h,e,l,l"이 ouput으로는 shift된 "e,l,l,o"을 예측하길 원하는 것이다.
이 과정으로 모델의 학습이 완료되었다면, 학습된 모델의 스타일대로 텍스트를 생성할 수 있게 된다.
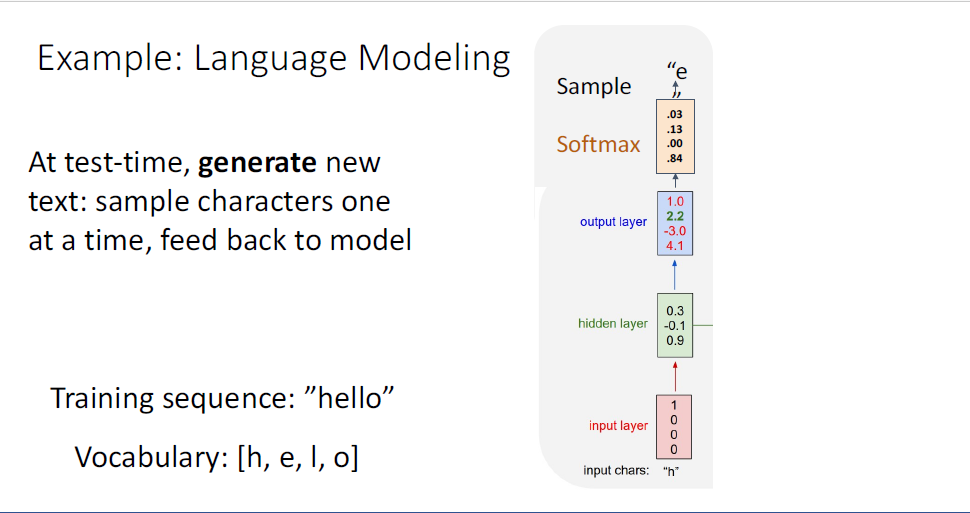
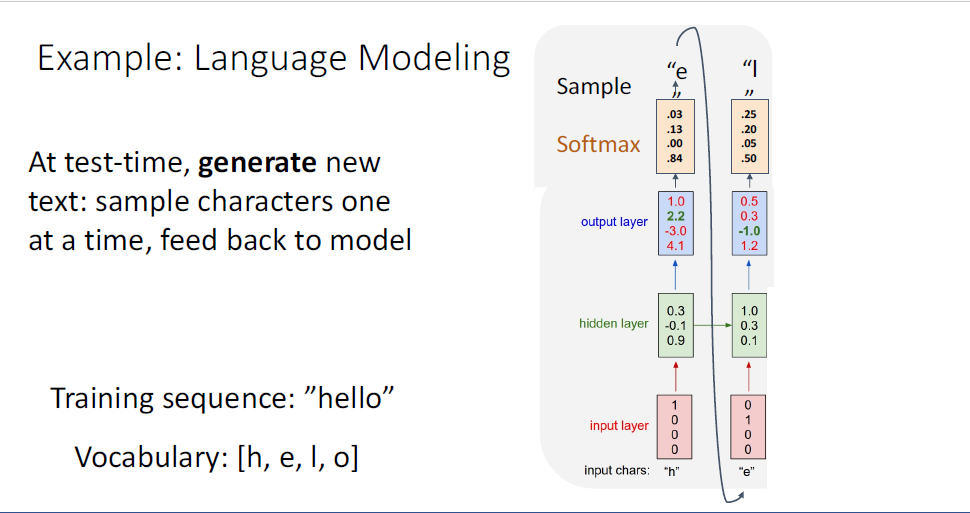
test time에서는, 학습된 모델로부터 "h"가 아닌 또 다른 initial seed token을 부여하고
이제 모델이 이러한 initial seed token의 스타일 대로 새로운 텍스트를 생성하길 원하게 된다.
이때의 과정은 input token "h"를 원핫 인코딩하여 RNN의 첫번째 hidden state를 통해 해당 타임스텝의 다음 단어 예측에 대한 distribution을 얻는다.
이러한 distribtuion은 모델이 생각하기에 다음 문자로 예측되는 것에 해당하는 확률이기 때문에,
distribtuion으로부터 sample을 취하게 된고, 이 샘플을 통해 두번째 input으로 feed back하게된다.
여기 예시에는 첫번째 ouput "e"가 input이 되는 것이다.
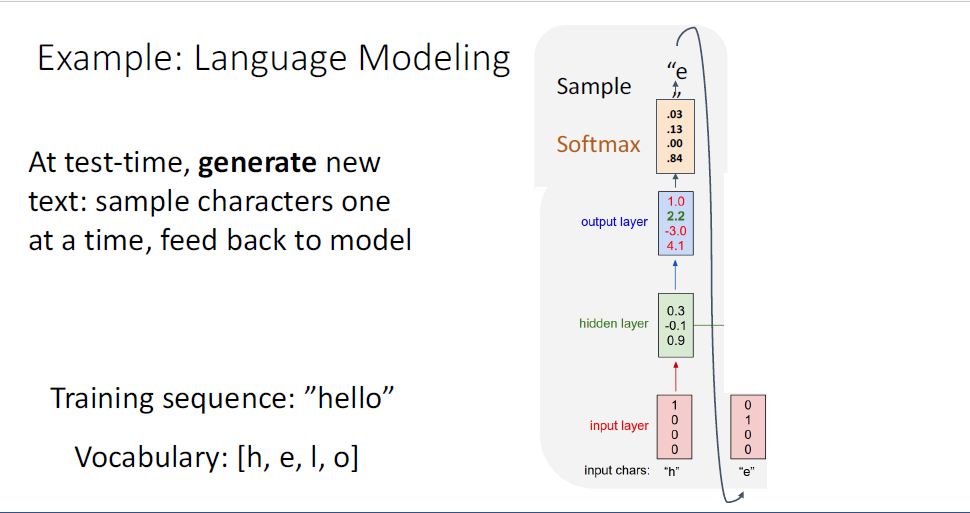
역시 동일한 과정이 반복된다.
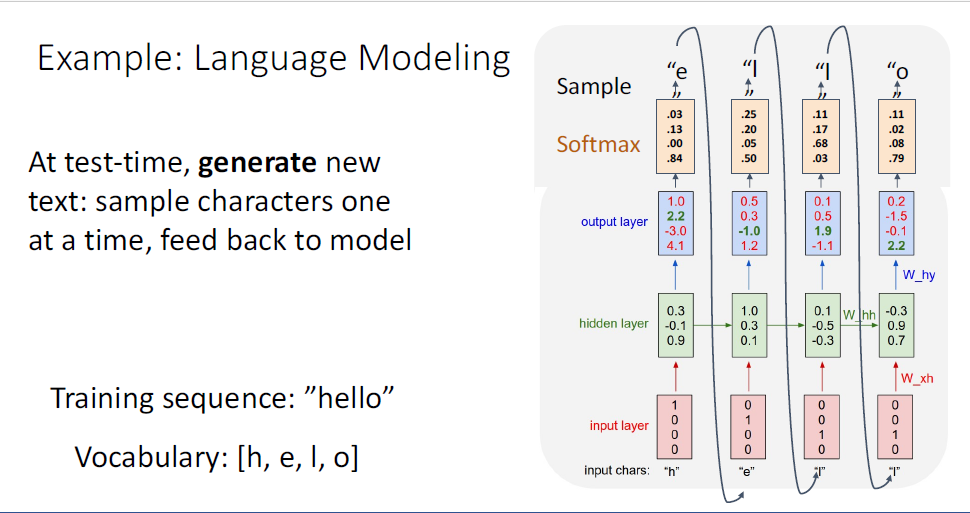
모델은 부여한 initial token의 방법대로 생각하여 output을 생성하게 된다.
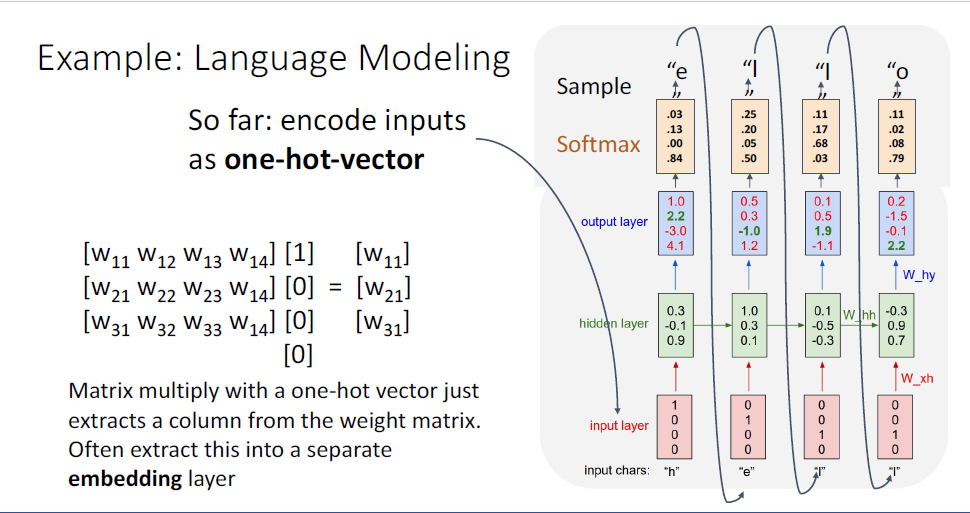
지금까지는 문자를 원핫벡터로 인코딩했는데, 여기에는 ugly detail이 있다.
