
이번 강은 Attention에 대해서 다룬다.

지난 시간에는 새로운 구조의 NeuralNet인 RNN에 대해서 배웠다.
RNN은 서로 다른 시퀀스의 벡터를 다룰 수 있는 강력한 신경망 구조였다.
MLP와 같은 일반적인 Feedforward neural network(순방향 신경망)에서 Recurrent Neural Networks(순환 신경망)로 오면서 우리는 machine translation, image captioning과 같은 다양한 테스크를 해결할 수 있게 되었다.
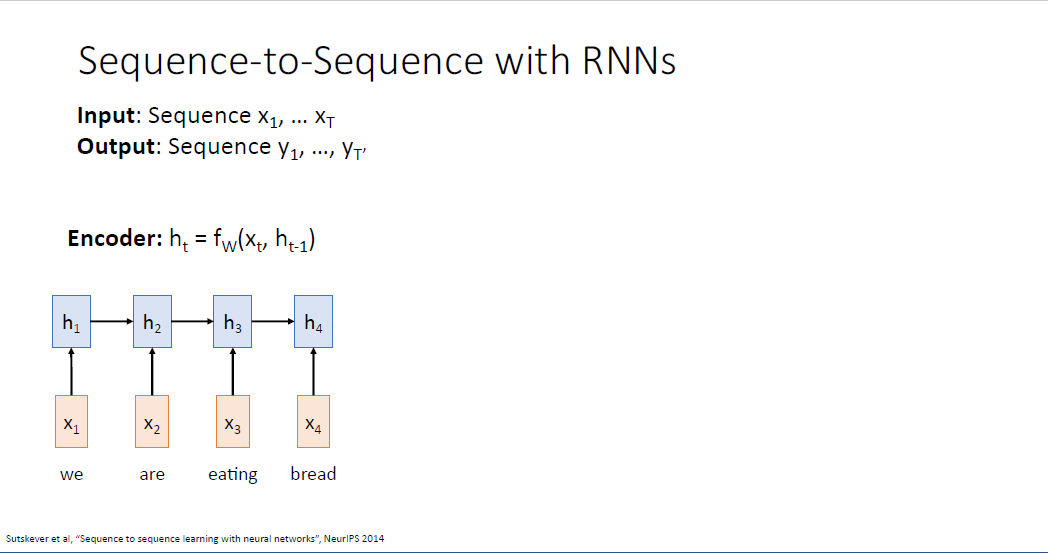
지난 시간의 내용을 다시 한번 떠올려보자.
sequence to sequence with RNN의 문제는 무엇이었을까
RNN은 $x_1$에서 $x_T$까지의 sequence를 입력으로 받는다.
output은 $y_1$에서 $y_{T^`}$ 이고 입력이 만약 영어 문장이라면 출력은 이에 대응되는 스페인어 문장과 같은 형식이었다.
서로 다른 언어는 같은 의미를 담는 문장이지만 서로 다른 길이 갖고 있다. 따라서 입력 $x$의 notation에는 $T$이고 출력인 $y의$ sequence noitation은 $ T^`$ 로 표시하였다.
이러한 task를 수행하는 하나의 RNN 네트워크를 인코더(Encoder) 라고 부르며, 인코더는 이전 스테이트의 정보 $h_{t-1}$과 input sequence의 정보 $x_t$를 받아 $f_w$를 통해 현재 타임 스텝 $t$에서의 히든스테이트 $h_t$를 만드는 구조이다.
이렇게 하나의 RNN 인코더를 구성해서 전체 시퀀스를 처리할 수 있다.

이것이 어떻게 작동하는지 세부사항을 더 알아보자.
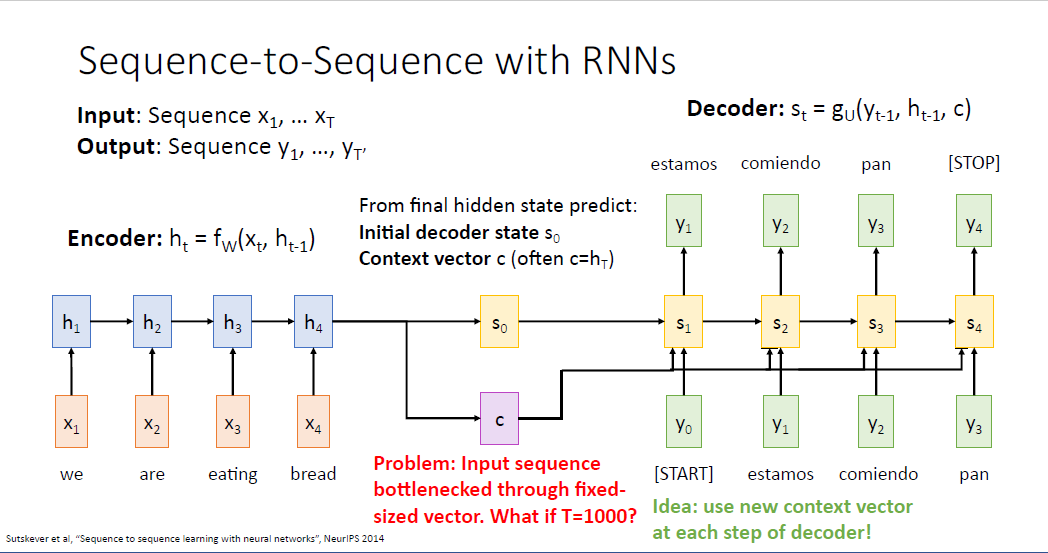
우리가 input vector를 처리할때, 전체 문장의 내용을 어떤 두가지의 요약 정보로 담기를 원하는데
하나는 디코더(Decoder)의 최초의 히든 스테이트인 $s_0$이고, 또 하나는 디코어의 모든 히든스테이트에 전달되는 context vector라고 불리는 $c$ 이다. 보통은 context vector를 마지막 히든 스테이트 값인 $h_T$로 설정하고
$s_0$는 보통 마지막 full connected layer의 예측값으로 설정하곤 한다.

디코더는 최초에 [START] 토큰 $y_0$을 입력으로 받아 문장을 생성한다. 또한 앞선 context vector $c$와 디코더의 initial hidden state인 $s_0$를 입력으로 받아 $s_1$를 계산한다.
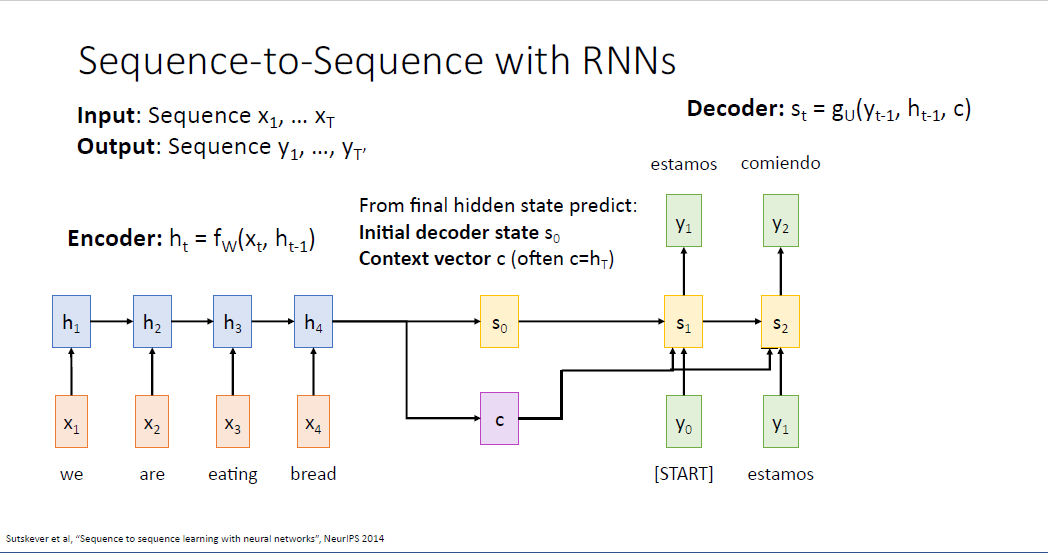
다음 time step에서도 마찬가지로 이전 히든 스테이트 벡터와 입력 시퀀스 벡터를 받아 문장을 생성한다.
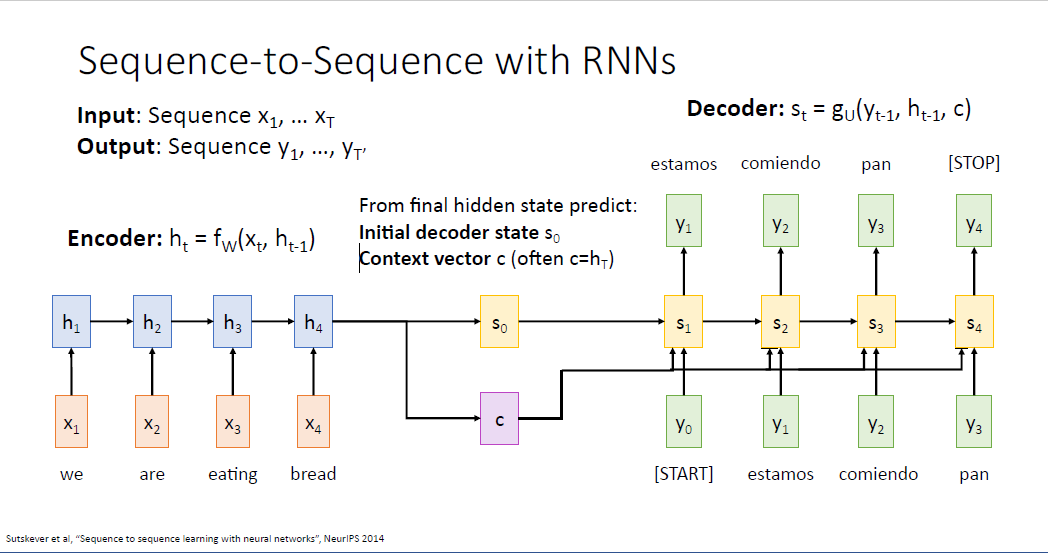
여기서 주목할만한 것은 context vector의 역할이다. context vector는 디코더가 단어를 생성해 낼 때 필요한 모든 정보를 요약하여 담길 원하고 디코더의 모든 time step에 input으로 사용된다.
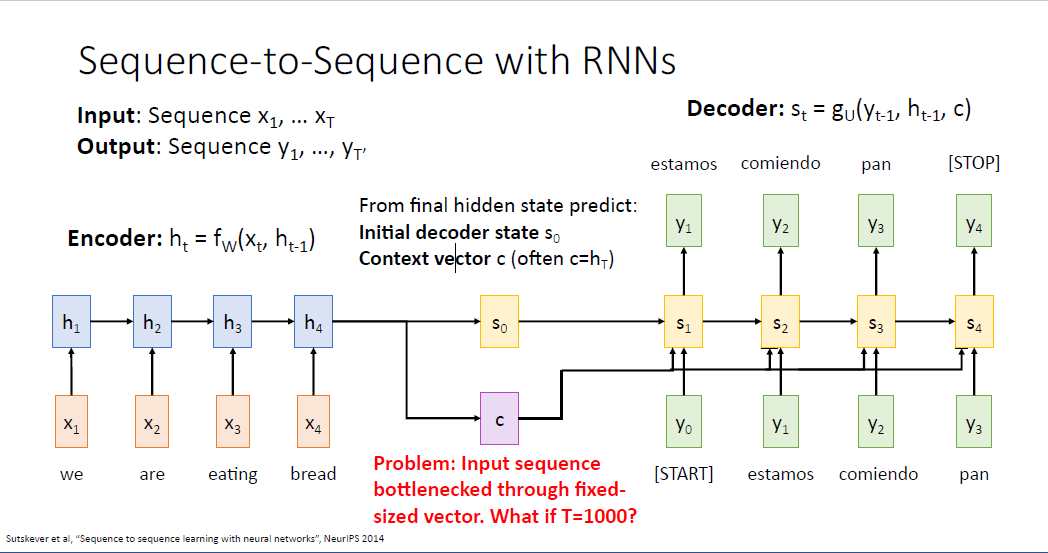
그런데 바로 여기서 문제가 생긴다. 만약 입력 시퀀스의 길이가 매우 매우 길어지면, 예를 들어 $T=1000$이 되면 어떻게 될까? 문장이 아닌 어떤 단락이나 책 전체를 번역하는 작업에서는 이러한 네트워크는 문제가 생긴다.
단일의 context vector 하나로는 이러한 전체 단락과 책 전체의 내용을 담기 어렵다. 이러한 문제를 바틀넥 문제라고 부른다.
여기서 아이디어는 단일의 context vector를 사용 하는게 아니라, 매 스텝의 디코더에 서로 다른 context vector를 계산하는 것이다. 그렇게 되면 디코더의 매 스텝에서 컨텍스트 벡터는 단락의 어느 부분에 집중해야 하는지에 대한 능력을 갖게 된다.
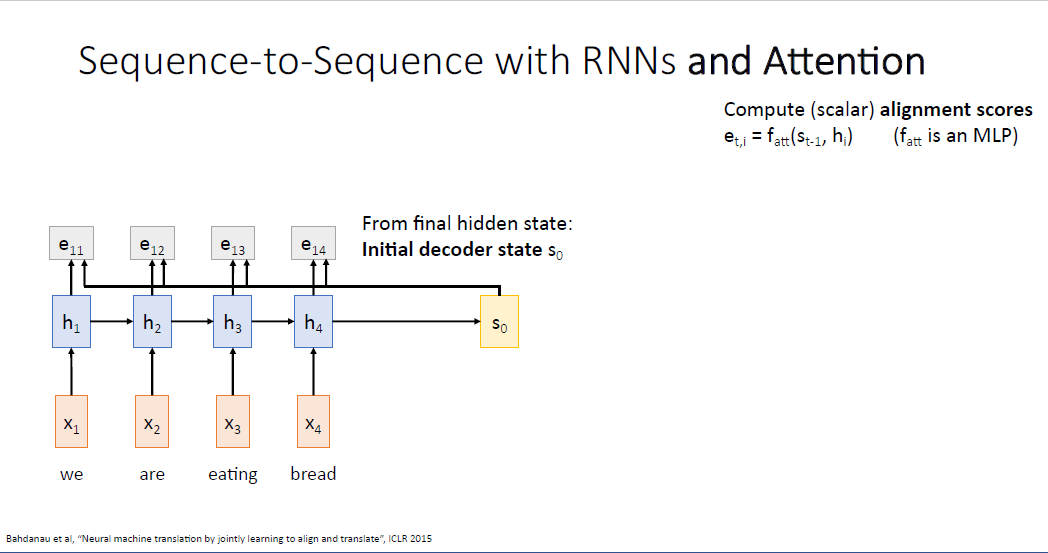
이것이 바로 Attention이라고 불리는 메커니즘이다. 이 세팅에서 여전히 Encoder에서 RNN을, Decoder에서도 RNN을 사용한다. 유일한 차이는 어텐션 메커니즘을 사용하여 디코더의 매 타입스텝에 새로운 컨텍스트 벡터를 계산하는 것이다.
여기서 디코더의 intial hidden state를 도입하기 위해 인코더의 예측값인 $s_0$ 를 사용하는 것 까지는 같다.
이전 Sequence to Sequence 아키텍쳐와 어텐션 메커니즘이 다른점은 "aligment function"이다.
alignment function은 슬라이드에서 $f_{att}$라고 notation된 부분이며 매우 작은 MLP이다.
$f_{att}$ 는 입력으로 디코더의 현재 타임스텝의 히든 스테이트 값과, 인코더의 각 히든 스테이트 값을 받는다.