원핫벡터를 vanilla RNN구조에 적용하는 예를 생각해보면 매우 trivial 한데,
원핫벡터의 matrix multiplication의 계산결과는 단일의 칼럼을 내뱉기 때문이다.
따라서 전체 matrix multiplication루틴을 수행할 필요도 없이, 그냥 해당 값을 추출해내면 된다.
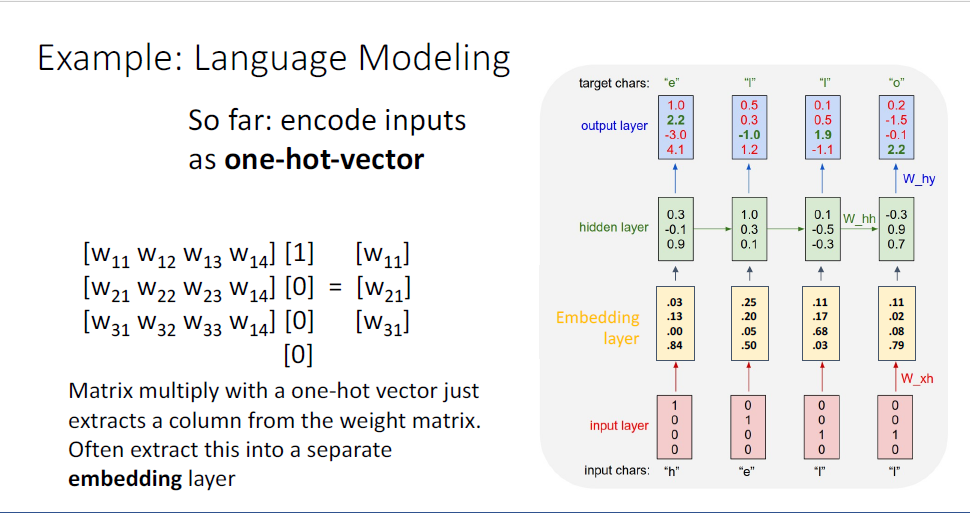
그래서 이러한 이유때문에, input layer와 reccurent neural network layer사이에 또다른 layer인 Embedding layer를 추가한다.
embedding layer는 sparse vector인 원핫벡터의 형태를 vocab에 대응되는 embedding vector로 바꾸는데
이때의 embedding weight matrix는 input인 원핫벡터로 부터 vocab을 구분할 수 있는 embedding vector로 바꾸는 것을 학습한다.
RNN은 이러한 embedding layer를 도입하는 구조가 매우 일반적인 디자인이다.
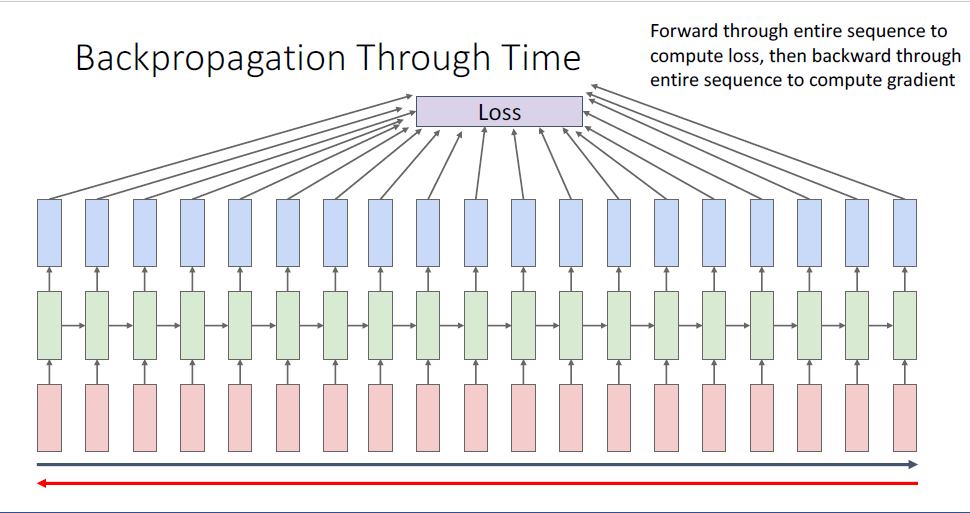
RNN을 학습시키기 위해서는 RNN computaional graph를 전체 타임스텝에 걸쳐 펼쳐야 한다.
여기서 매 타임스텝마다 loss가 계산되고, 모든 길이의 시퀀스에 대응되는 타임스텝의 loss를 합산하여 total loss 단일값을 얻게 된다.
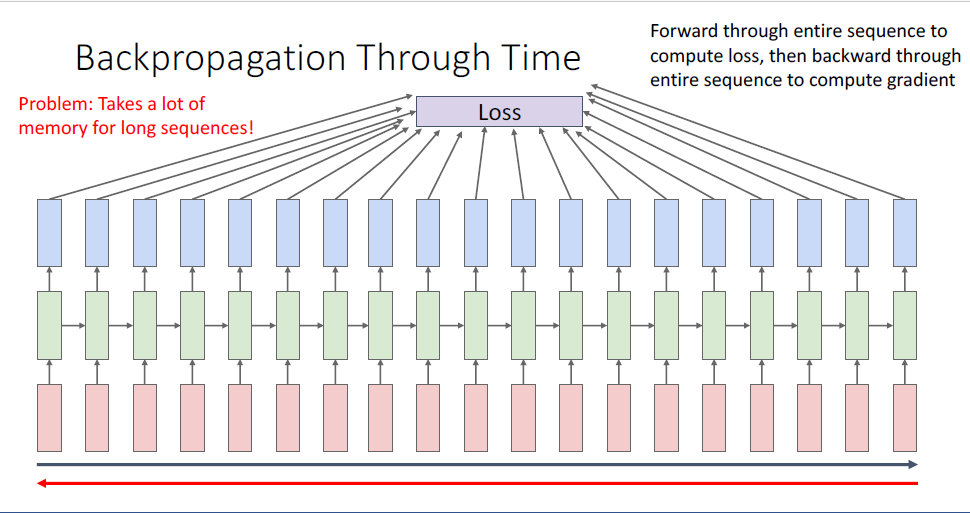
이 과정을 Backpropagation Through Time ,BPTT라는 fancy한 이름으로 부르기도 하는데,
BPTT의 문제는 너무 긴 길이의 시퀀스에 대응되는 요소를 GPU 메모리에 모두 담을 수가 없다는 것이다.
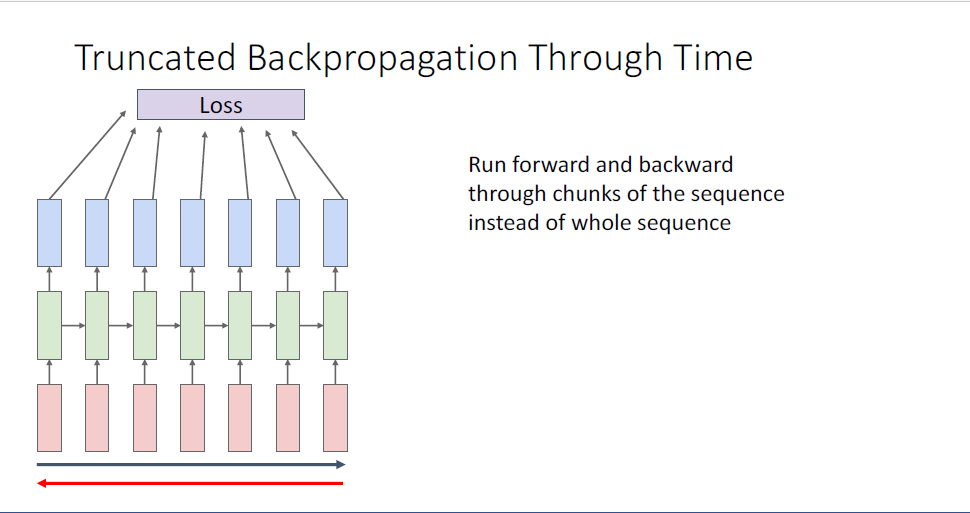
이러한 문제 때문에, 대안적인 근사하는 방법으로 truncated back propagation through time이라 불리는 방법을 사용하기도 하는데, 시퀀스의 첫 일부분, 10개의 토큰이나 100개의 토큰등 처음 부분만의 loss값만을 계산하고 hidden state값을 기억한다.
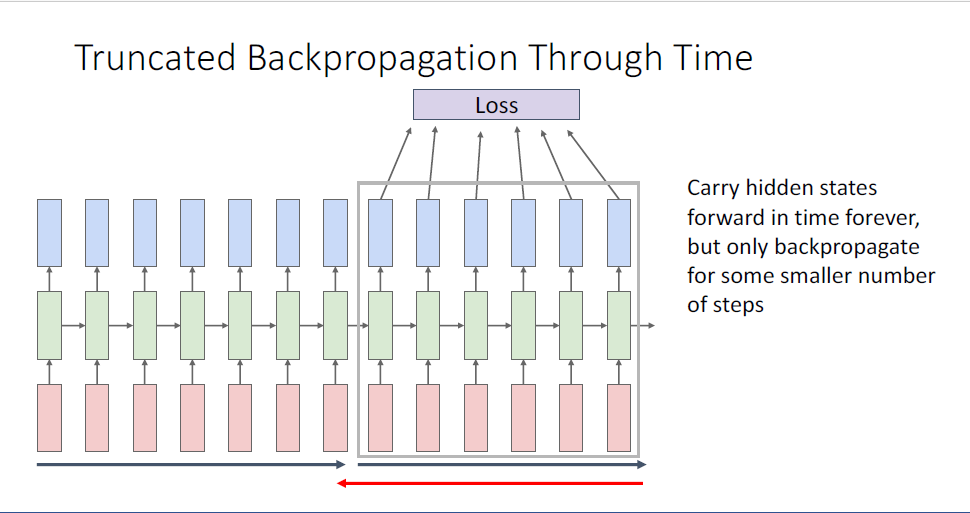
그리고 기록된 정보로부터 다음 100개의 시퀀스 토큰에만 backpropagation을 진행하는 것이다.
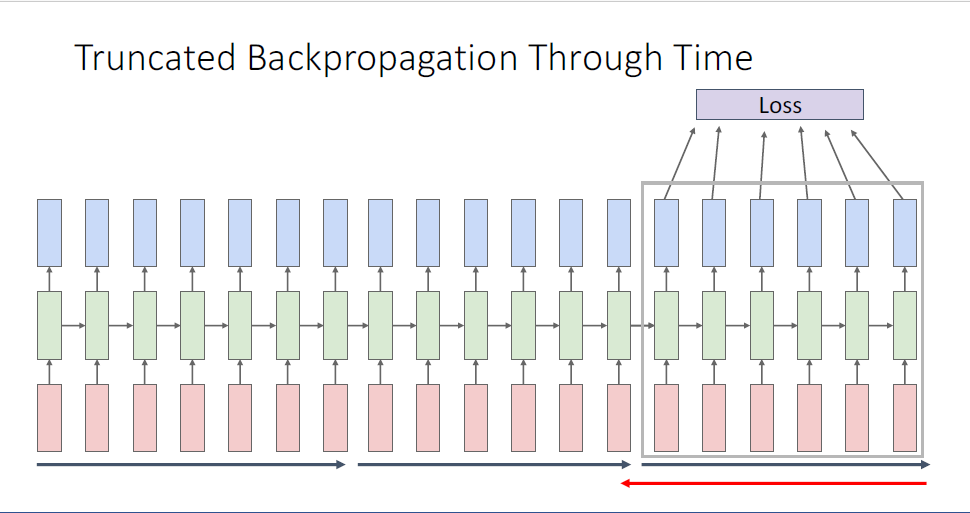
매 truncated bptt마다 weight를 업데이트 한다.
이러한 truncated BPTT의 방법으로 무한대의 길이에 가까운 시퀀스를 입력으로 받더라도, GPU메모리가 얼마가 되든 학습이 가능하게끔 한다.
여기서 질문, 두번쨰 chunk의 initial hidden state는 어떻게 되는가는, 직전 chunk의 마지막 hidden state를 사용한다.
forward pass에서는 무한한 길이를 모두 고려하지만 backpropagation에서만 chunk단위로 학습을 진행하기 때문에 그러한 trick을 사용한다. 매 chunk의 마지막 hidden state에는 직전 chunk의 모든 정보가 담겨있기 때문에, input sequcne의 정보를 모두 날려버려 메모리를 세이브하게 된다.
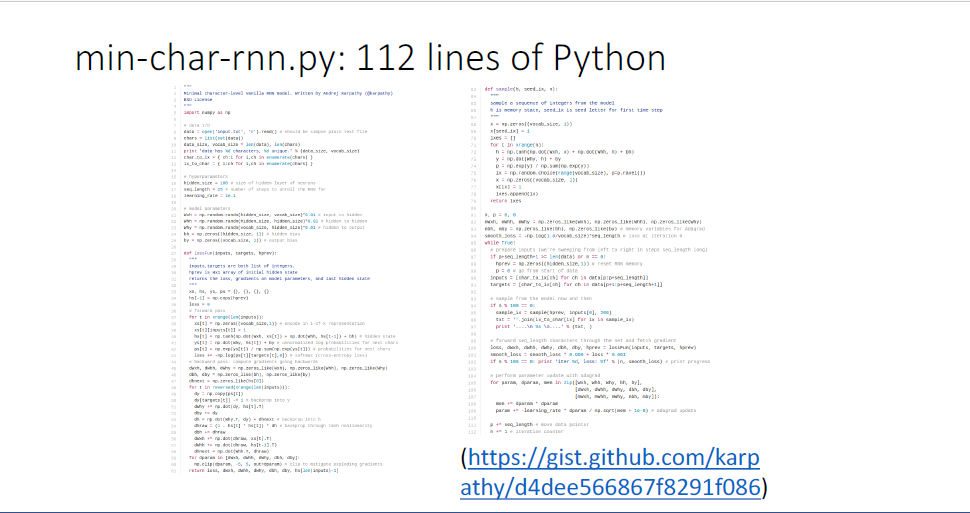
매우 복잡한 아이디어 같지만 단지 112줄의 파이썬 코드로 구현할 수 있다.
여기에는 어떤 autograd나 pytorch같은 라이브러리가 사용되지 않았는데, 파이토치를 사용하면 40줄이면 된다.
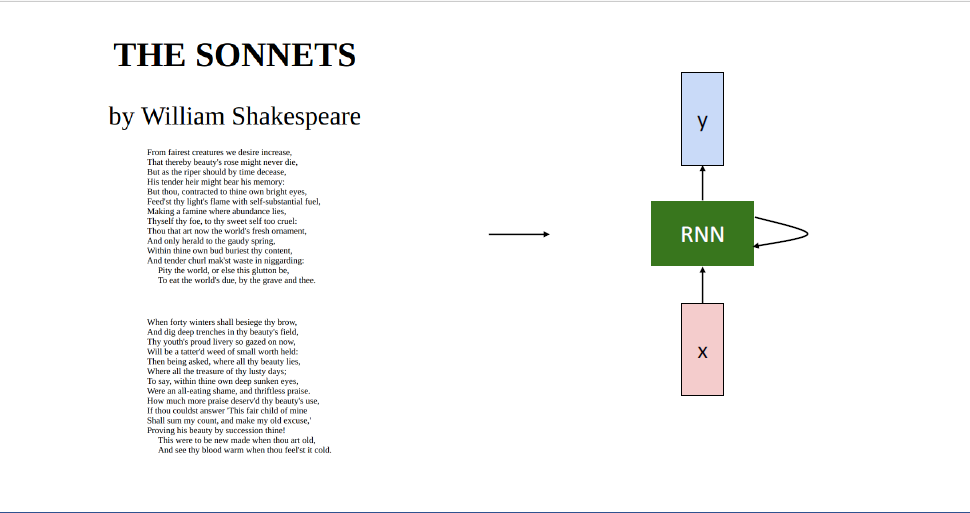

처음에는 garbage를 내뱉지만, 조금 더 훈련을 시키면 도큐먼트의 구조 정도를 포착하는 모습이고, 다음에는 올바른 단어가 포착되기도 하고, 이후에는 상당히 realistic해진다. 뭐 살펴보면 문장구조가 엉망이지만 어쩃든 영어긴 하다.

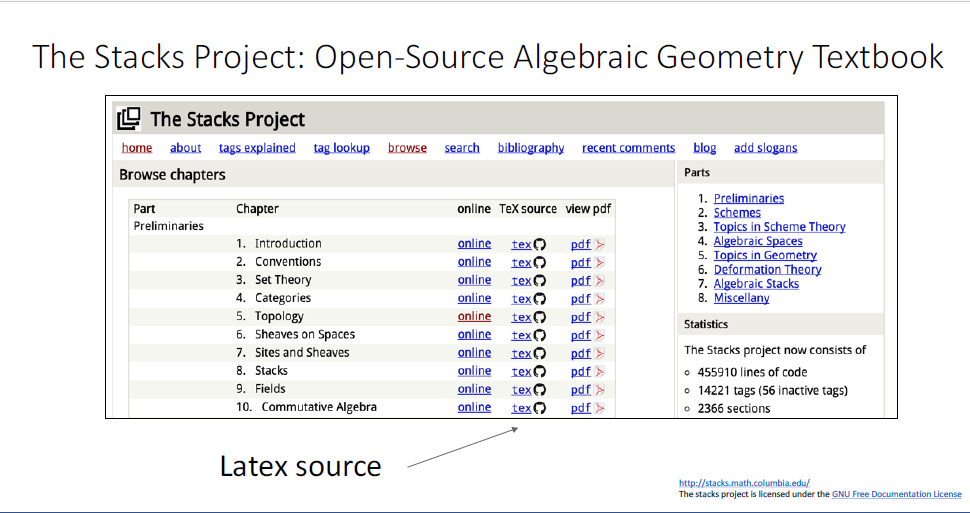

거의 math이긴 하다 lemma와 proofs가 있고, 무언가를 증명해내고 있다.
아무튼 문자 수준의 (character level) RNN은 어떤 데이터든 학습할 수 있다는 것이 포인트이다.