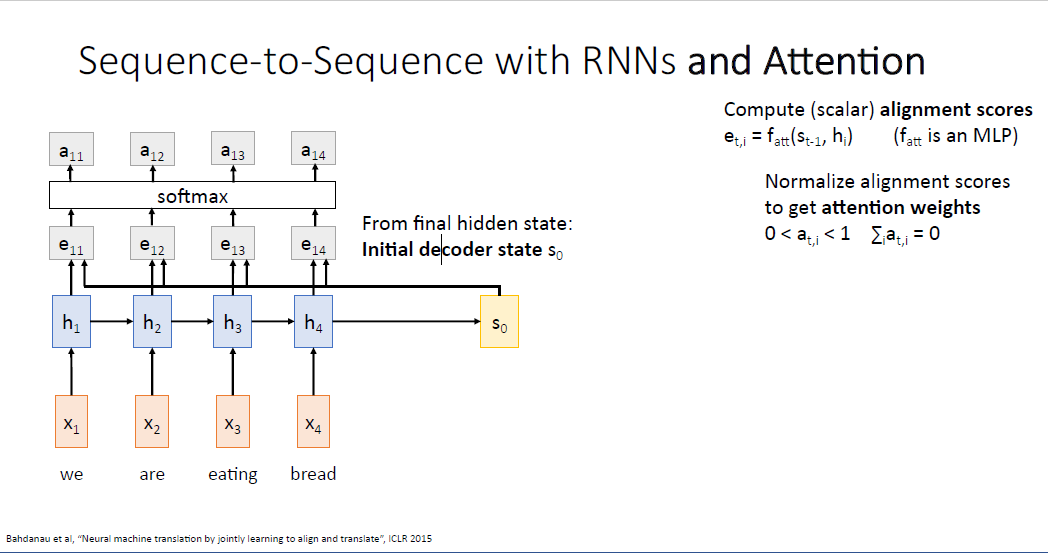
이렇게 계산된 alignment score는 decoder의 현재 스테이트가 각각의 encoder의 히든 스테이트에 얼마나 "attend" 해야되는지를 점수로 알려주는 것과 같다. 이렇게 계산된 값은 디코더의 매 스텝에 새로운 컨텍스트 벡터로서 작용한다.
처음으로 계산되는 $e_11$는 $f_{att}$ 를 통해 $s_0$와 $h_1$를 입력받고, $t=1$시점의 디코더가 인코더의 첫번째 입력 시퀀스에 얼마나 집중(attend)해야되는지를 알려준다.
$f_{att}$를 통해 계산되는 alignment score $e_{t,i}$는 실수값인 스칼라값이다. $s_1$를 계산한 것처럼, 동일한 방식으로 $s_2, s_3 ... s_{T^`}$ 가 계산된다. 계산된 alignment score는 이후 소프트맥스를 통과해 확률 분포(probabillty distribution)로 다루게 된다. 소프트맥스를 통과하여 sum to 1의 성격을 갖고 확률로서 다룰 수 있게 해준다.
이러한 확률분포는 attetion weights라고 부른다. 각각의 hidden state에 얼마만큼의 집중을 해야되는가를 말하기 때문이다.
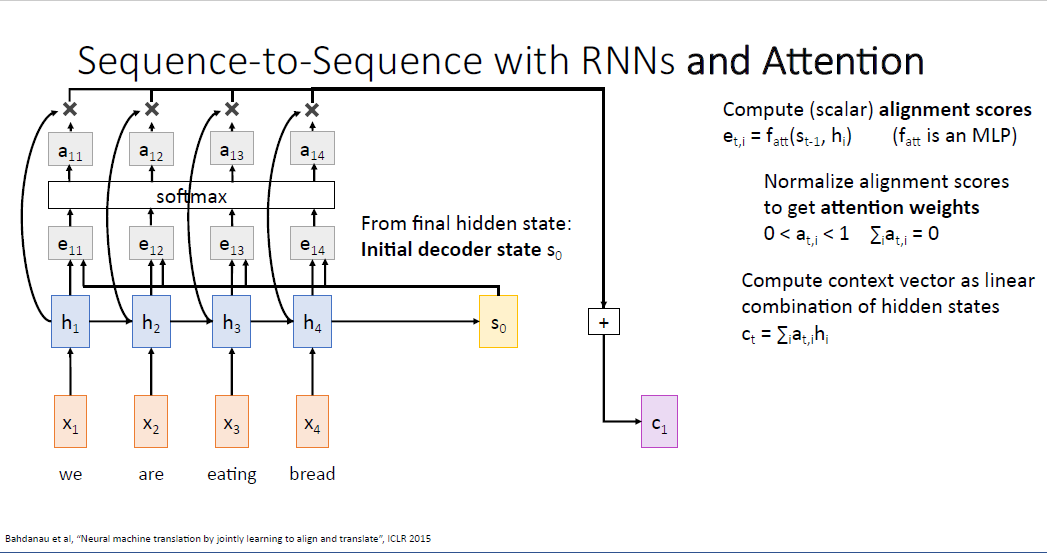
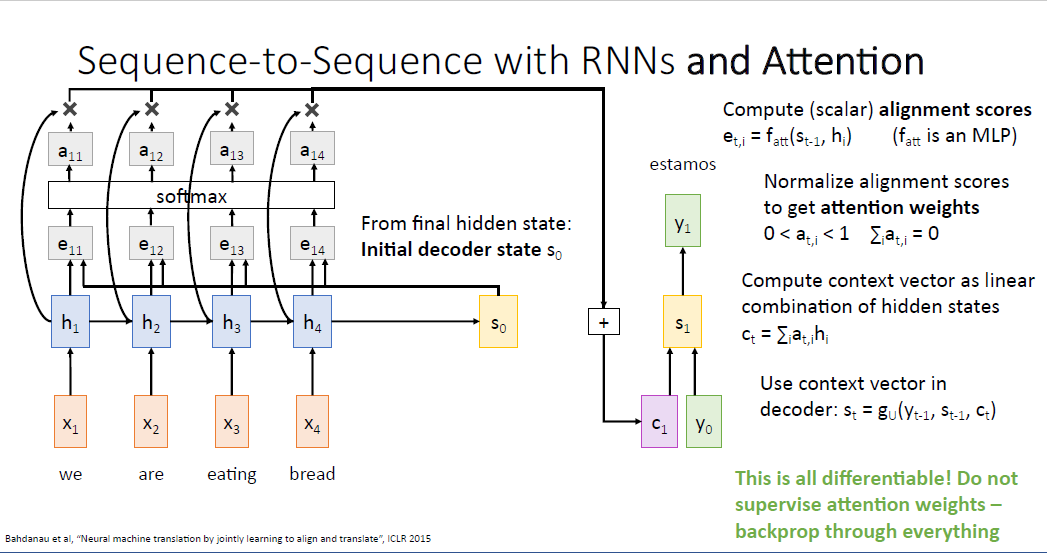
다음 단계로 인코더의 시퀀스로부터 만들어진 각 히든스테이트들과, 계산된 attetion weights를 가중합하여 context vector를 만들게 된다.
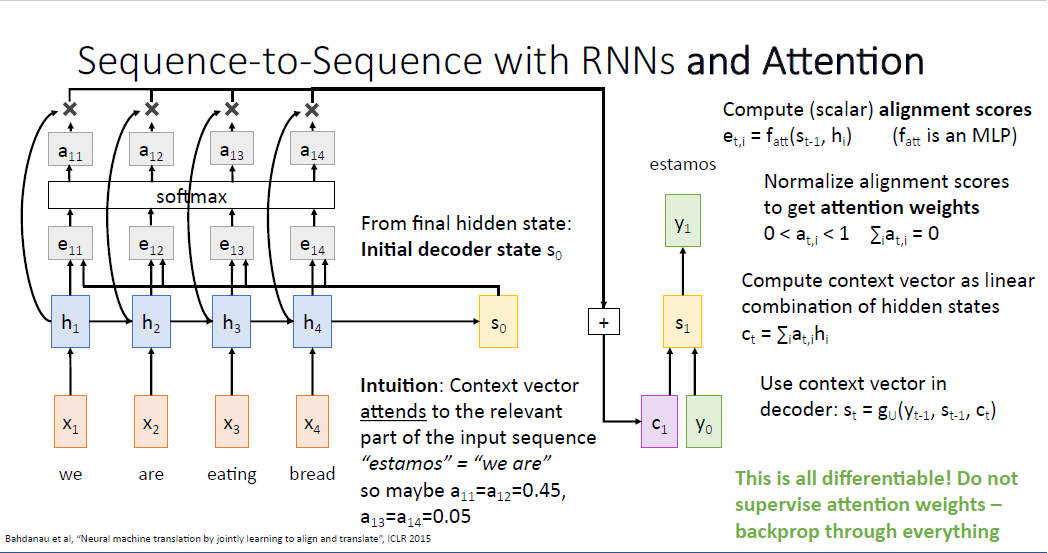
이후에 Decoder의 첫번째 타임스텝을 실행할 수 있게 된다. 계산된 $c_1$과 [START] 토큰인 $y_0$를 이용해서 첫번째 결괏값 $y_1%을 만들게 된다. 여기에 직관을 더하자면 attention weight를 통해 디코더의 히든 스테이트는 입력 시퀀스의 문장중 하나 혹은 하나 이상의 단어에 대해 중요한 부분에 집중을 할 수 있게 된다. 예를 들어 스페인어 "estamos"는 무언가 하고 있다(doing something)과 같은 뜻이기 때문에 디코더는 입력 시퀀스의 첫번째와 두번째 부분인 "we", "are"에 동일하게 각 $a_{11}=a_{12}=0.45$로 높은 집중을 할 것이다.
두번째 포인트는 이 과정이 모두 미분 가능하다는 점이다. 우리는 네트워크에게 어떤 부분에 집중하라고 정보를 주지 않는다. 단지 네트워크가 어떠한 부분을 봐야하는지를 스스로 결정할 뿐이다. 거대한 computational grpagh를 만들고, 순전파를 흘리고, 역전파를 수행하여 optimization되면 네트워크가 스스로 이러한 부분을 학습하게 된다.
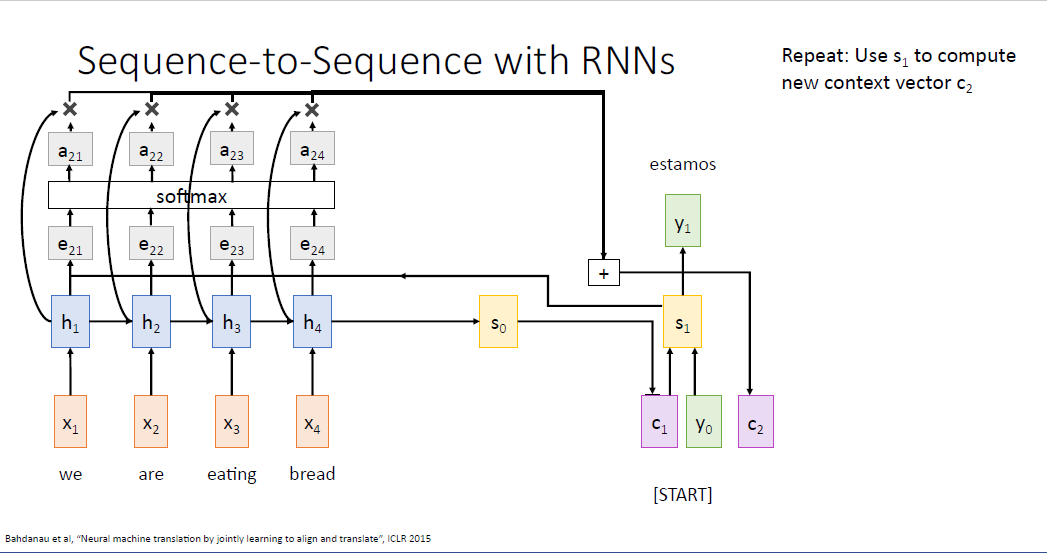
이제 $s_1$이 만들어 졌으니 동일한 방식으로 $e_{21}, e_{22}, e_{23} , e_{24} $를 계산할 수 있고 두번째의 컨텍스트 벡터 $c_2$도 동일하게 계산할 수 있다.
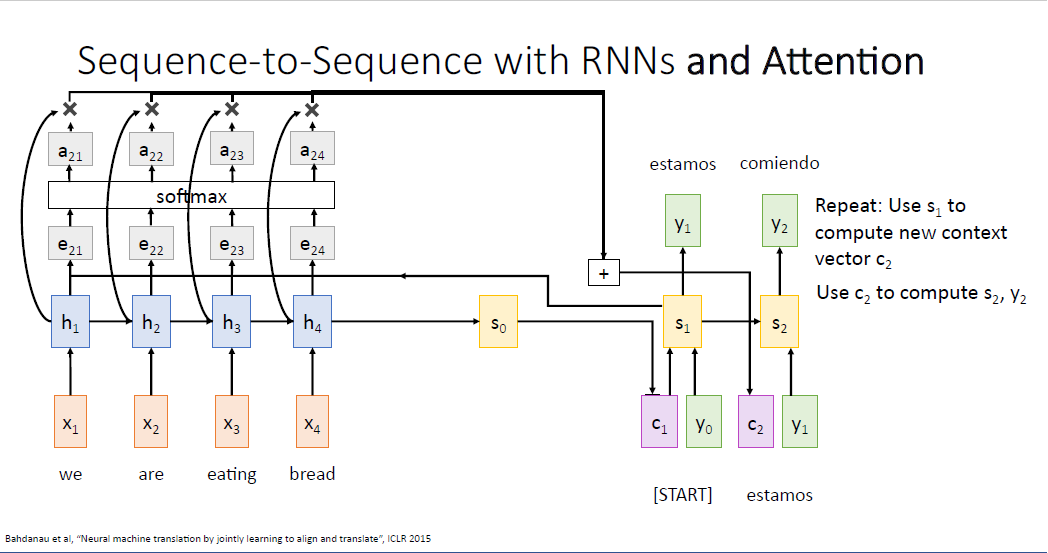
feed forward를 수행하면 디코더의 두번째 히든 스테이트 $s_2$가 만들어지게 되고, 계속 계속 반복이다.
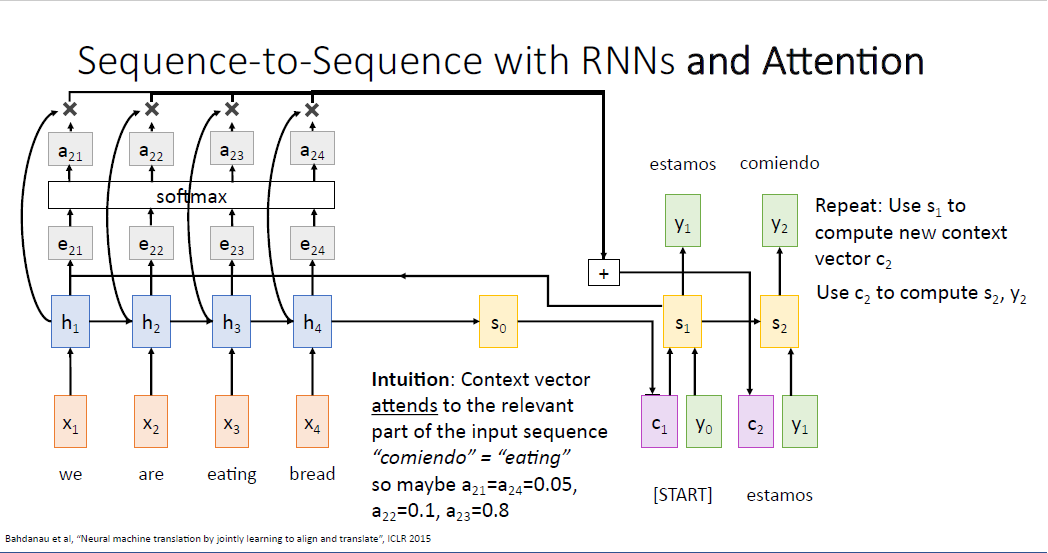
두번째 만들어진 단어인 'comiendo' 는 무언가 먹는다는 뜻이어서, 아마도 네트워크는 'eating'에 더욱 집중하도록 학습될 것이고, 대응되는 $a_{23}=0.8$로 높은 값을 가질 것이다.
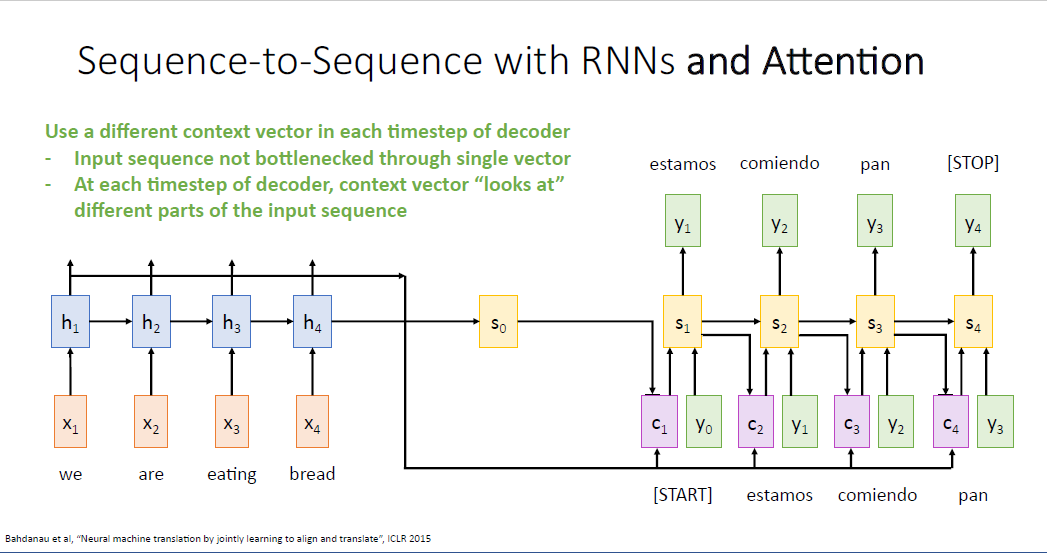
지금까지의 과정은 Sequence to Sequence Learing with Attetion이다.
RNN만을 이용한 vanilla sequence to sequence 모델의 context vector의 바틀넥 문제를 해결하였다.
다시 한번 반복하자면 단일의 context vector에 입력 시퀀스의 모든 정보를 담는 것이 아니라, 디코더의 매 각 스텝에 어떤 부분에 집중해야하는지 유연성을 부여 하였다.

Attention의 장점은 attention weight의 시각화를 통해 model이 어떤 부분에 집중하는지 해석력을 제공한다는 점이다.
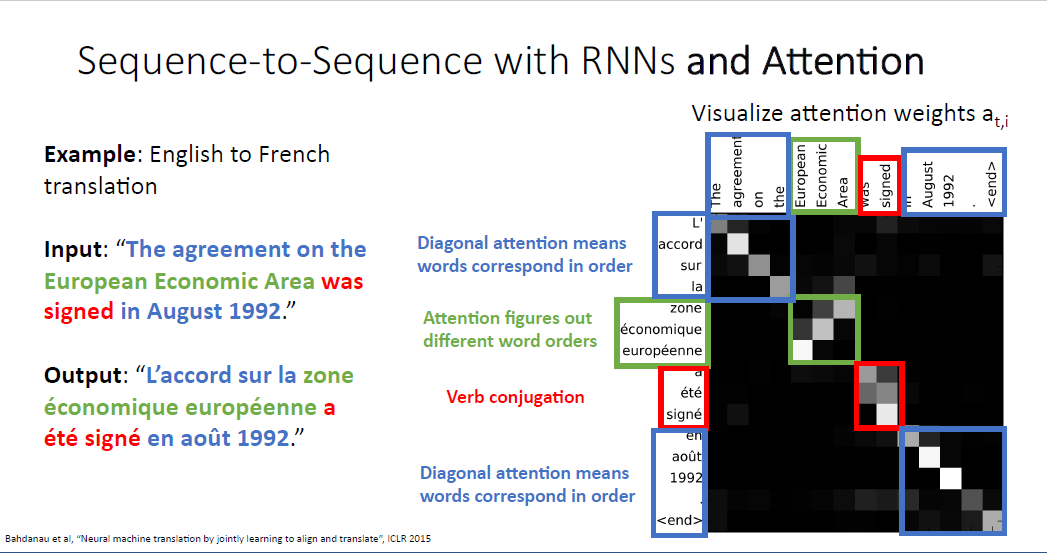
어떤 부분은 순서대로 대응되는 모습을 보이지만, 어떤 부분은 순서가 뒤집힌 부분도 있다.
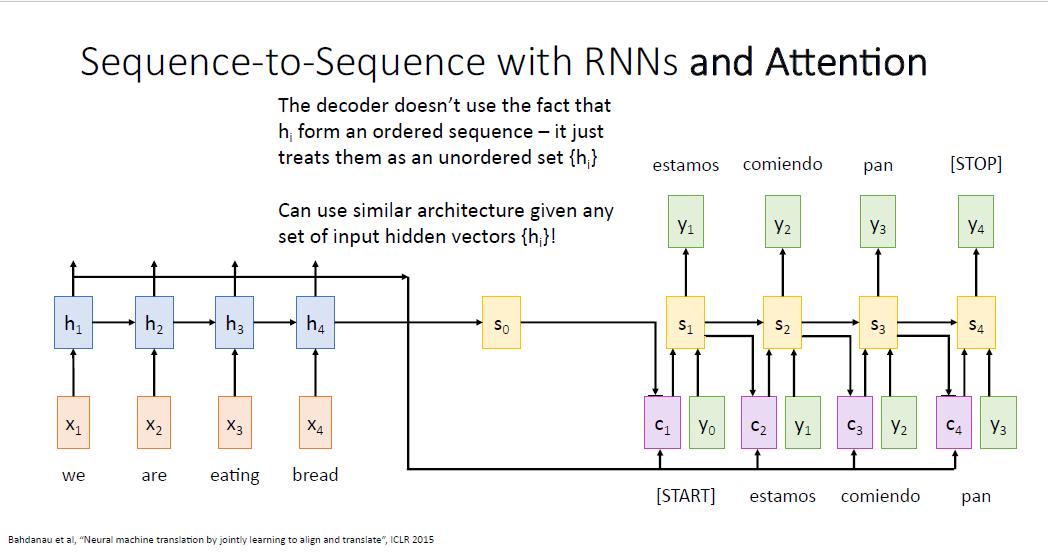
지금까지 설명한 어텐션 메커니즘에서 한가지 주목할만한 점은, 어텐션 메커니즘은 사실 input이 sequence의 형태든 아니든 상관이 없다는 점이다. 어텐션 메커니즘은 디코더의 input이 그저 어느 state에 집중할지를 결정하는 연산이기 때문에 지금과 같은 machine translation task의 예시 처럼 input data가 시퀀스 형태일 필요가 없다.
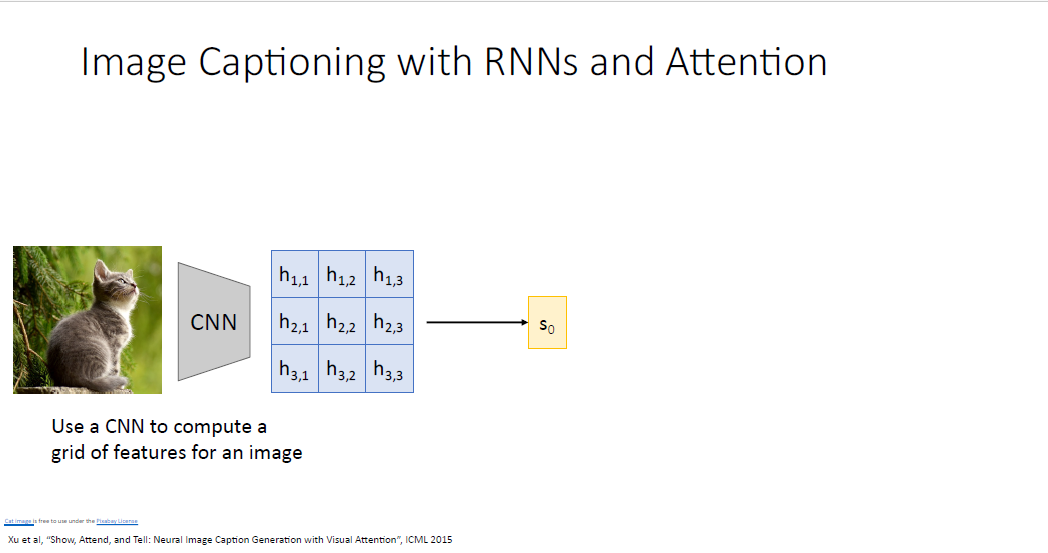
image를 input 받는 CNN을 떠올려 보자. CNN은 이미지를 input으로 받아서 어떠한 피처벡터의 그리드 형태인 feature vector(activation map)을 만들어 낸다. feature vector가 무슨 이미지인지 알아보기는 힘들겠지만 아무튼 이 벡터는 공간적 정보를 담고 있다.
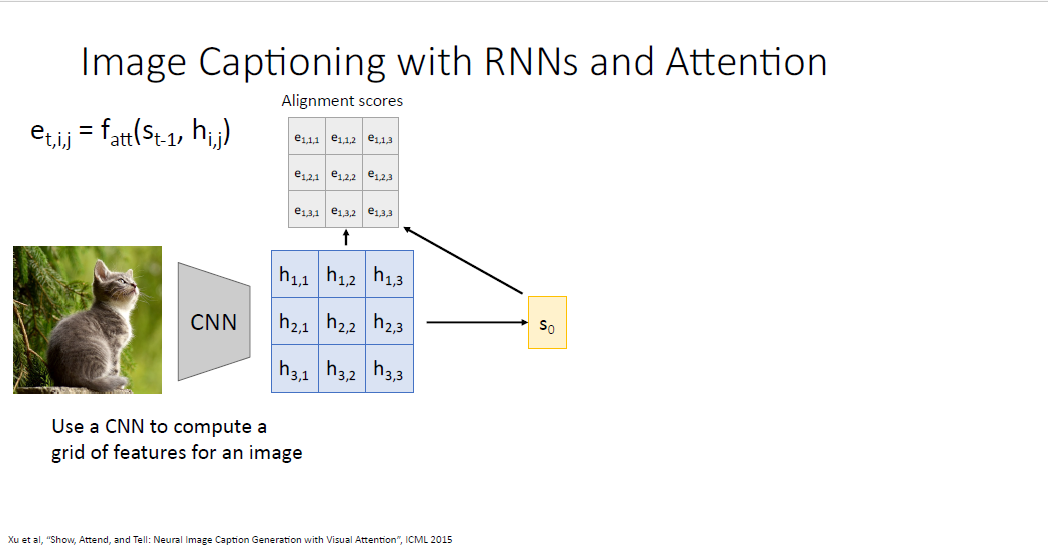
시퀀스 모델에서 했던것 처럼 그대로 여기에 어텐션 메커니즘을 적용해보려고 한다.
피처 그리드를 통해서 디코더의 initial hidden state $s_0$를 예측하고,
$s_0$와 피처 그리드를 $f_att$의 input으로 피처 그리드와 pair wise로 대응되는 Alignment score를 계산한다.
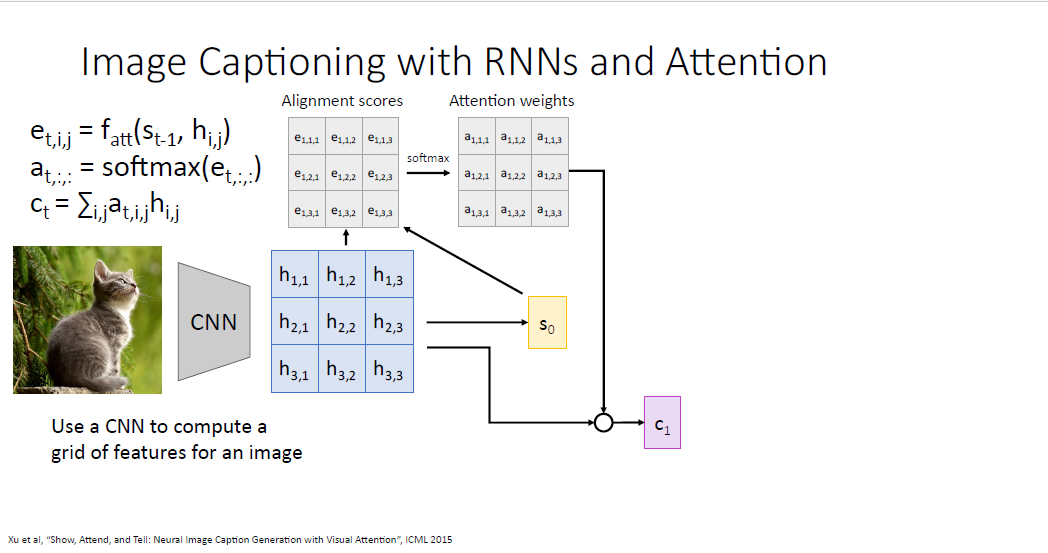
동일하게 softmax를 통과시켜 Attention weights를 얻고 피처 그리드와 가중합을 통하여 context vector를 얻는다.
나머지 과정은 machine translation과 완벽하게 동일하다.
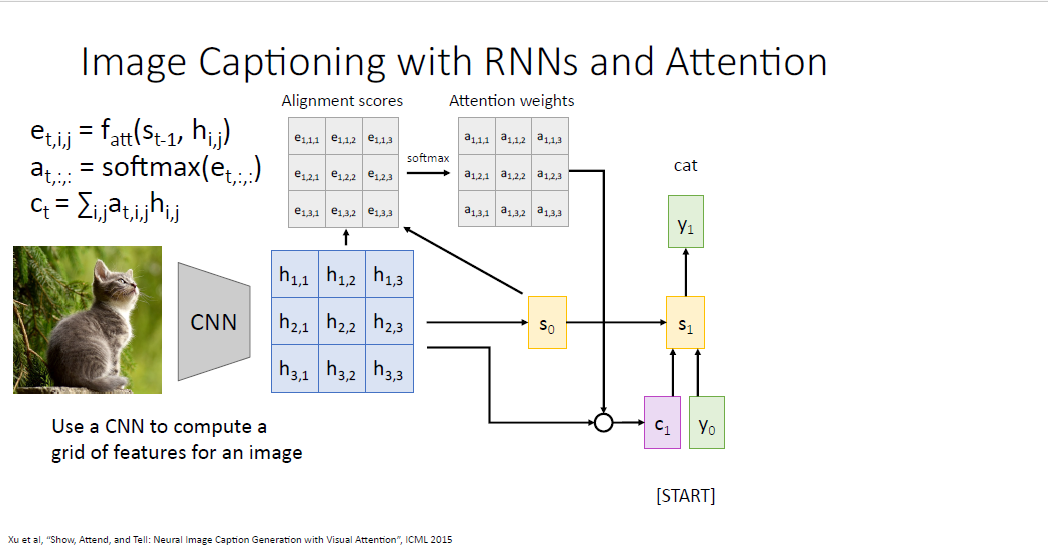
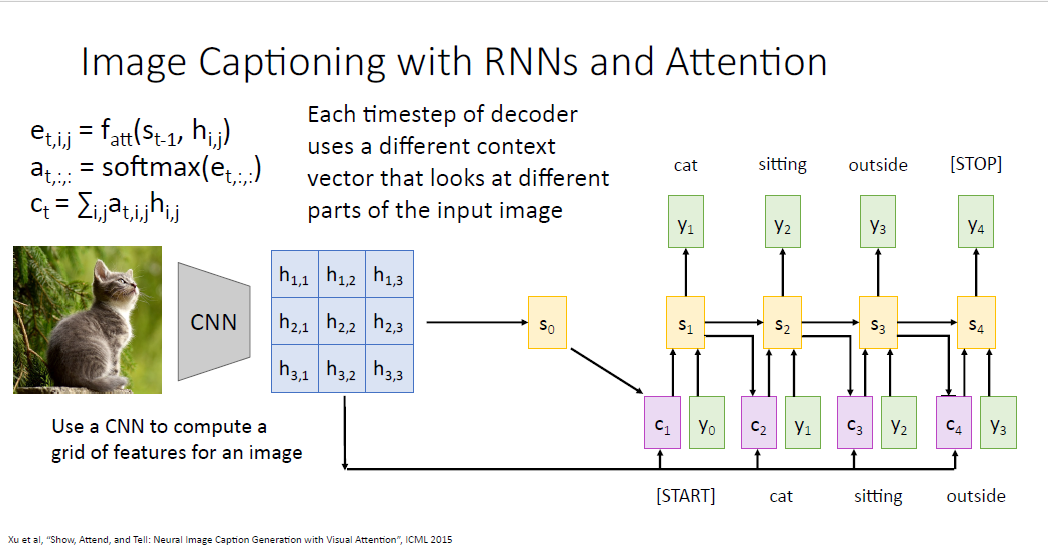
단어의 생성 결과는 image에 대응되는 caption이다
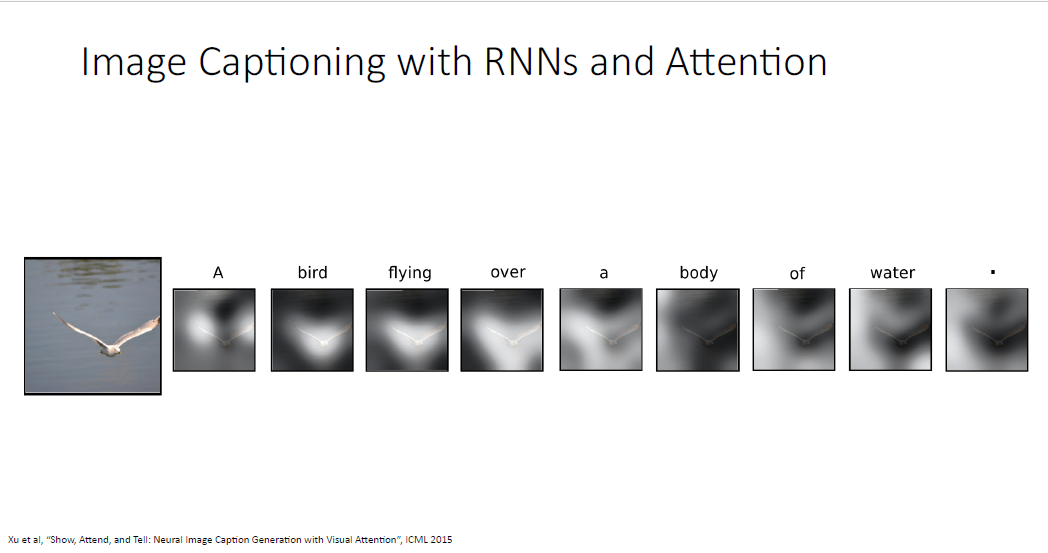
Image Captioning 논문의 예시이다.