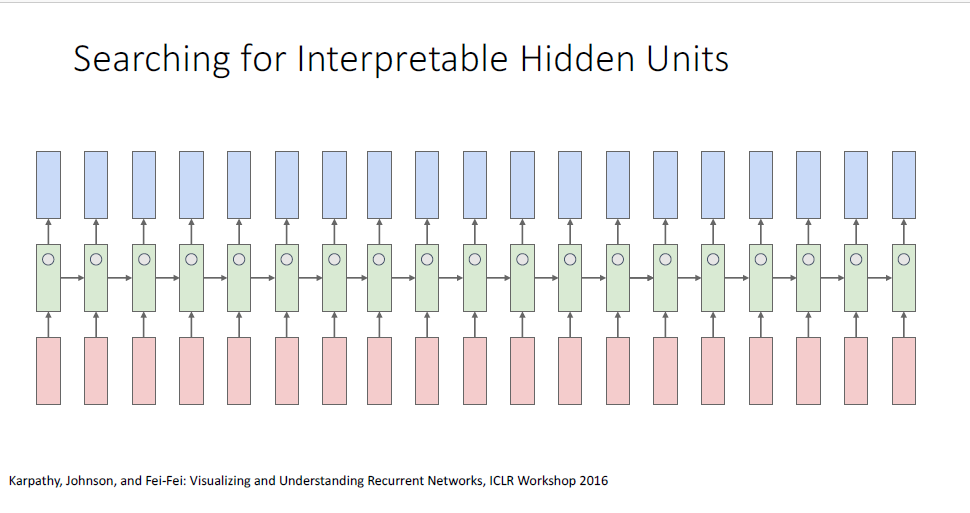
대충보면 진짜 같은 C 소스 코드이다. 신경망 모델이 데이터를 통해 structure를 잘 학습한 것을 알 수 있다.

리눅스 커널 데이터셋으로 부터 다음 단어의 예측을 수행하는 task를 진행하였는데

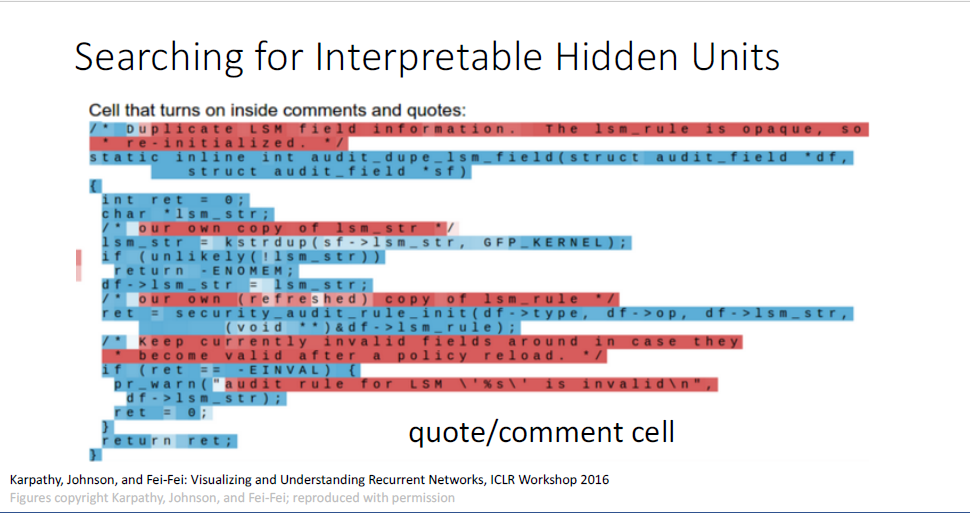
톨스토이의 war and peace라는 소설을 바탕으로 진행한 결과인데,
인용구 안에 포함된 것인지의 대한 마치 binary swith를 학습한 결과라고 해석해볼 수 있을 것 같다.



지금까지의 결과로, RNN은 단순히 다음 단어를 예측하는 겉보기에 큰 의미가 없는 task를 진행할때에도 input받는 데이터인 어떤 문장의 structure를 학습하려고 한다고 결론지을 수 있다.
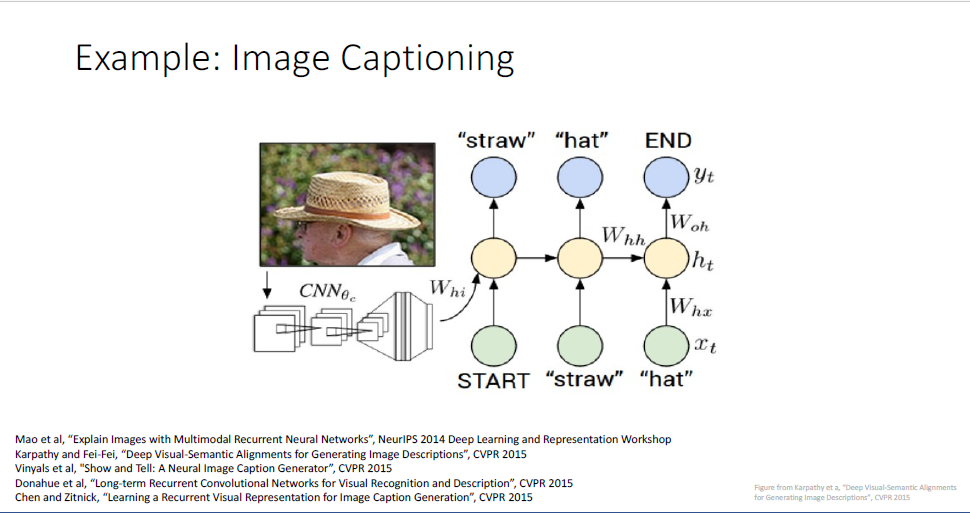
다시 컴퓨터 비전의 주제로 넘어와서 이야기하자면 Language model은 image captioning task에 활용할 수 있다.
여기서는 one to many problem으로 작동하게 되는데
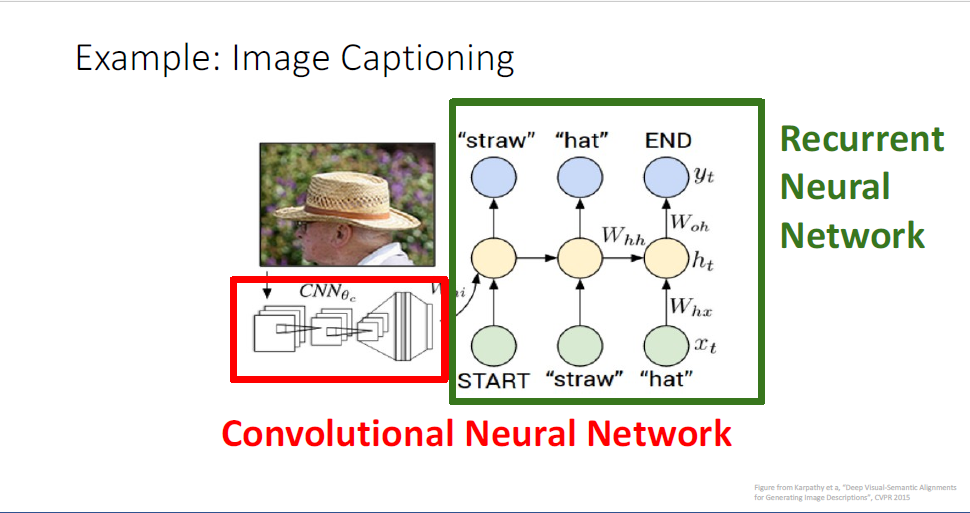
single image를 input으로 삼고, CNN에 이를 태워 feature를 뽑아낸다.
이후 feature를 Laungage model에 태워 이미지의 내용을 묘사하는 sequence를 생성하게 된다.
single image와 image의 내용에 대응되는 caption이 데이터셋으로 주어진다면 동일하게, 일반적인 gradient descent로 학습이 가능하다.

이 모델이 구체적으로 어떤건지 살펴보자.
이것은 transfer learning의 예시인데, 우선 ImageNet Classification에 사용된 pre-trained모델을 다운받고,
모델의 마지막 두 레이어를 쳐낸다.
이전 language model은 시퀀스길이가 고려대상이 아니었지만,
image captioning에서는 시퀀스를 유한한 길이로 제한한다. (명시적인 start와 end가 존재한다.)
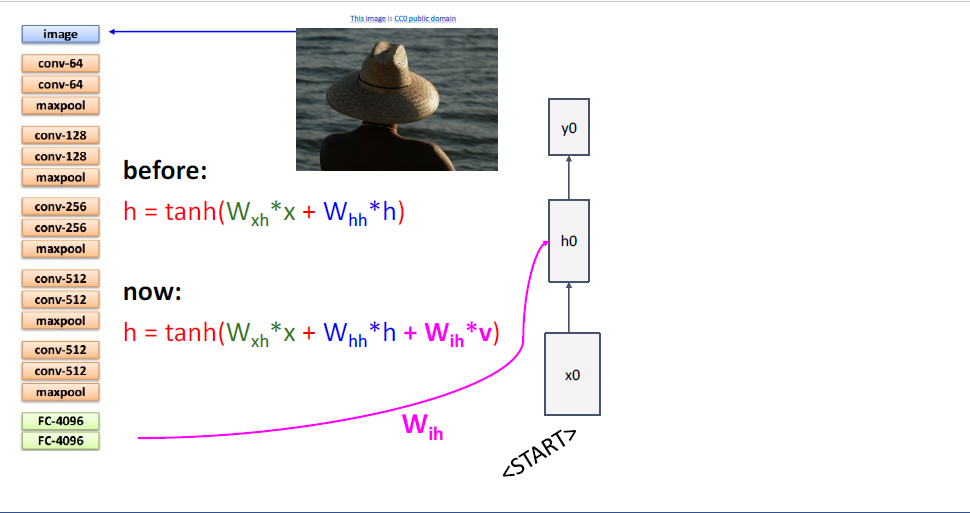
시퀀스는 항상 스폐셜 토큰인 <START>토큰으로 시작한다. <START>토큰은 생성하는 문장의 제일 첫번째 시퀀스 요소임을 알려준다.