어텐션 메커니즘을 이용한 image captioning 예시2
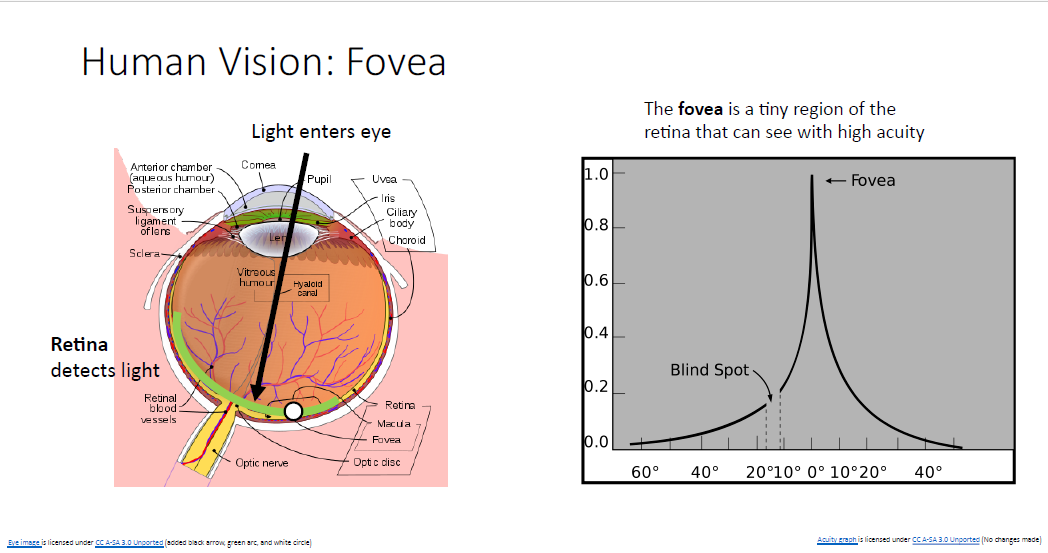
image captioning의 방법은 생물학적인 motivation에서 비롯된 것인데, 왼쪽의 눈 사진을 보면 retina(망막)이 있다.
망막은 광학적 자극을 받아서 우리가 볼 수 있는 형태로 해석해준다. 그런데 망막의 부분들은 모두 동일하게 작동하는게 아니다. 망막의 중앙부에는 중심와(Fovea)라고 불리는 영역이 있는데 이부분이 대부분의 자극에 반응하게 된다.
다시 말해, 망막의 영역들은 서로 다른 민감도를 가진 다는 것이다.
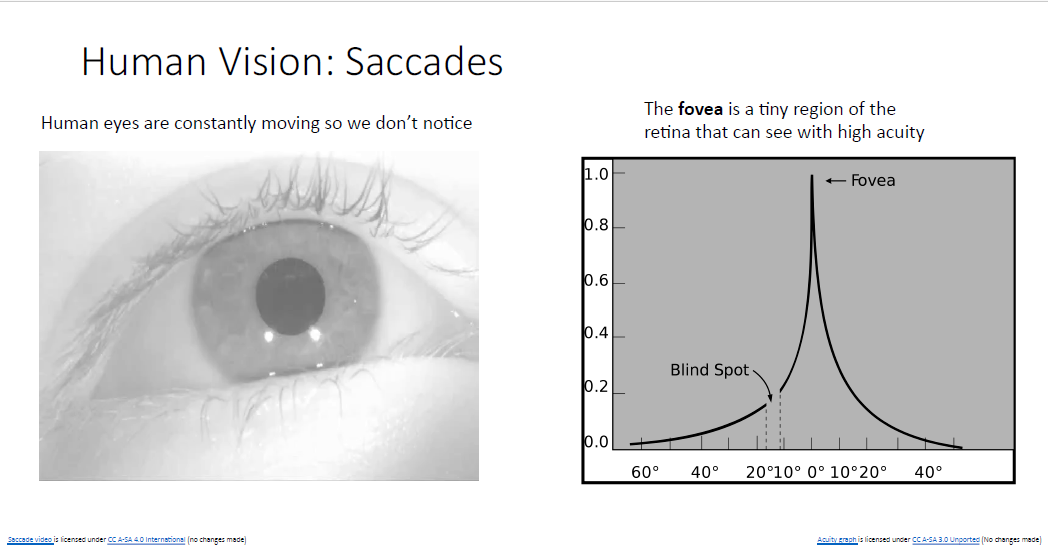
이러한 망막의 특징 때문에 사람은 어떠한 물체를 볼때 잘보기 위해서 눈을 무의식적으로 눈을 이리 저리 굴려 보게 된다.
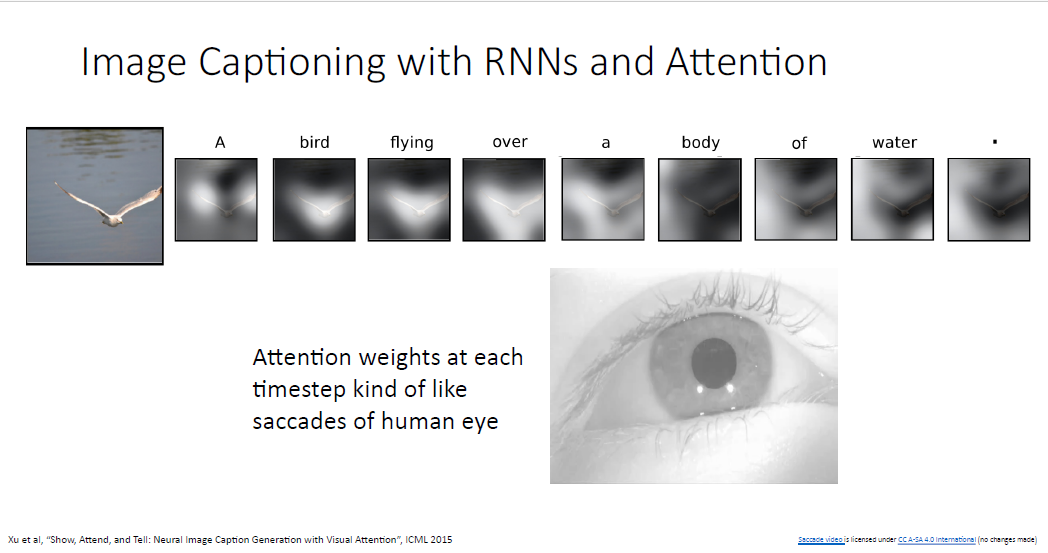
물론 이러한 인간의 눈의 메커니즘에 많은 영감을 받은 것은 아니지만, 어텐션 메커니즘은 이러한 인간의 눈과 비슷하게 작동하는 셈이다.

몇가지 논문을 소개하고자 한다. 이러한 어텐션 메커니즘을 활용한 논문들인데,
논문 타이틀의 형식을 보면 X, Attend and Y의 형식인데 어떠한 내용을 의미하는지 눈치챌 수 있을 것이다.
아무튼 어텐션 메커니즘은 machine translation뿐만 아니라 다양한 task에 일반화되어 광범위하게 사용되고 있다.
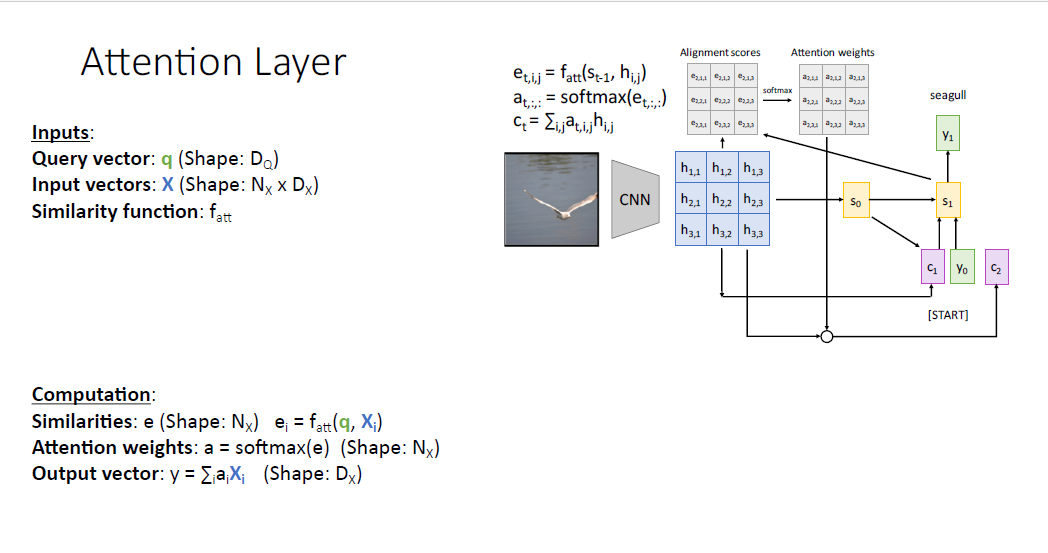
지난 몇년간 컴퓨터 과학은 이러한 어텐션 메커니즘을 더 많은 task에 대해서 일반화 하기 위해서 고안해 낸 것이, 바로 Attention layer이다. Attention layer는 곧바로 우리의 NeuralNetwork에 포함시킬 수 있다.
우선, 어텐션 메커니즘을 우선 아래와 같이 재구조화 해보자.
디코더의 hidden state에 대응되는 것을 query vector $q$라고 하자.
인코더의 hidden state에 대응되는, attend하는 대상을 input vector $X$라고 하자.
Similariy function으로는 여전히 $f_{att}$이다.
이렇게 하면 계산은 동일하게 query vector로부터 각각의 input vector $X$와의 유사도를 계산하고, 소프트맥스를 통과시켜 Attention weights를 얻고, 가중합을 통해 scalar를 얻는다. 모두 순회하면 output vector가 된다.
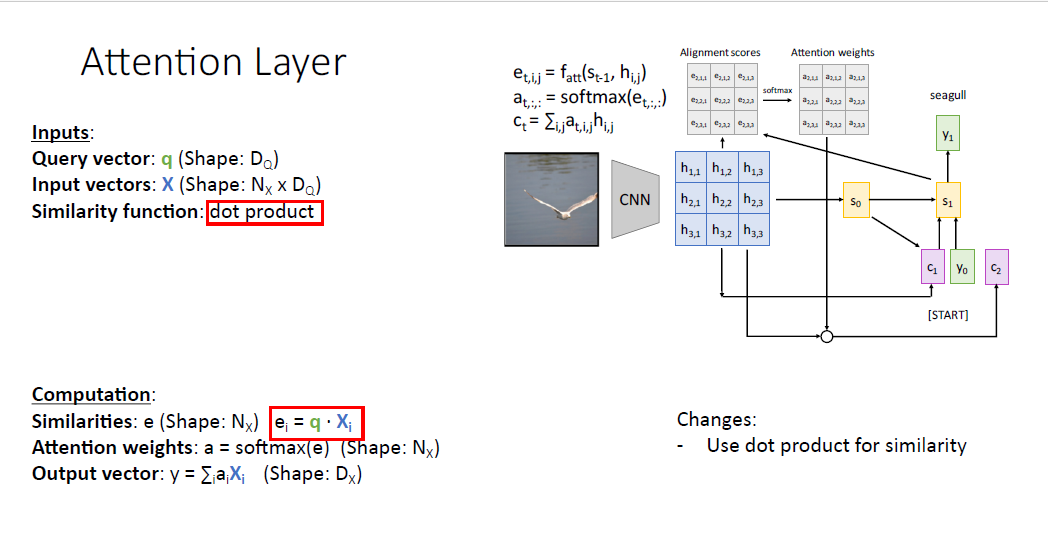
일반화를 위해 처음을 바꾼 것은 Similarity function을 $f_{att}$를 사용하는게 아니라 연산을 간단히 하기 위해 dot product를 사용한다.
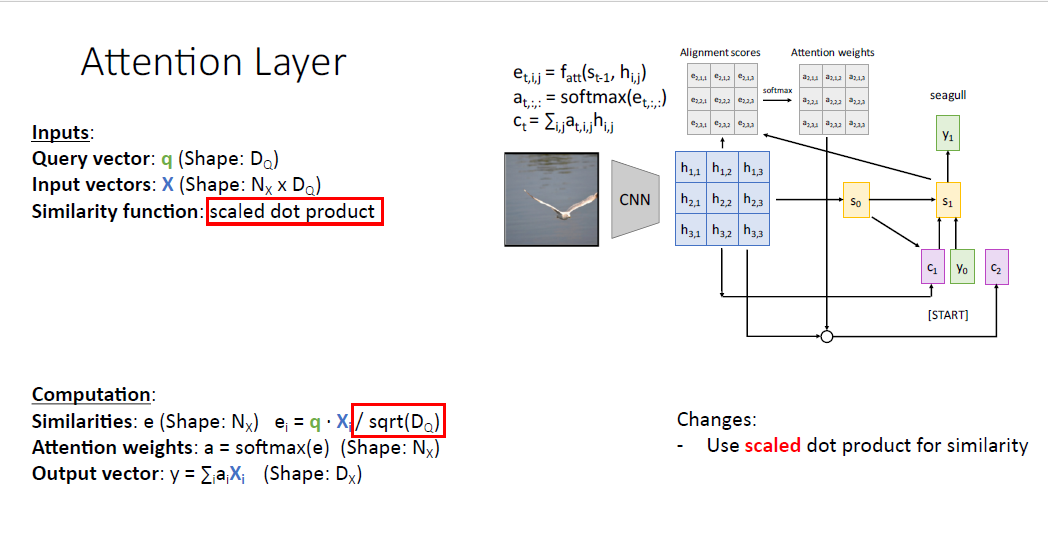
사람들은 종종 dot product가 아닌 두 벡터의 차원으로 나눈 값인 scaled dot product라고 불리는 연산을 사용한다.
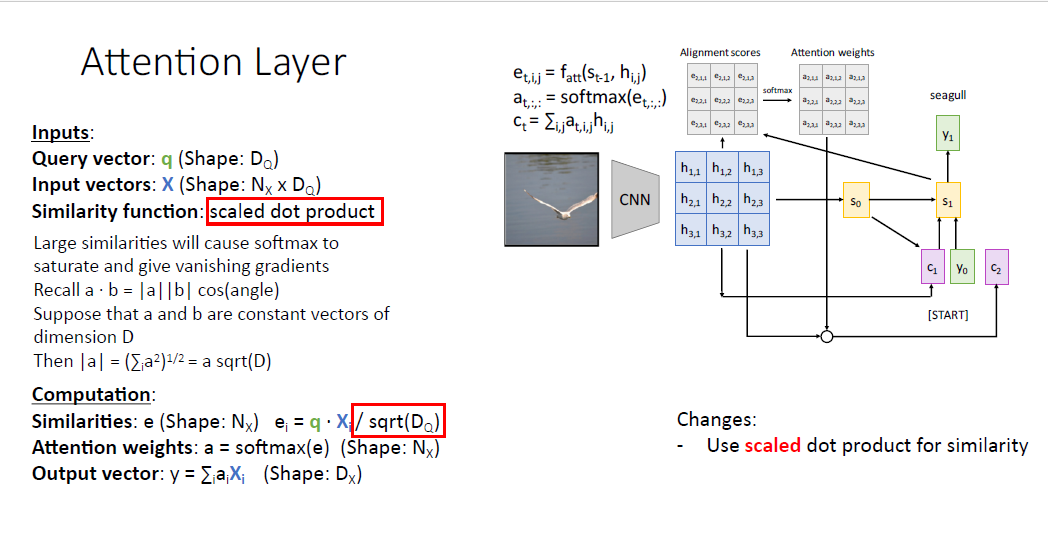
유사도를 계산할때 scaled dot product를 사용하지 않으면 , 다음 단계인 softmax를 통과할때 score가 높은 값은 뾰족하고, 낮은 값은 완만한 형태를 보일텐데, 낮은 score 값은 gradient vanishing을 발생시킨다.
또한 두 벡터가 너무 큰 차원을 갖는 상태에서 dot product를 하면 그 벡터의 크기는 너무나 커지기 때문에 스케일링을 위해 나눠주는 연산을 수행한다.
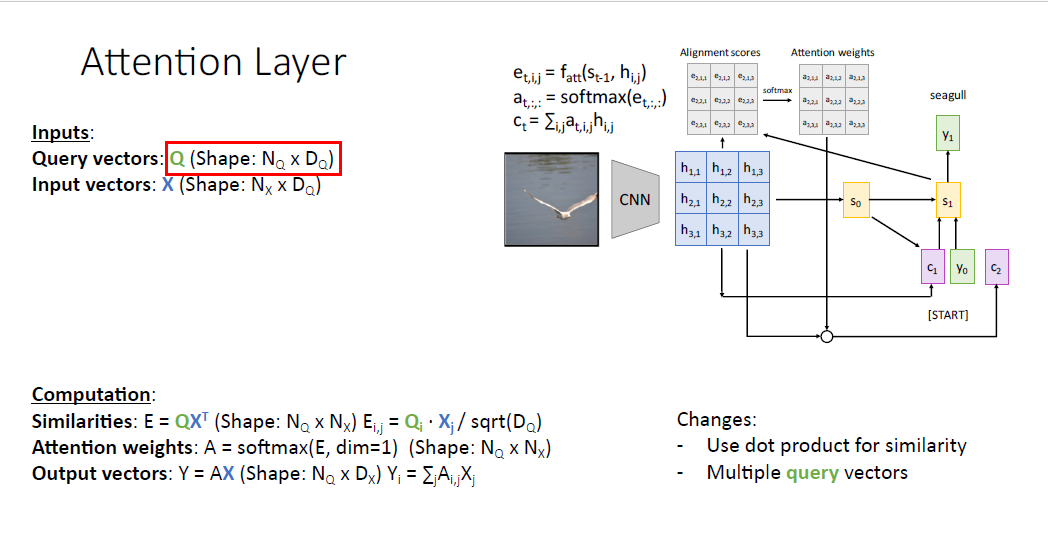
다음 일반화 방법은 여러개의 쿼리 벡터를 갖는 것이다. 이제는 하나의 단일 쿼리 벡터가 아니라 쿼리 벡터의 집합인 &Q&를 사용하게 된다. Ouput vector는 한개가 아니라 각각의 쿼리 벡터에 대응하는 output vector를 갖게 된다.
그리고 나서 input vector에 관해서 살펴보자. input vector는 첫번째로 attention weights를 계산하기 위해 각각의 query vector와의 계산이 한번 이뤄지고, output vector를 뽑아내기 위해 attention weights와 다시 한번 더 연산한다.
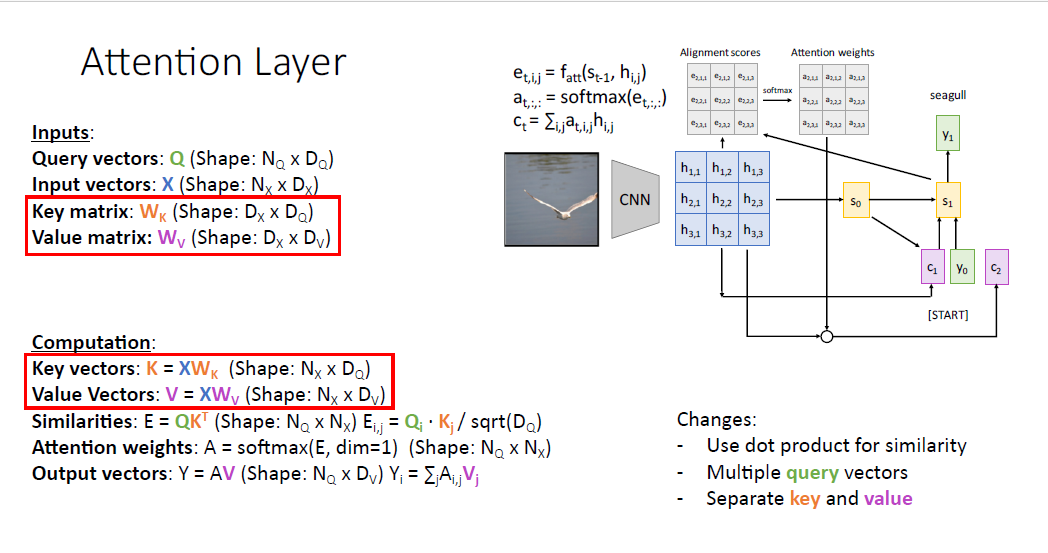
다음 일반화 방법은 input vector의 두가지 역할에 관해서 key vector와 value vector로 나누는 것이다. learnable matrix인
$W_k$와 $W_v$로 나눔으로써 각 Matrix는 서로 다른 역할을 갖게 된다.
이러한 방법을 통해서 모델은 유연성을 더욱 갖게 된다.
query, key ,value vector에 관한 직관을 돕기 위해 예를 들어보자.
만약 구글에 "엠파이어 스테이트 빌딩이 높이가 얼마나되지?" 라고 검색을 한다고 생각해보자. 이러한 문장이 query가 된다. 그럼 구글의 서치 엔진은 데이터 베이스를 샅샅히 뒤질것이다. 그런 뒤 해당하는 결과를 내놓을 것이다.
이 과정에서 결과가 쿼리와 같은지 살필 필요는 없다. 아마도 검색 결과가 쿼리와 얼마나 상관이 있는지만을 살필 것이다.
여기서 데이터 베이스가 바로 key와 같은 역할이 되며 데이터 베이스 내에서 원하는 결과만 모은 것이 value가 된다.
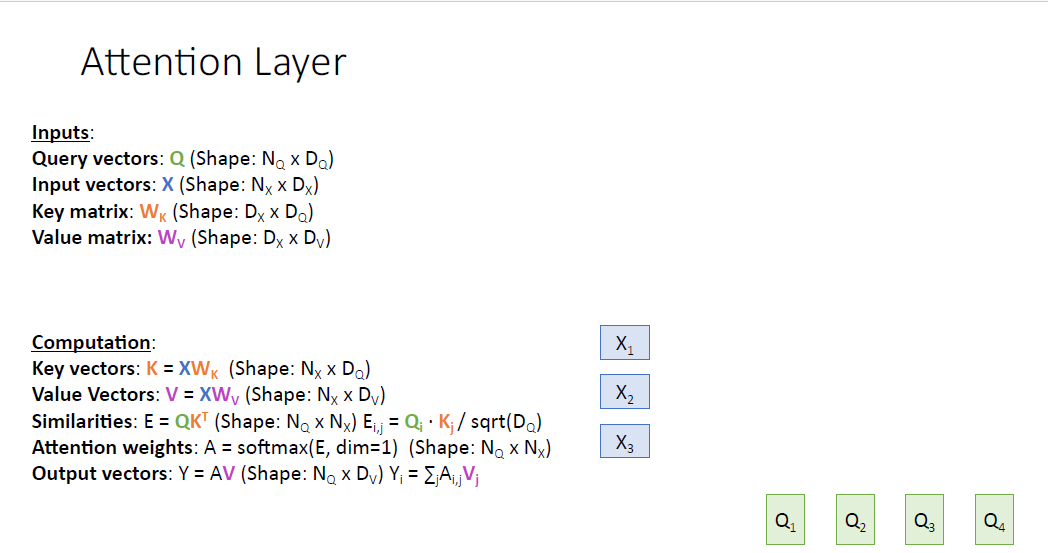
지금 까지의 일반화 과정을 시각화를 통해 나타내 본다.
4개의 쿼리 벡터가 있고 3개의 인풋 벡터가 있다.

각 input vector와 $W_k$ 매트릭스를 통해 Key vector를 얻는다.
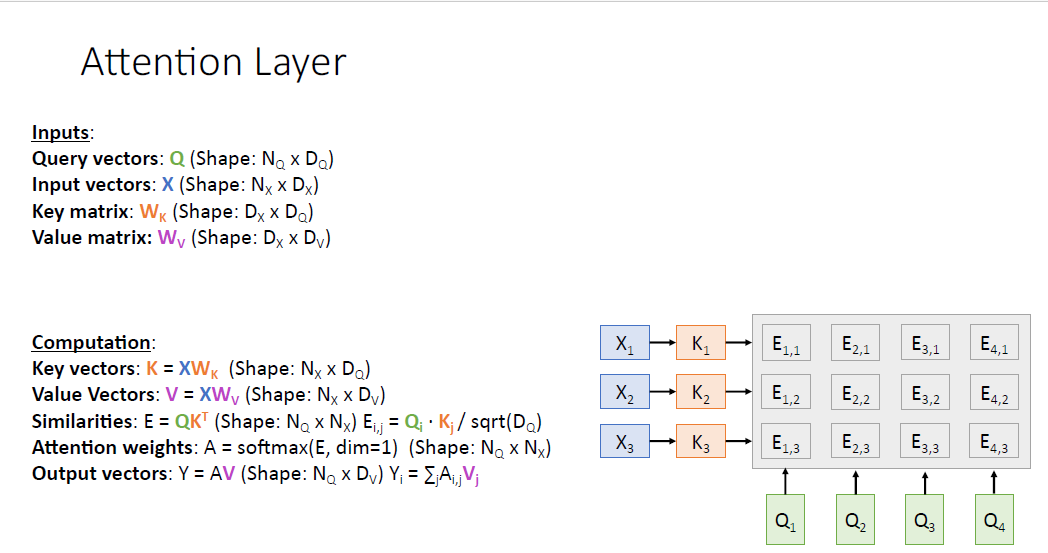
그리고 Query vector와 Key vector를 비교하여 Similarity score를 얻게 된다. (scaled -dot product)
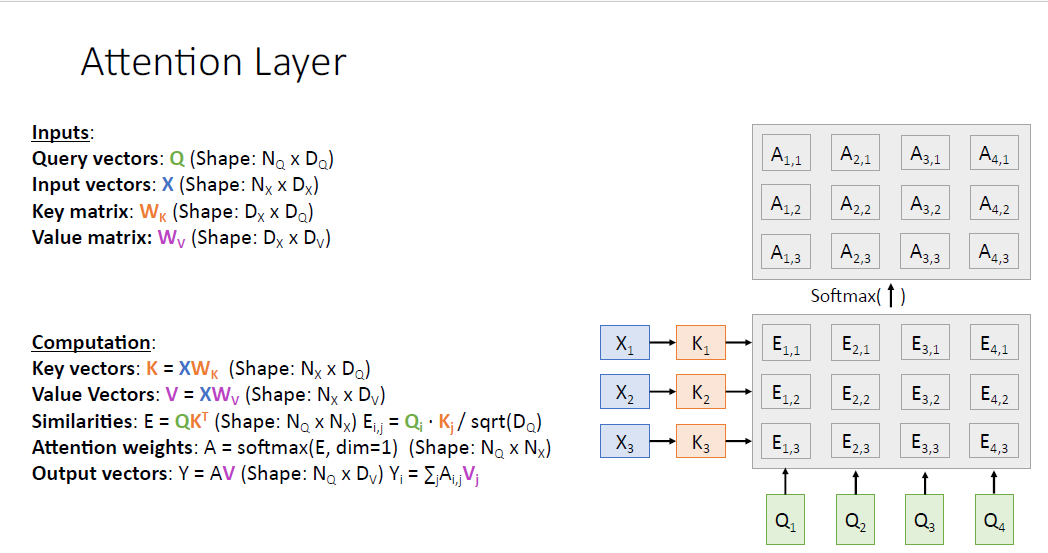
Similarity score는 nomarlized 되지 않았기 때문에 softmax를 통과시켜서 Attention weight를 얻고 (수직의 방향으로 적용한다, 쿼리별로 sum to one) 각각의 쿼리가 어느 인풋에 집중해야하는지를 알게 된다.
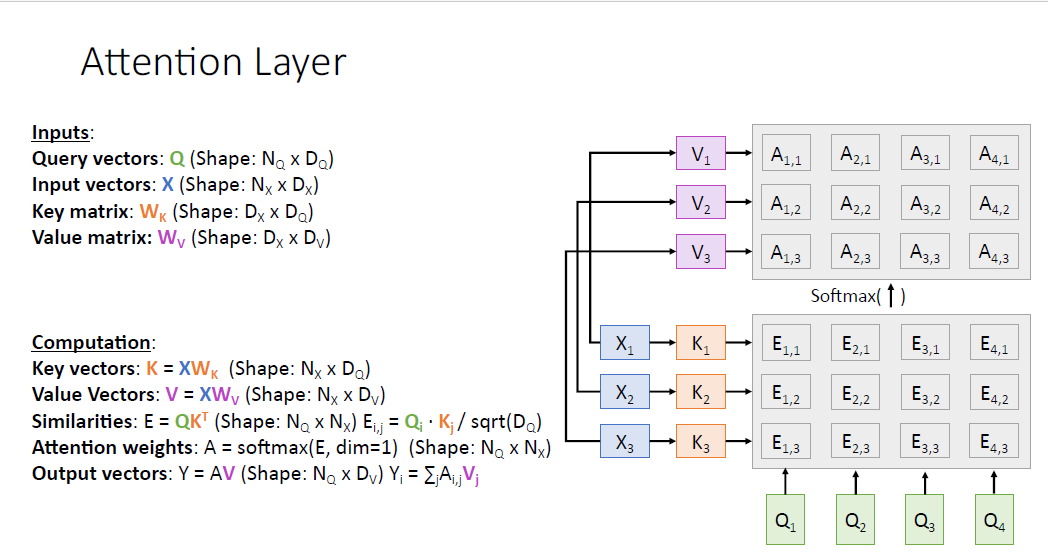
이제 output vector를 얻기 위해 input vector를 다시 한번 value vector로 변환시키고
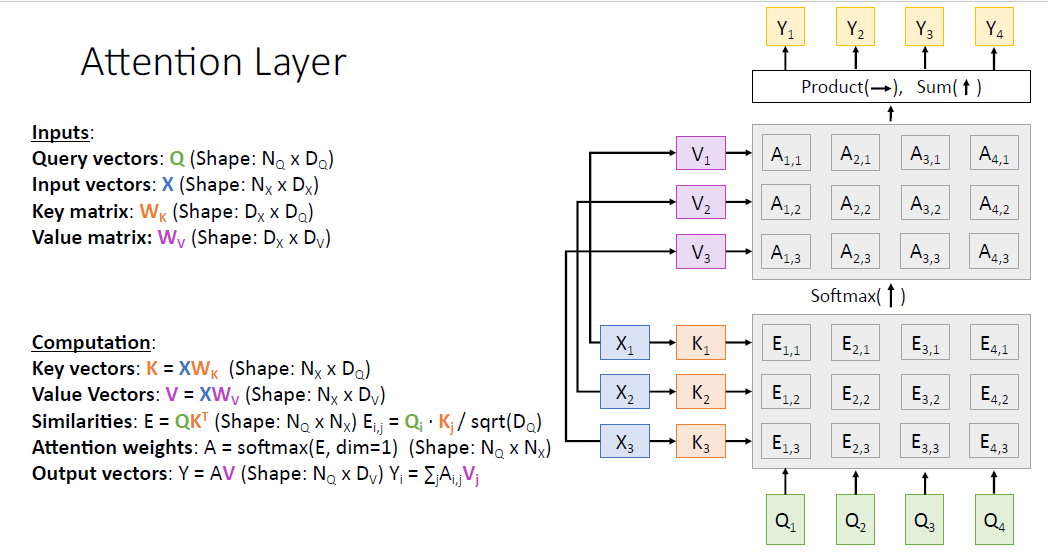
value vector $V_1, V_2, V_3$는 Attention weights와 가중합을 통해 Ouput vector $Y_1, Y_2, Y_3, Y_4$를 얻게 된다.