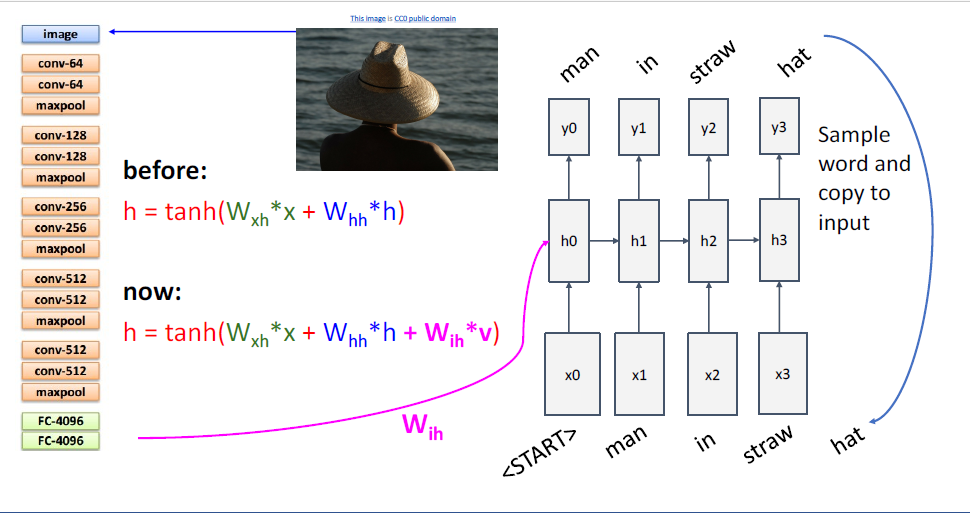
그리고 CNN과 RNN을 잇기위해서 reccurence formula를 살짝 바꾸어 사용한다.
이전에는
여기서는 CNN으로부터 extract된 feature를 hidden state와 매핑하는
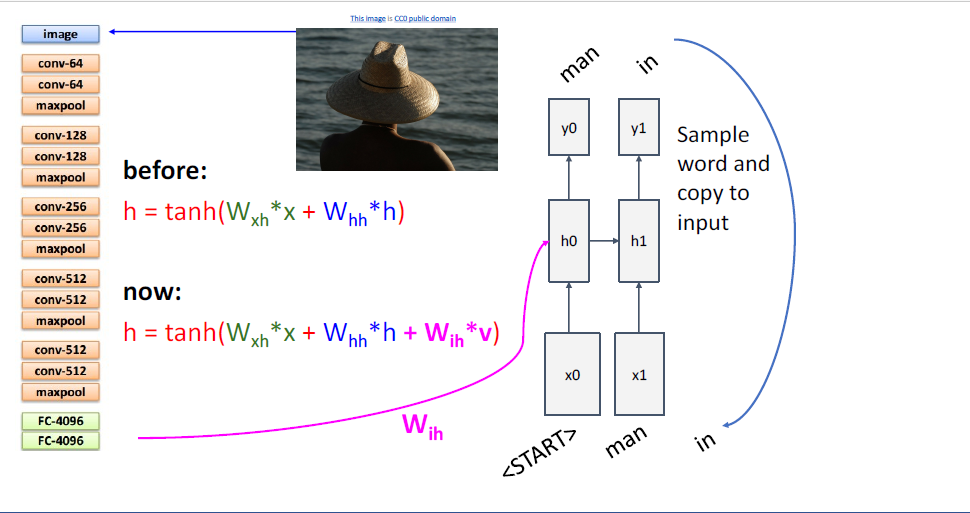
나머지 과정은 이전에 보던 RNN과 모두 동일하다.
test time에서는 다음 문자를 예측하는 prediction distribtuion을 통해 다음 타임스텝의 input을 주게되고, 반복 반복이다.
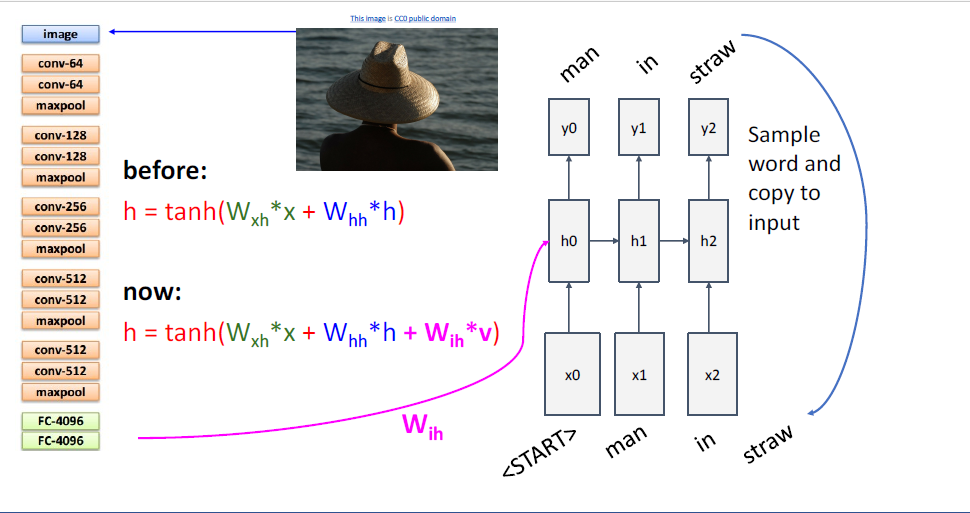
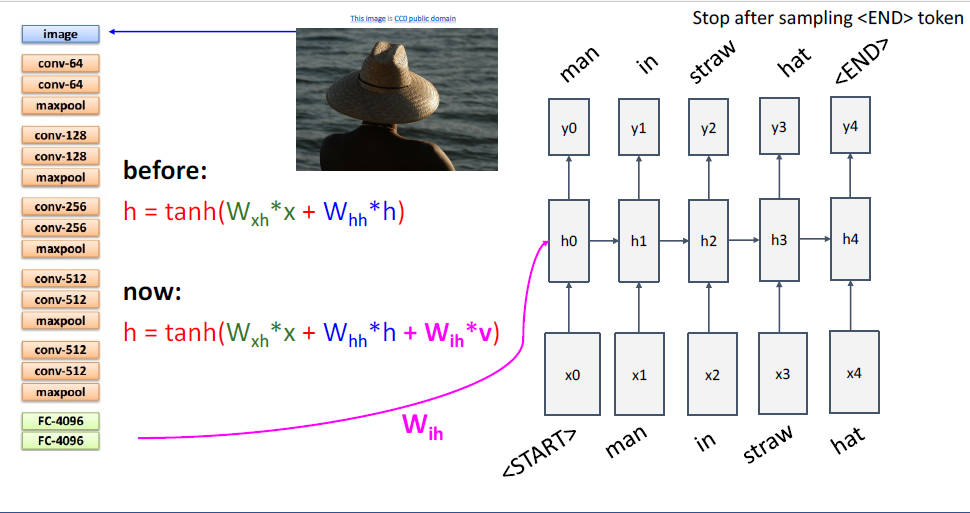
그리고 마지막엔 <END> token이 있다.
image captioning task를 포함하여, 이렇게 제한된 시퀀스의 길이를 다룰때에는 extra토큰인 <START>토큰과 <END>토큰을 포함하여 다루는 것이 일반적이다.

매우 훌륭한 묘사를 하고 있는 Image Captioing의 결과의 예시이다. (non-trivial description)

근데 image captioning model이 대단히 smart하지 않은 것이 알려졌는데,
첫번째 사진을 보면 여자의 coat의 질감을 고양이로 착각한 모양인지 'A woman is holding a cat in her hand'라고 묘사하고 있고,
또한 두번째 사진을 보면 아이폰을 들고 있는 모습을 computer mouse라고 착각하고 있거나,
세번째 사진처럼 물구나무 선 모습을 서핑보드를 타고 있다고 묘사한다거나 (아마도 물 근처에 서있는 모습은 서핑보드를 타고 있는 사람이 대부분인 데이터셋을 학습한 모양이다.) 하는 실패하는 경우가 매우 많다.
이러한 세밀한 차이는 모델에서 놓친 부분이다.
image captioning은 아직 완벽히 정복되지 않은 컴퓨터 비전의 task라고 할 수 있다.
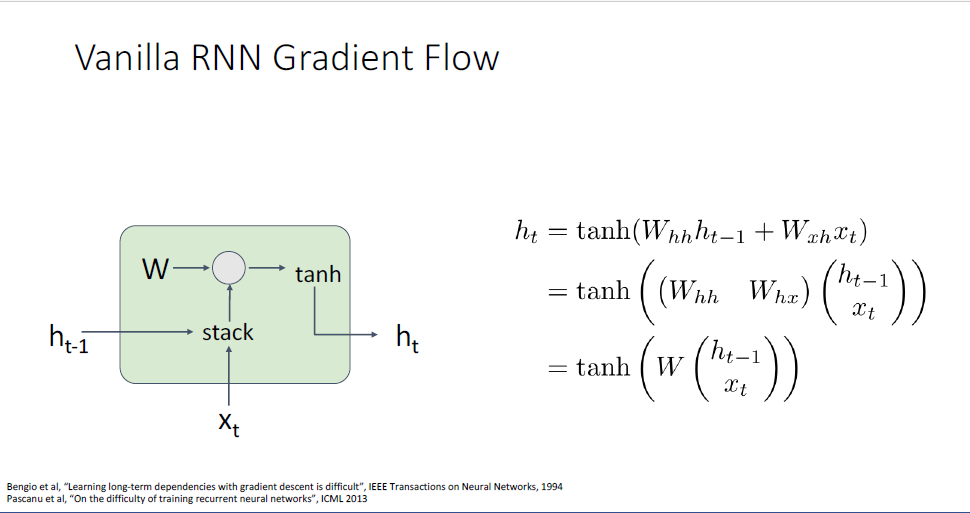
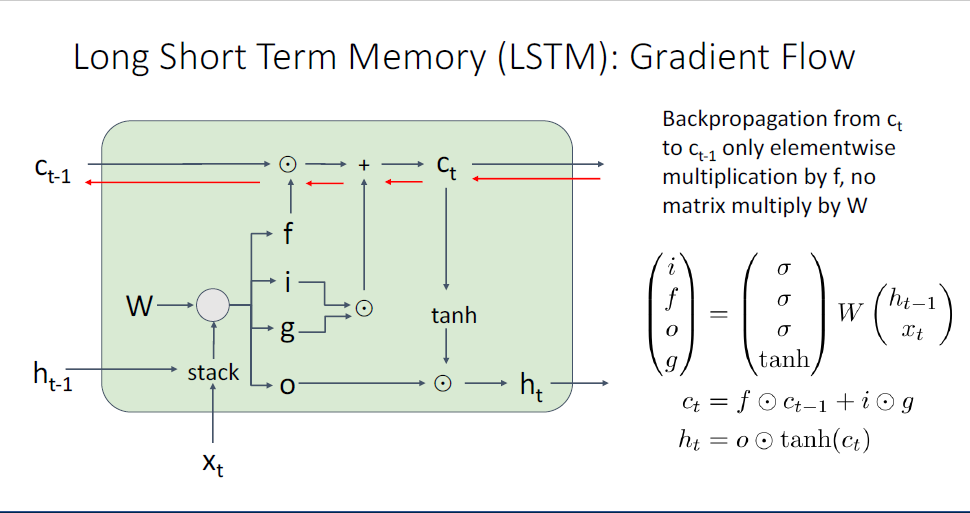
RNN에 대해 또 다루어야할 것은 gradient flow에 관한 부분이다.
보이는 그림은 단일 타임스텝에 대한 RNN Cell에 대한 묘사이다.
RNN이 backward pass동안 어떤 문제가 있을까?
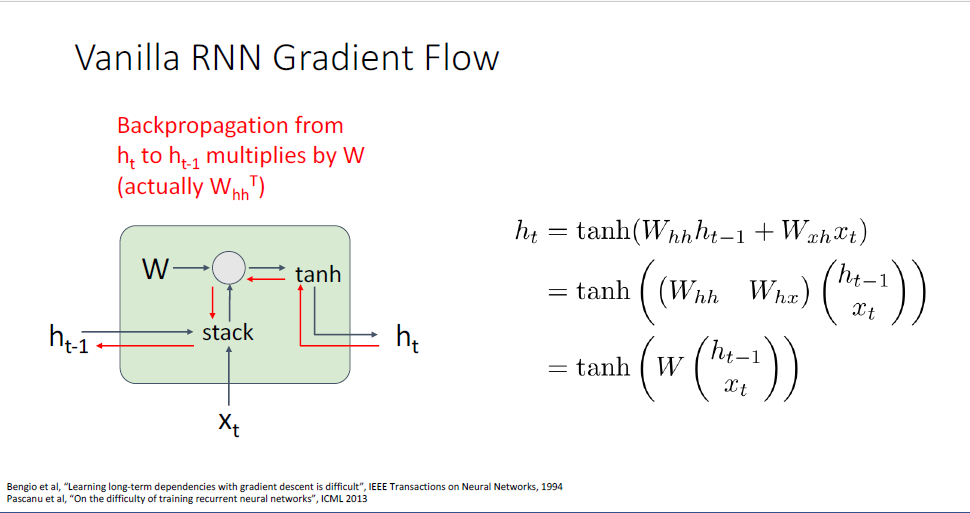
backward pass동안에 output hidden state
이를 통해 우리는
역전파동안 두가지 좋지 못한 성질이 있는데,
하나는 tanh의 활성화함수(nonlinearlity)를 사용한다는 것이고, (이전에 언급했듯 tanh를 반복하여 사용하는 것은 gradient vanishing problem이 발생한다.)
두번째 큰 문제는 matrix multiplication에 대한 역전파 진행시에 transpose weight matrix를 사용하여 계산한다는 점이다.
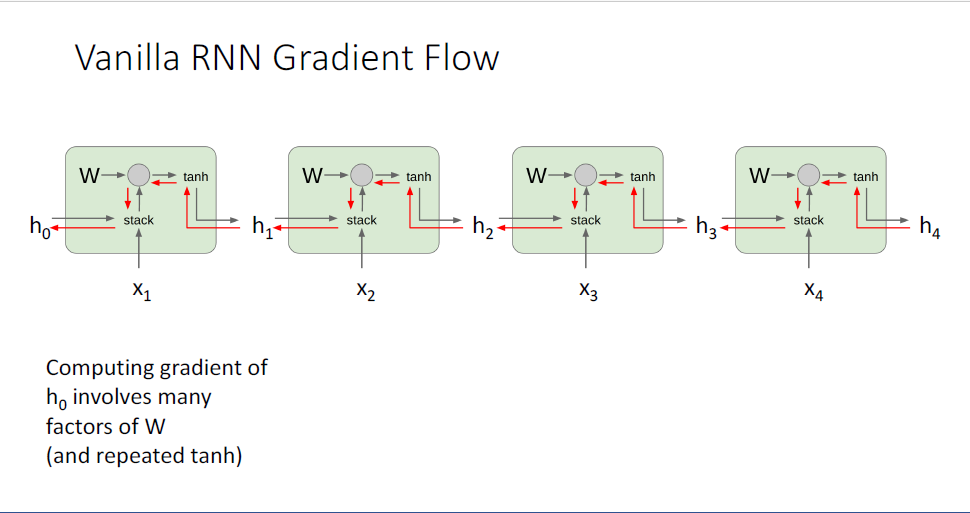
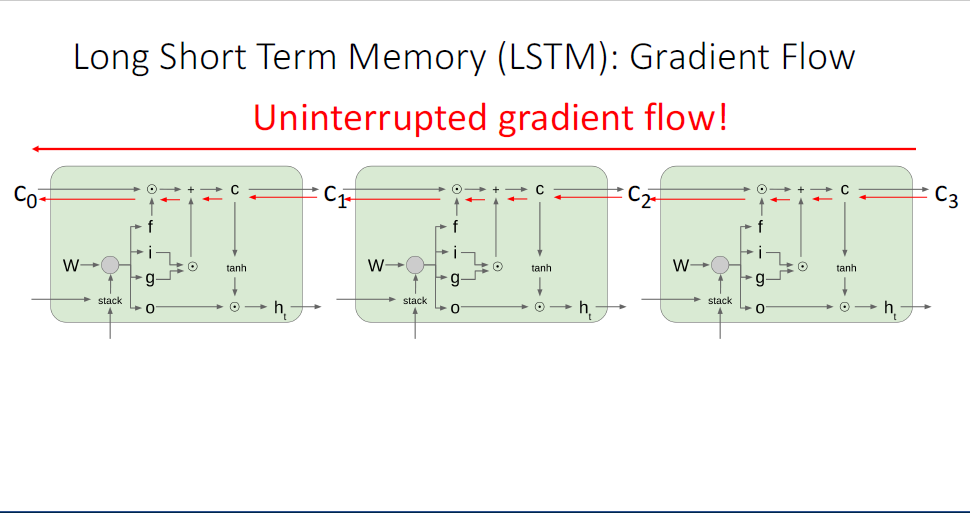
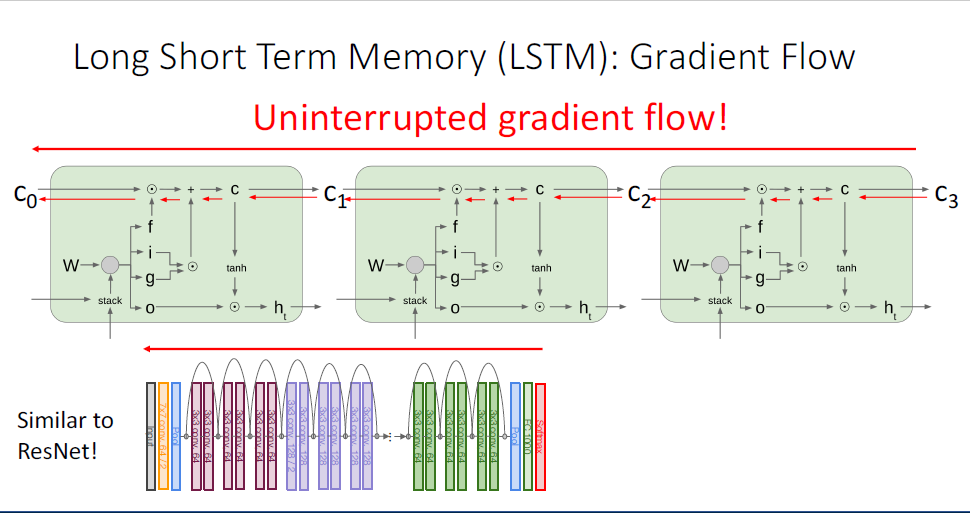
단일의 RNN Cell이 아니라 RNN을 풀어 헤친 형태에서 살펴보면 문제가 좀 더 명확해진다.