즉 우리는 input vector $X$와 query vector $Q$를 통해 매우 일반화된 형태의 NeuralNet의 하나의 layer 구조를 만들게 되었다. 여기서 query vector는 input vector의 재조합된 key,value vector가 필요하였다.

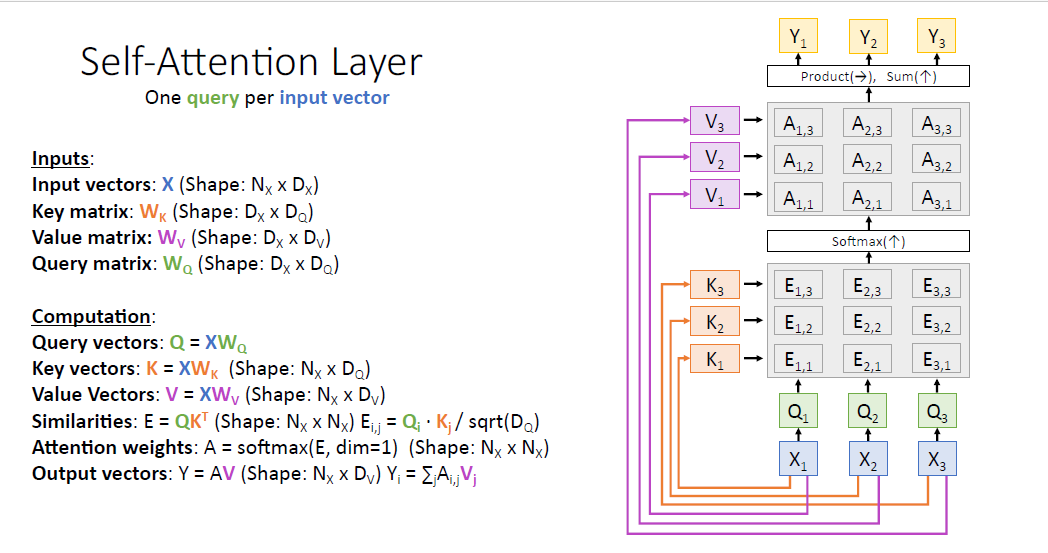
Attention layer의 특별한 케이스인 Self-Attention layer에 대해서 소개한다.
여기서 input은 오직 input vector $X$이다. self-attention은 input vector X의 요소들끼리 비교한다.
self attention에서는 input vector를 query vector로 변환시키기 위해 $W_Q$ matrix가 추가된다.
나머지 요소는 이전 attention layer와 모두 같다.

input vector로 부터 $W_Q$를 통해 query vector를 만들고
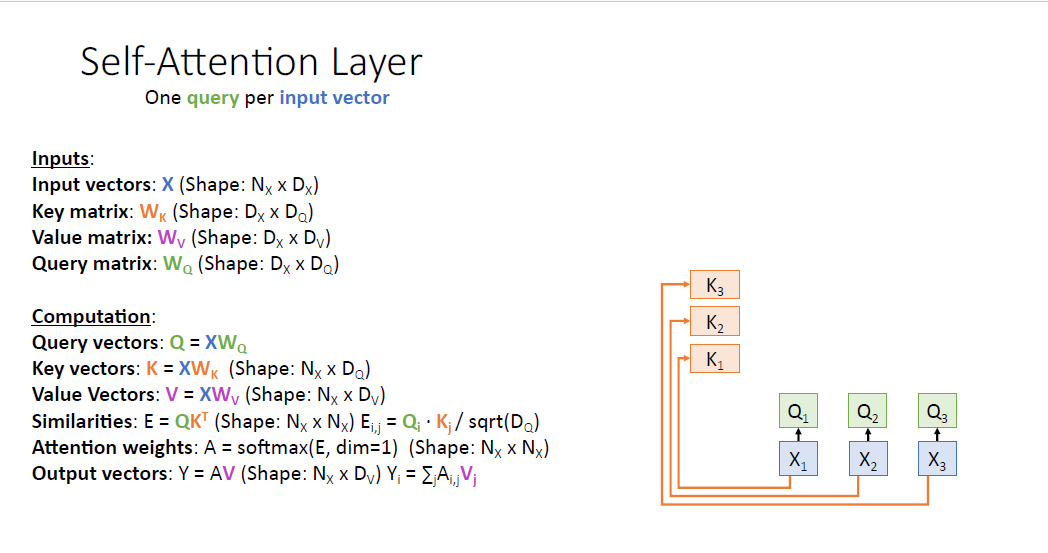
동일하게 input vector로부터 $W_K$로 부터 key vector를 만든다.
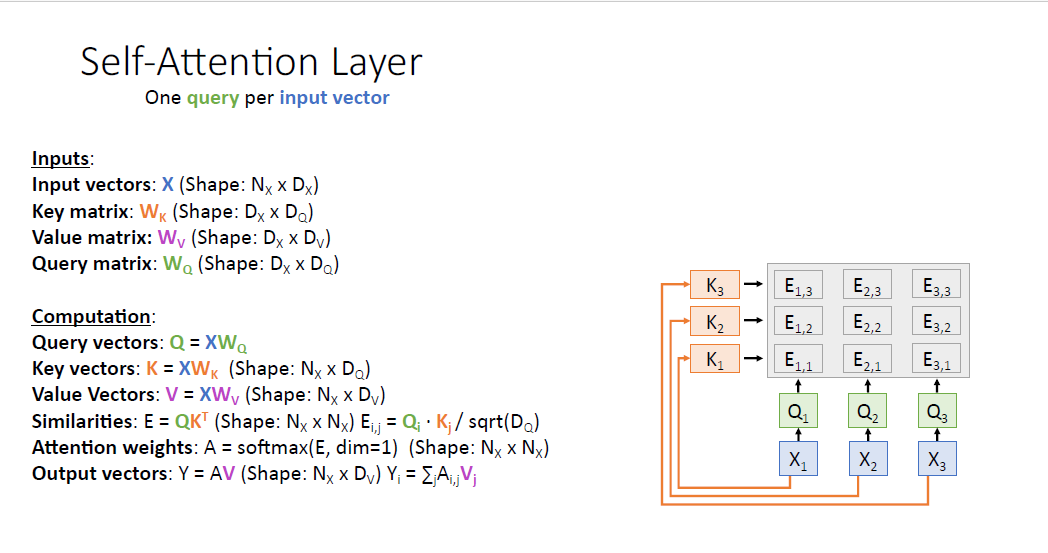
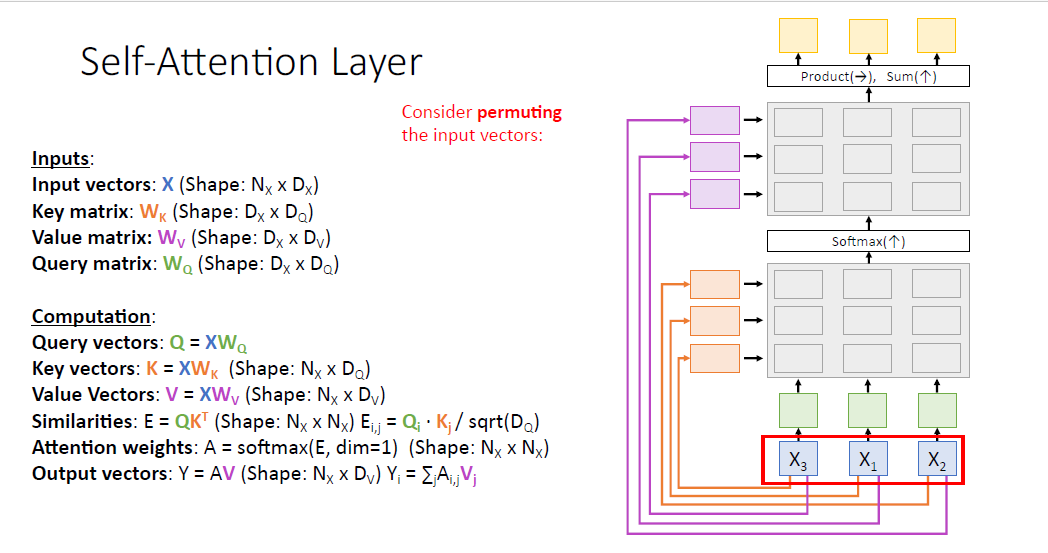
여기서 input vector $X$의 요소들의 순서가 바뀐다고 생각해보자. 예를들어 $X_3, X_1, X_2$ 같은 식이다.
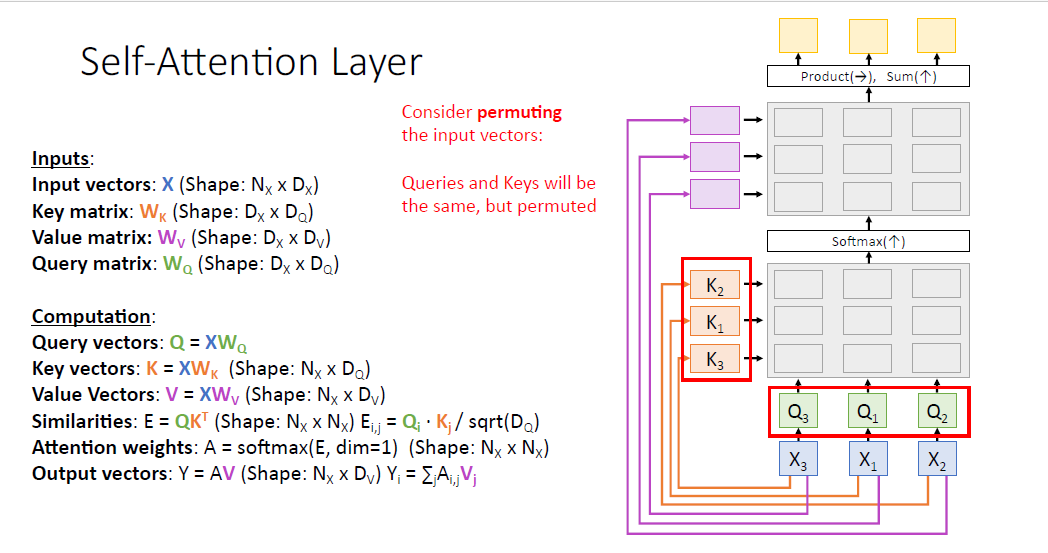
대응되는 key vector와 query vector도 동일하게 바뀐 순서로 구성될 것이고. (값은 같지만 순서만 바뀐다.)
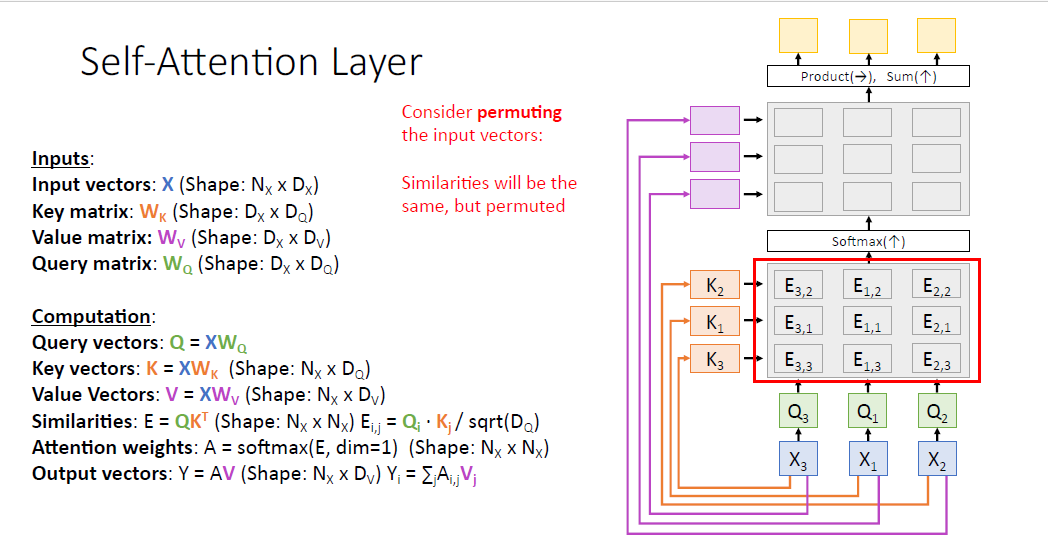
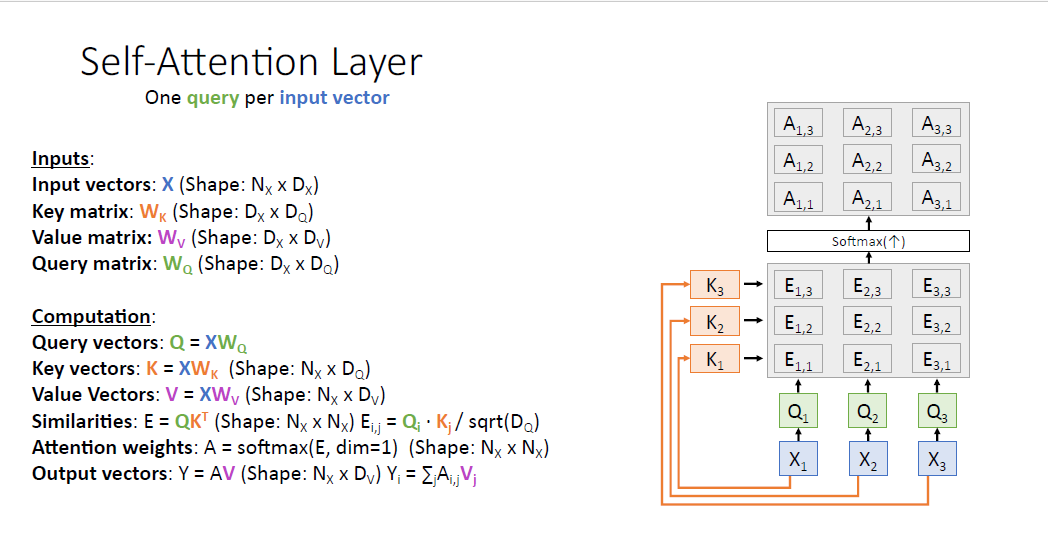
게산되는 Attention score matrix도 그에 맞춰 바뀌게 된다. 물론 값은 같다.
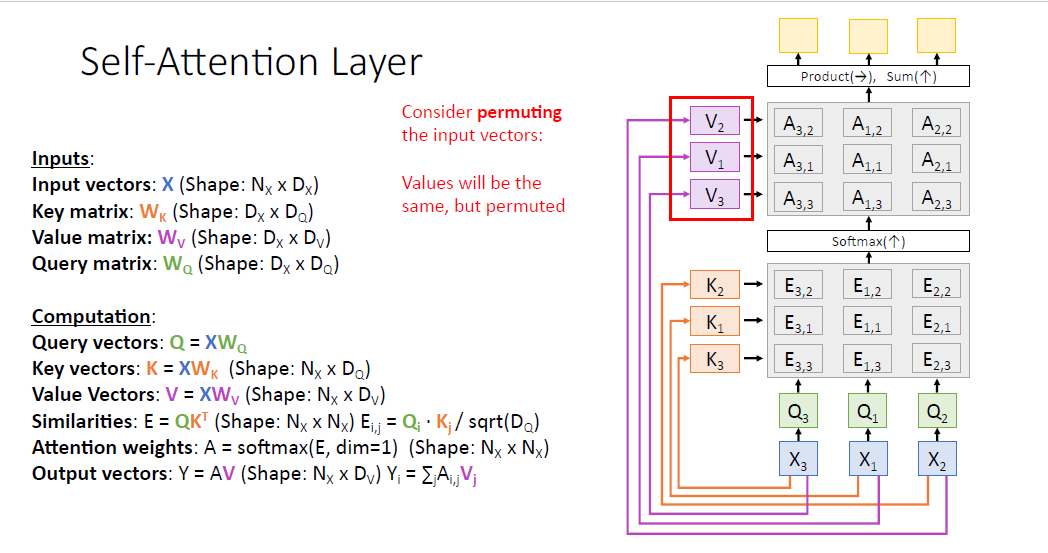
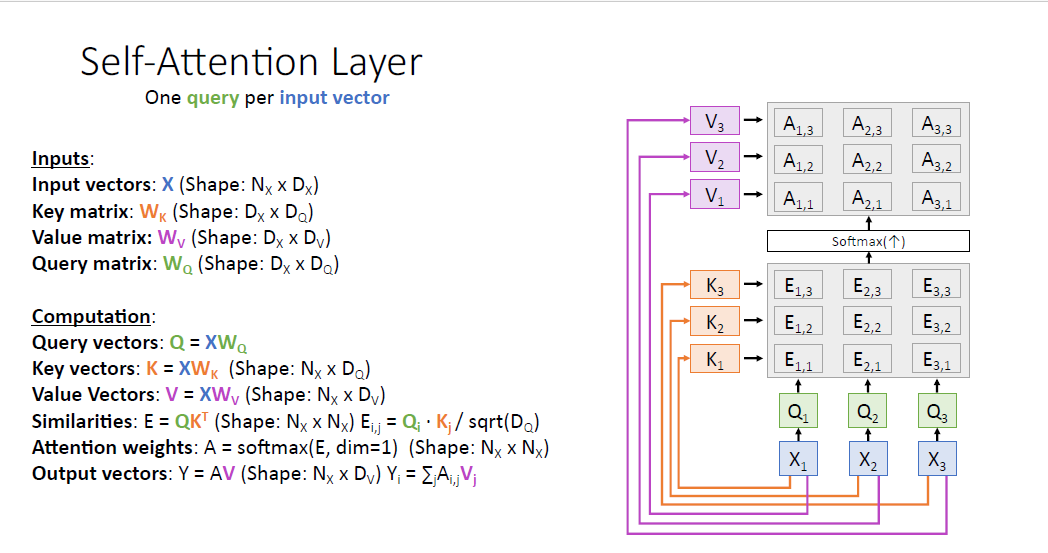
value vector도 마찬가지로 값은 같지만 순서가 바뀐 형태이다.