역전파 시에는 upstream gradient와
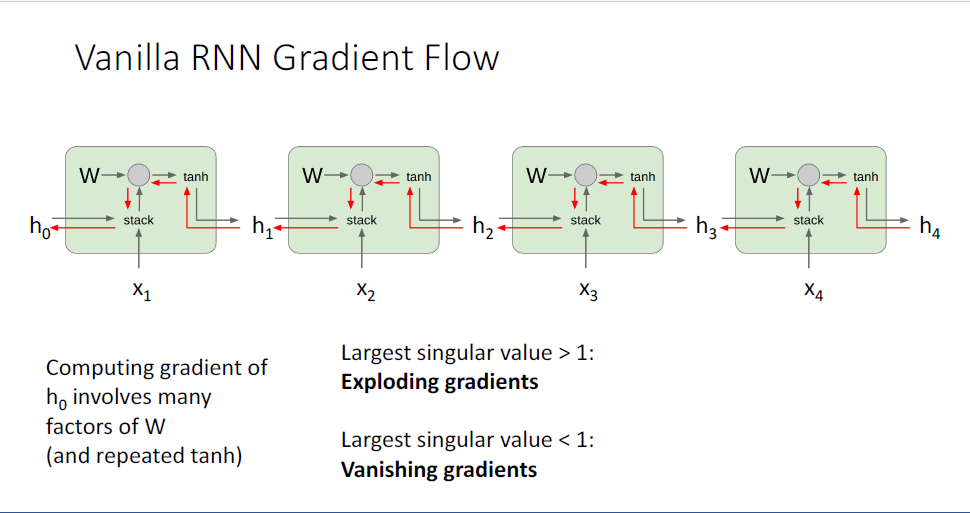
이러한 특징은 두가지의 문제가 발생하는데, matrix에 대한 특잇값(singular value)이 1보다 큰 경우에는 gradient가 무한대로 발산해버린다. 또한 1보다 작은 경우에는 vanishing gradient가 발생한다.
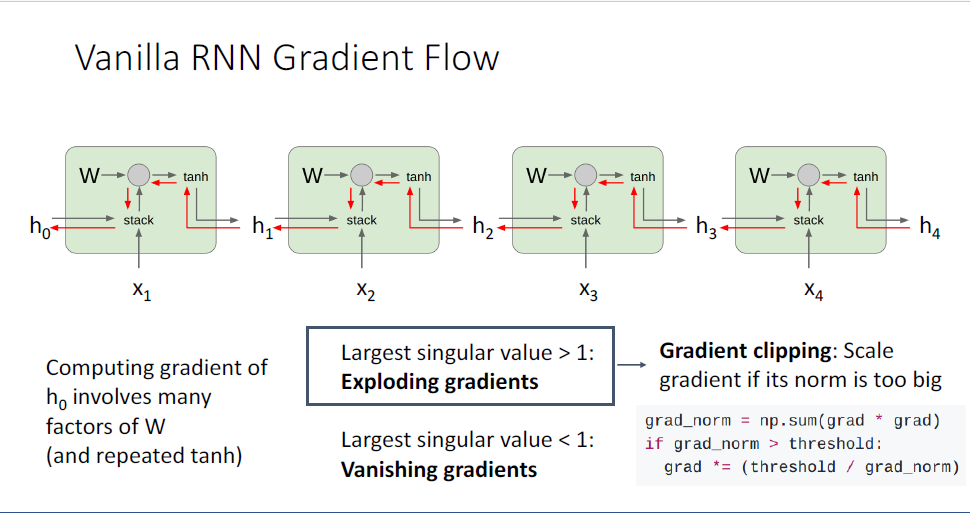
사람들은 안정된 학습을 위해서 exploding gradient problem에 대해서는 Gradient clipping이라는 전략을 사용하여 문제를 해결하곤 한다.
local gradient에 대한 euclidena norm을 활용하는데, hidden state에 대한 loss 미분값이라는 gradient가 벡터라는 점을 떠올려보자.
실제의 gradient값을 사용하는 것이 아닌 휴리스틱한 방법이라고 할 수 있겠다
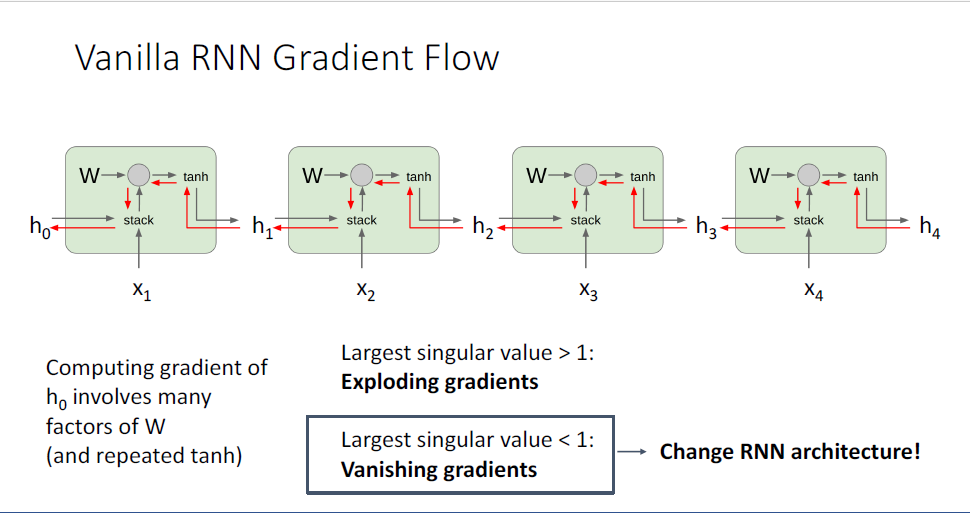
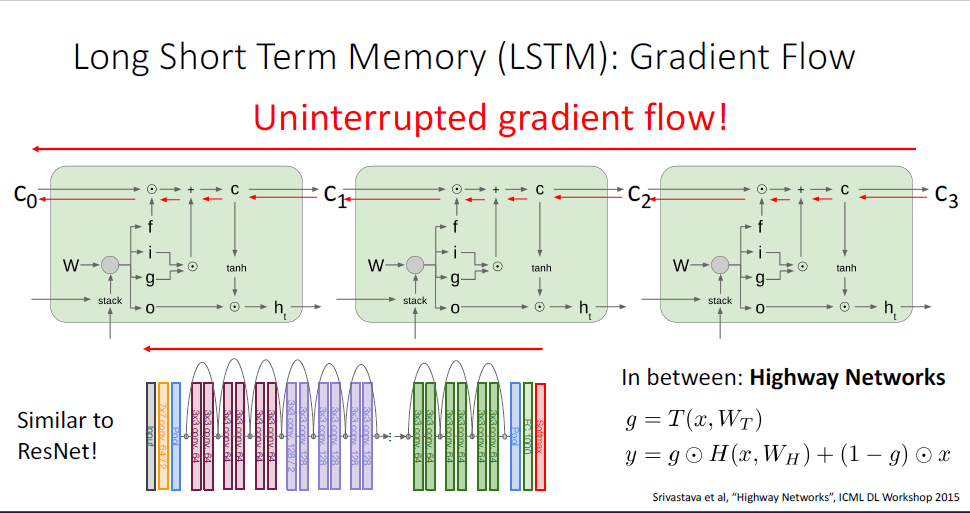
그럼 vanishing gradient problem은 어떤 방식으로 피할 수 있을까?
=이떄 사용하는 가장 간단한 방법은 현재의 모델을 버리고 다른 RNN아키텍쳐로 갈아타는 것이다. (..??)
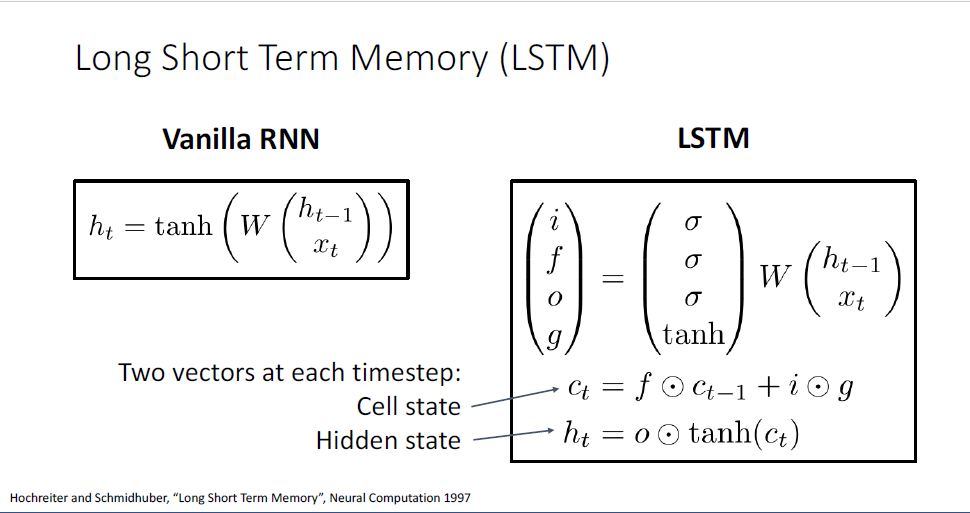
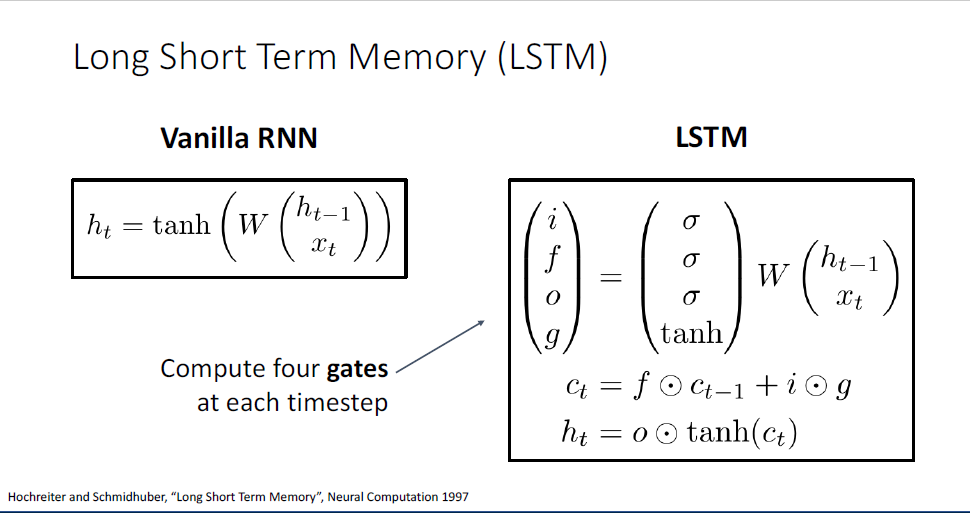
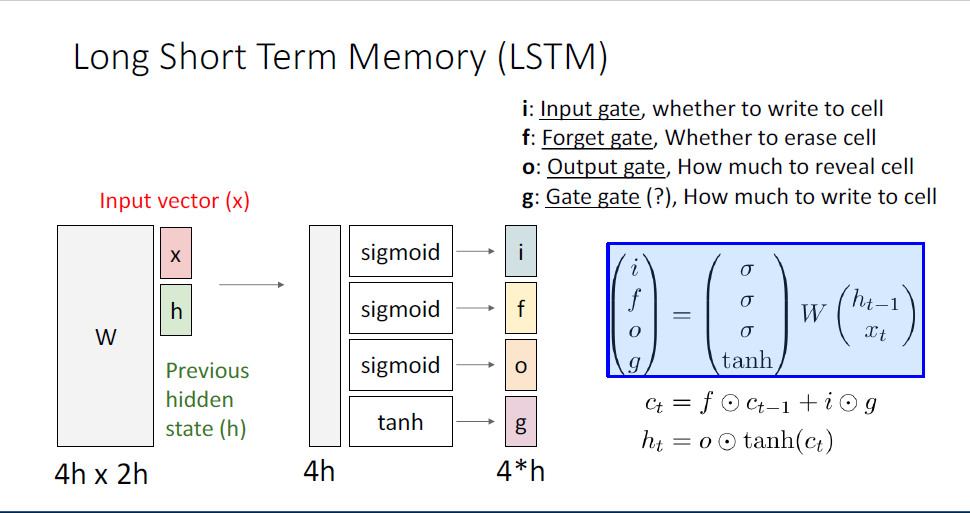
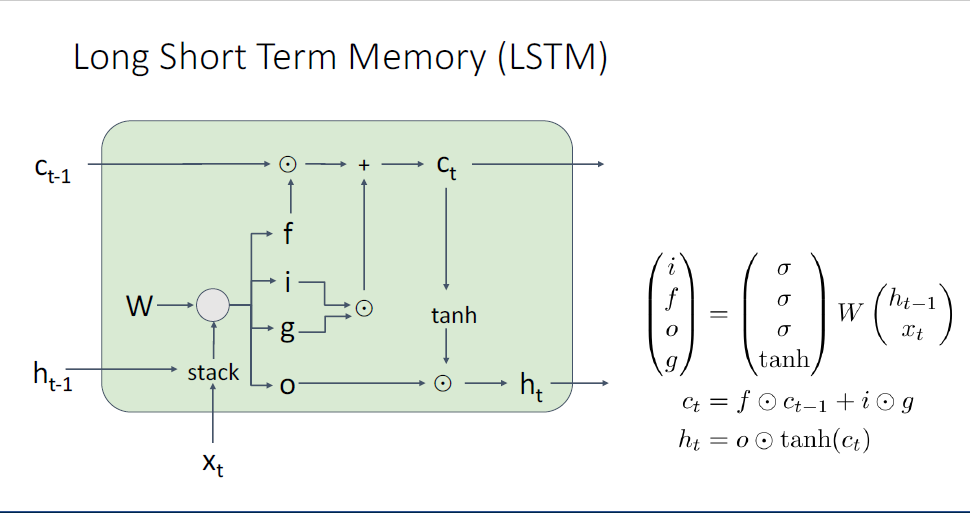
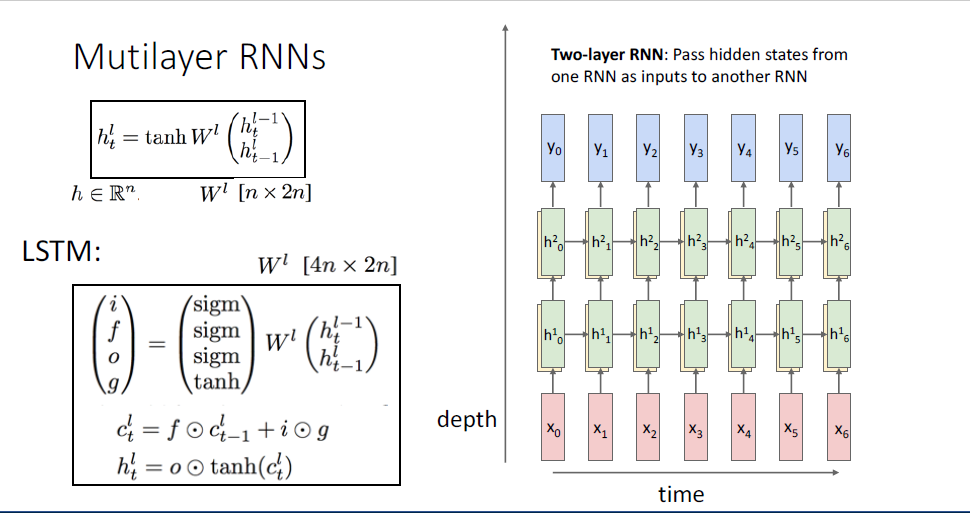
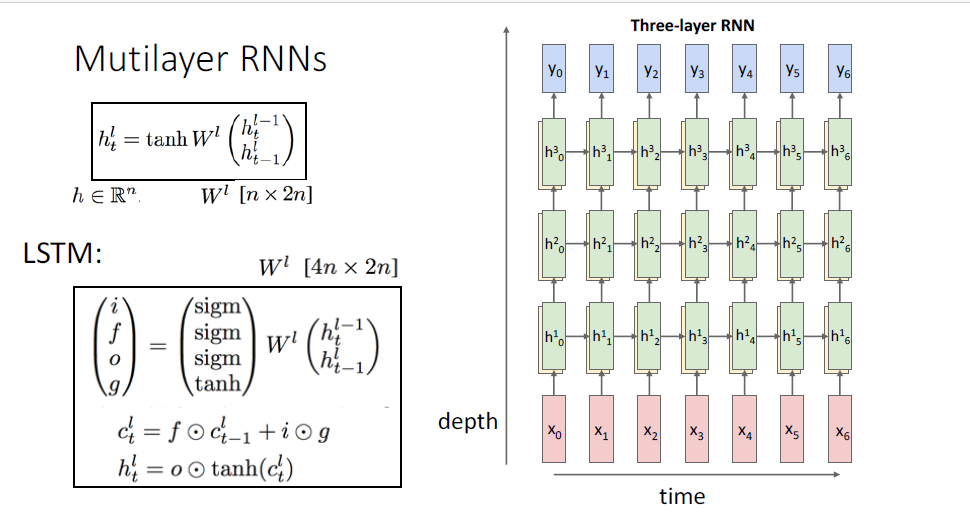
지금까지 다룬 RNN은 Vanilla RNN이고,
여기서 더 나아가 가장 흔하게 사용되는 RNN의 변형 버전인 Long-Short-Term-Memomry, LSTM이라는 모델이 있다.


'기초 노트 > EECS 498-007 (ComputerVision)' 카테고리의 다른 글
| EECS 498-007 Lecture 13 : Attention (0) | 2025.01.11 |
|---|---|
| EECS 498-007 Lecture11 : Training Neural Networks Part2 정리 (0) | 2025.01.11 |
| EECS 498-007 Lecture10: Training Neural Networks Part1 정리 (0) | 2025.01.11 |
| EECS 498-007 Lecture9 : Hardware and Software 정리 (0) | 2025.01.11 |
| EECS 498-007 Lecture 8: CNN Architectures 정리 (0) | 2024.04.02 |