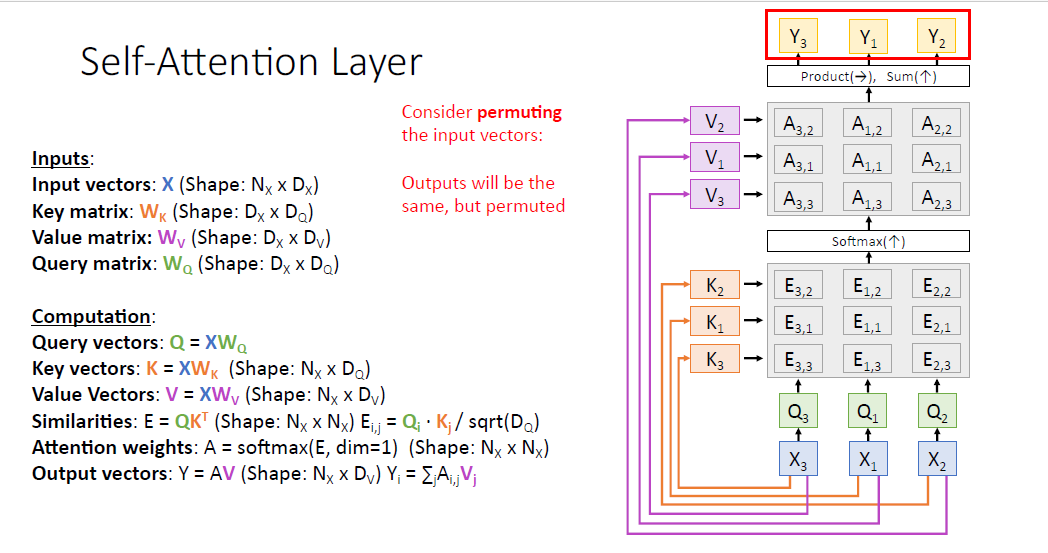
output vector $Y$도 동일하게 순서가 바뀐 것을 알 수 있다.
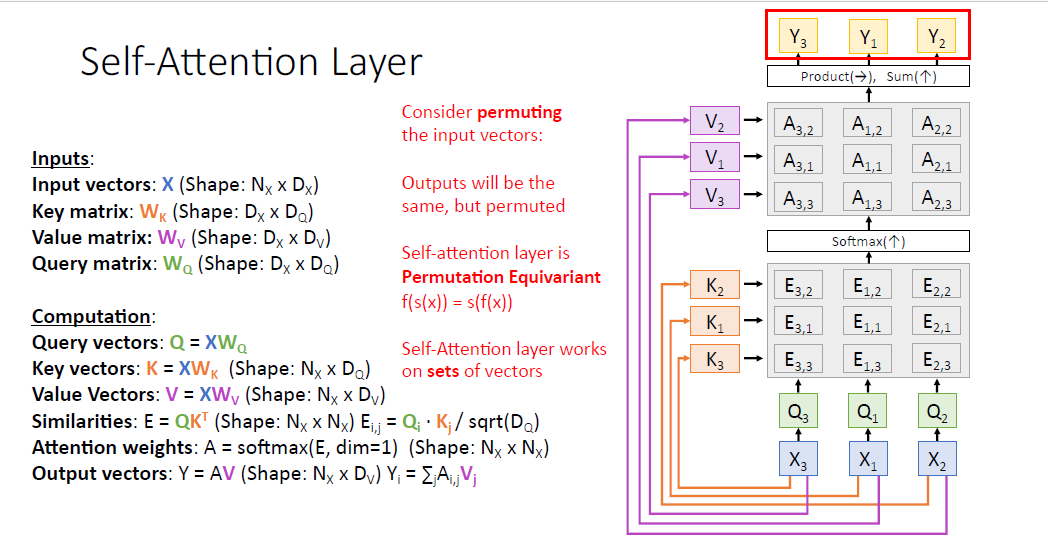
self attention layer는 즉 Permutation Equivariant 성질을 갖고 있다.
우리가 $X$의 순서를 바꾸면 $Y$의 순서도 동일하게 바뀌게 된다.
즉 여기서 알 수 있는 것은 attention layer는 단순히 연산하는 과정에서 $X$의 순서를 고려하지 않는다는 것이다.

다시 말해, self attention layer는 $X$의 순서를 알지 못한다.
그러나 어떤 task에서는 vector의 위치가 중요할 수 있다. 예를들어 machine translation에서는 종료 지점이 어디인지 알아야 한다. 하지만 default self attention 세팅은 이러한 위치 정보를 고려하지 못한다.

그래서 이러한 순서의 변화를 고려하기 위해서 'poistional encoding'이라는 위치 정보를 추가하게 된다.
postional encoding을 하는 함수는 학습가능한 버전도 있고 고정적인 버전도 있다.
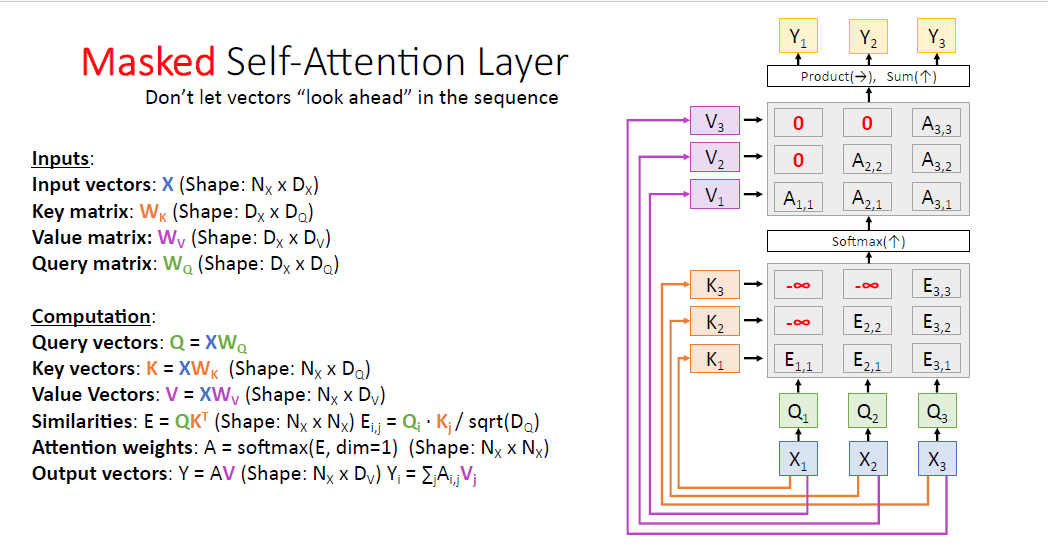
어텐션 레이어의 또 다른 버전은 Masked Self attention layer라고 불리는 것이 있다.
어떤 task에서는 모델에게 오직 과거의 정보만을 이용하도록 해야할 수 있다.
예를들어 language 모델링에서 , 모델은 이전 과거의 토큰 정보만으로 다음 토큰을 예측해야 한다.
default 세팅에서는 모든 정보를 이용하기 때문에 language 모델링 task에 적절하지 않다.
따라서 attention matrix의 구조에서 조금 변형하여 이를 해결하는데,
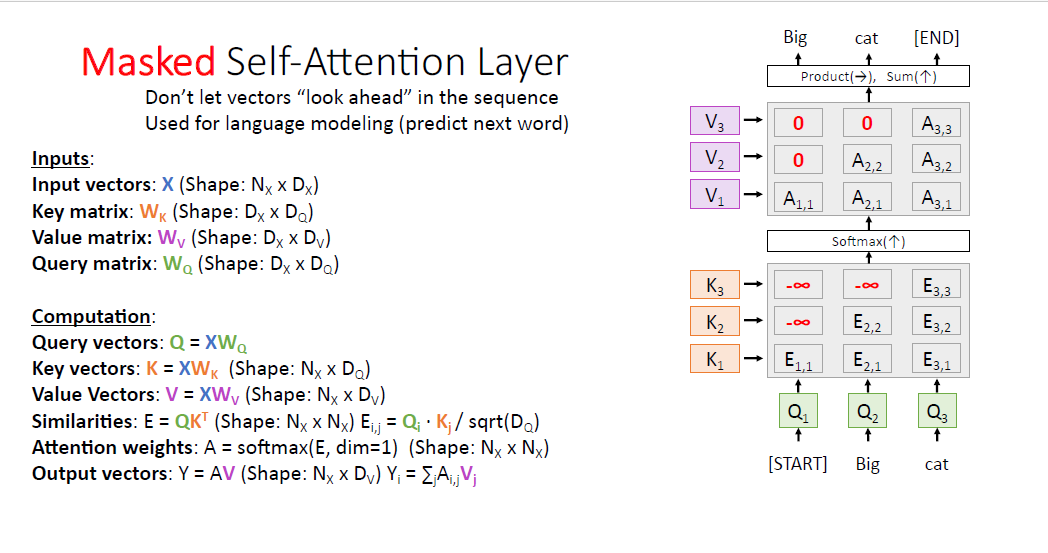
모델에게 보지 못하도록 하는 부분에 -infinty를 부여하여 이러한 문제를 해결한다, $Q_1$ 같은 경우에는 오직 첫번째 input vector인 $K_1$의 정보만을 보도록 하는 것인데, 나머지 -infity가 부여된 값은 소프트 맥스를 통과하면 0값을 갖기 때문에 이를 attend하지 못하게 된다.
이 방법은 language 모델링에서 매우 보편적으로 사용된다.
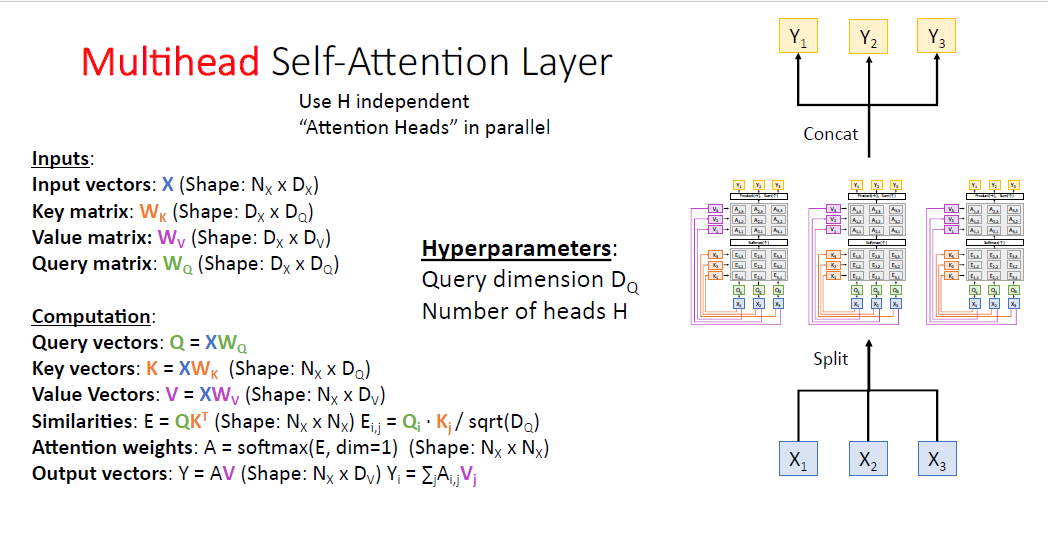
다음으로 봐야할 것은 Multihead Sealf-Attention layer이다.
각각 개별적이고 병렬적인 Self attention layer이다.
여기서 $H$라는 몇개의 멀티 헤드를 쓸것인지에 관한 하이퍼 파라미터가 새롭게 추가 된다.
output은 멀티 헤드 어텐션의 결과를 concat하여 도출한다.
즉 두가지 하이퍼 파라미터 쿼리 벡터의 차원인$D_Q$ 와 $H$를 설정해야 한다.
이제 attention layer가 얼마나 우리의 network에 한 slot으로 잘 일반화되는지를 살펴보자.

CNN과 Self attention의 예시이다.
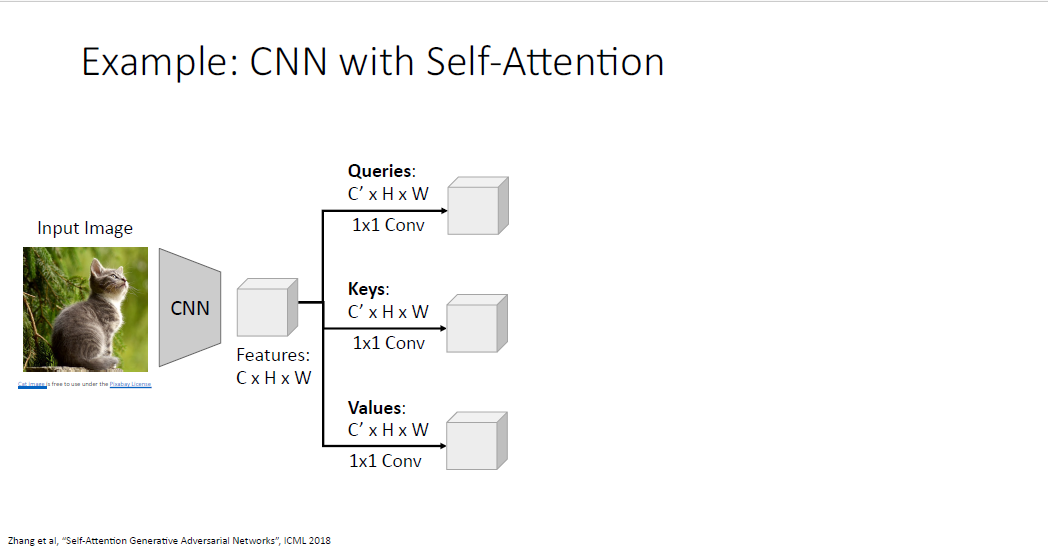
CNN을 통해 feature vector를 계산하고
각각의 개별 weight를 갖는 1x1 Convolution을 통해 Query, Key, Value vector를 각각 만든다.
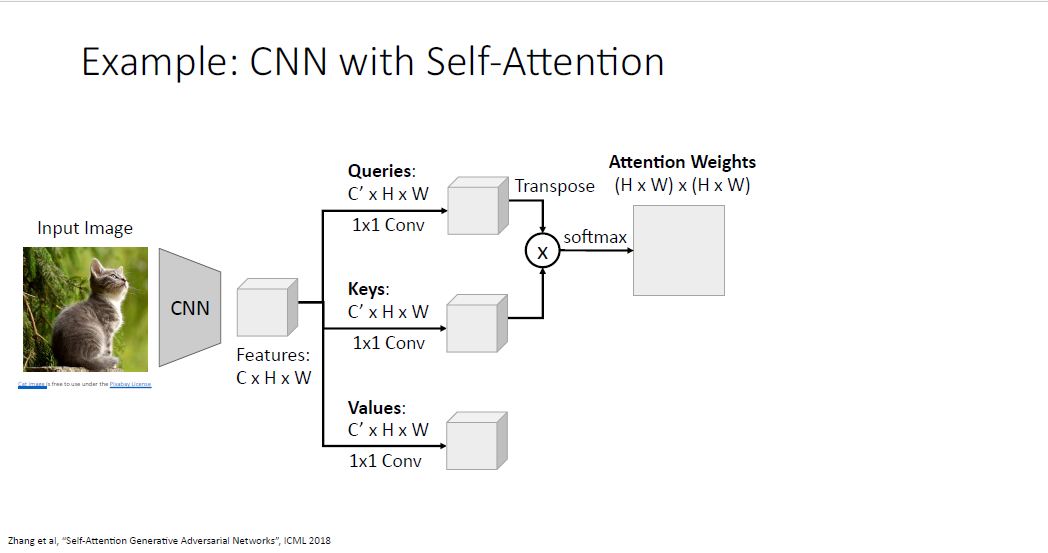
매우 큰 shape을 갖는 Attention weights를 갖게되고, 이는 각 이미지의 포지션이 다른 포지션을 얼마나 attend해야되는지를 알려준다.
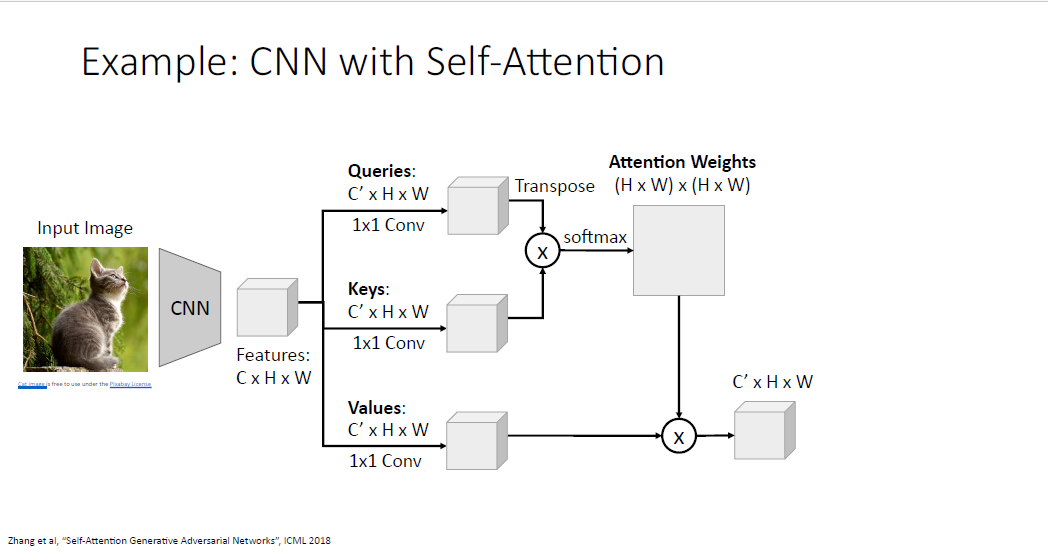
그리고 동일하게 value vector와 가중합(선형 변환)을 해준다.
이렇게 만들어지는 output grid는 input grid의 각 부분에 영향을 받아 생성되게 된다.
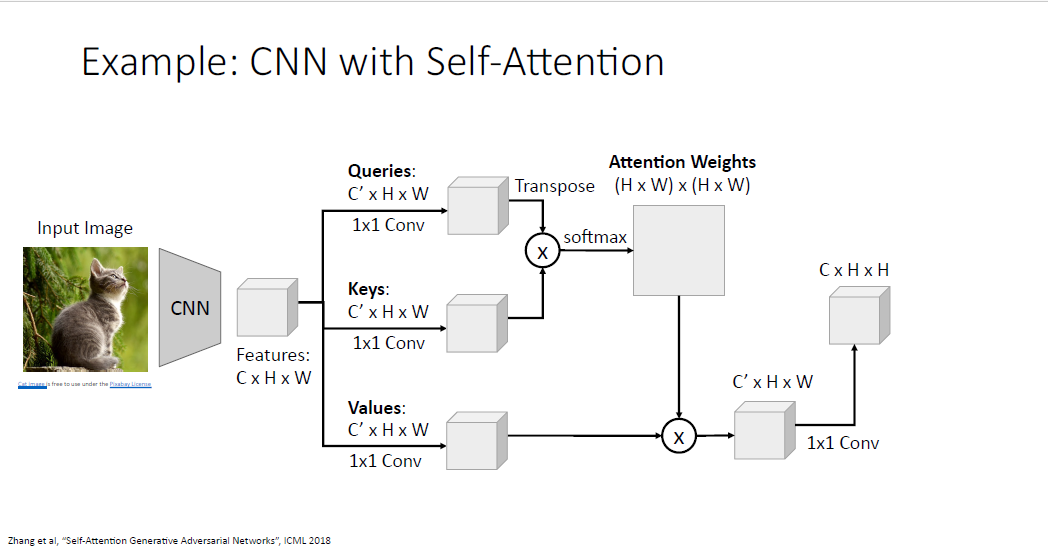
끝의 구조에 사람들은 종종 1x1 Convolution을 더 섞기도 한다.
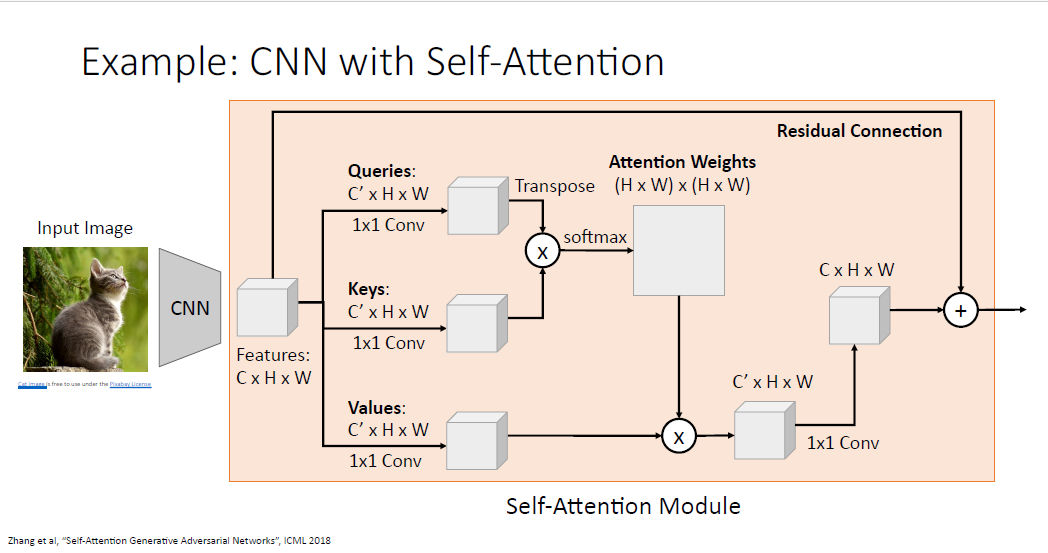
그리고 전체 구조에 Residual Connection을 연결하는 구조도 자주 사용한다.
이것은 어떤 새로운 모듈이 된다.
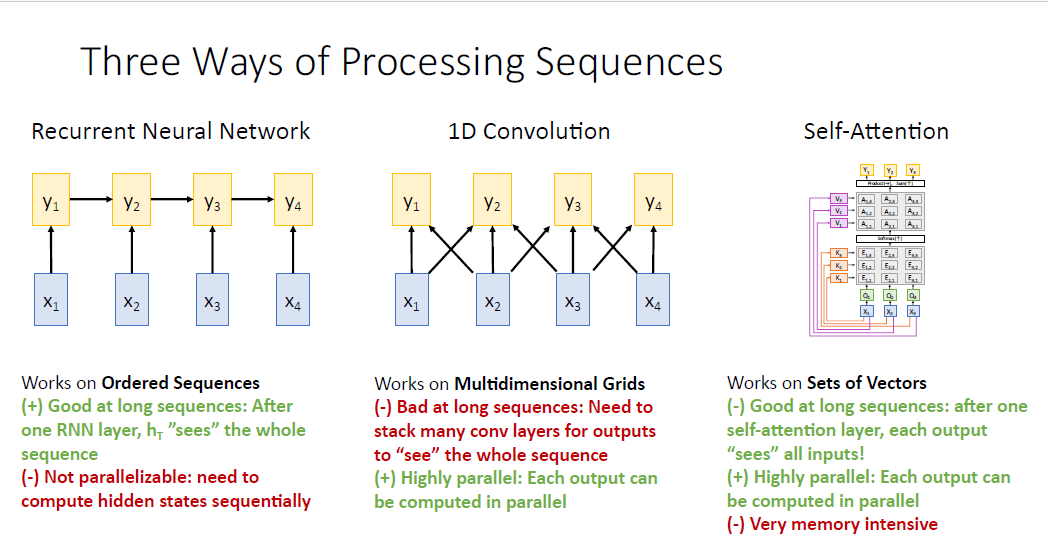
우리는 지금까지 seqeucne to sequence를 다루는 세가지 전형을 살펴 봤다.
하나가 RNN이었고, 두번째는 1D Convolution 그리고 세번째가 self attention인 것이다.
RNN은 히든 스테이트 $h_T$가 모든 시퀀스의 정보를 활용하고, 또한 lstm을 사용하면 긴 시퀀스도 잘 다룰수도 있는 장점이 있으나 병렬적으로 다룰 수 없다는 단점이 있다. 그래서 매우 큰 신경망 모델을 만들때 병렬처리 연산에 특화된 gpu나 tpu같은 하드웨어의 특장점을 활용하기가 어렵다.
1D Convolution은 RNN과 달리 병렬처리가 가능하지만 그림에서 보듯 주위 인접한 sequence만 볼 수 있다는 단점이 있다.
따라서 전체 sequence를 보기 위해서는 많은 1D Convolution을 Stack해야한다.
Self-Attention은? 병렬처리에도 유리하며, 긴 시퀀스의 모든 정보도 활용할 수 있다. 두 네트워크의 단점을 모두 해결했다.!
다만 메모리 리소스가 많이 든다는 것 뿐이지만 GPU 메모리가 늘어나서 이점은 무시할 수 있다.
그래서 어떤것을 써야할까?
RNN? 1D Conv? Self-attention? 그들의 조합?

답은 " Attention is all you need"
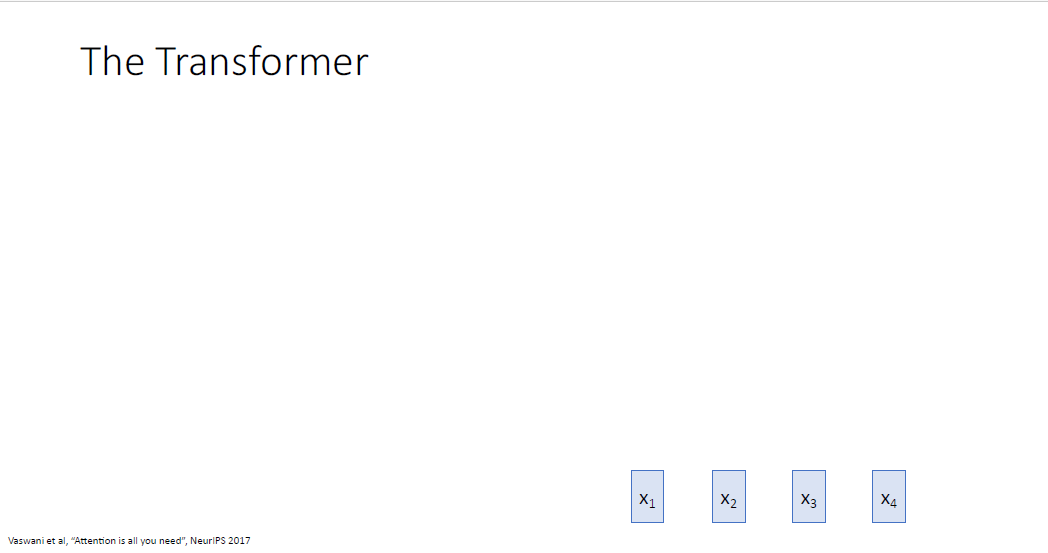
Attention is all you need 논문에서는 self attention만을 활용한 새로운 형태의 모듈 타입인 Transformer Block을 제안했다.
우선 트랜스포머는 input으로 input sequence만 받는다.
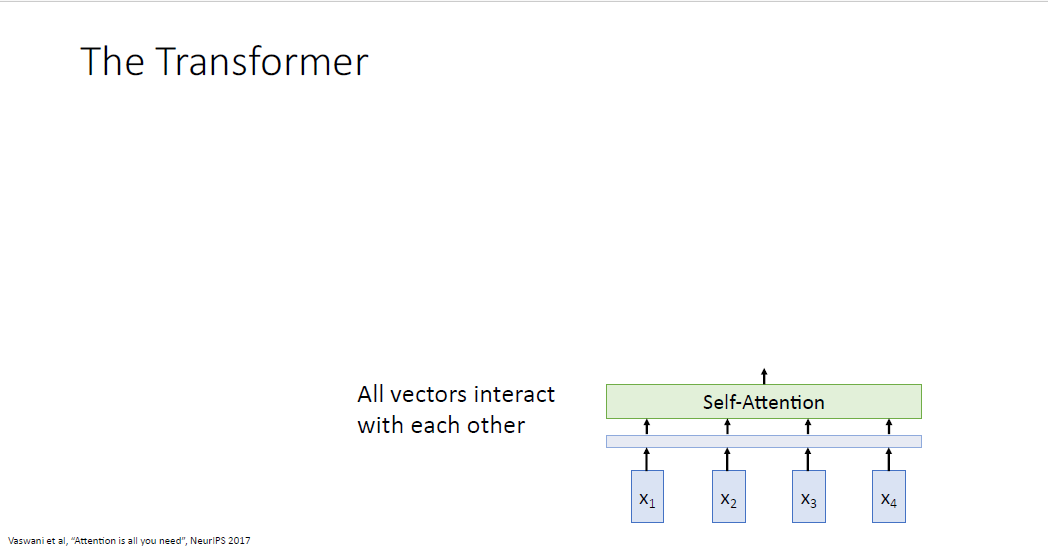
Transformer Block은 Multi head를 갖는 Self attention layer를 적용하고
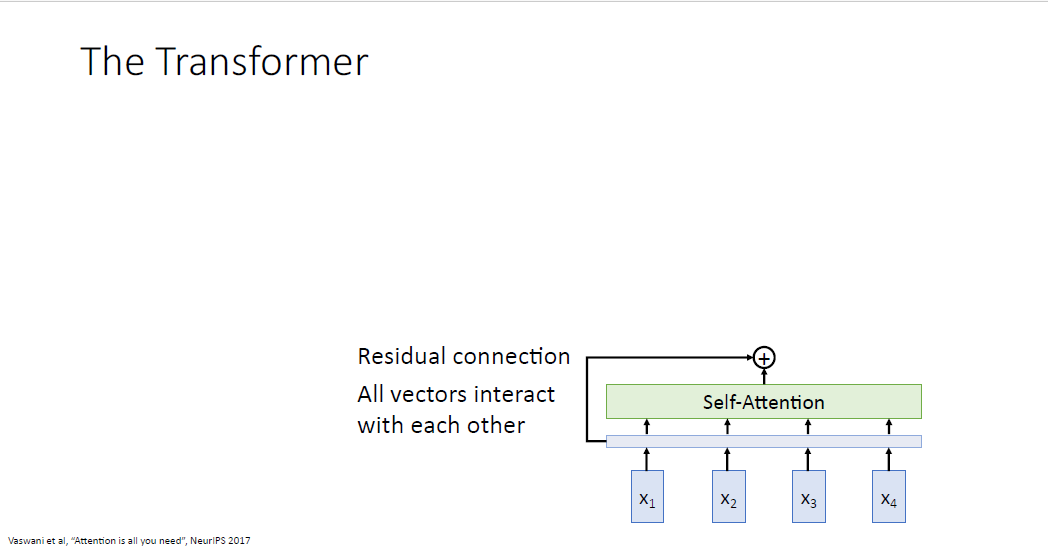
Self Attention결과와 Residual connection을 통해 모듈내 gradient flow를 개선한다.
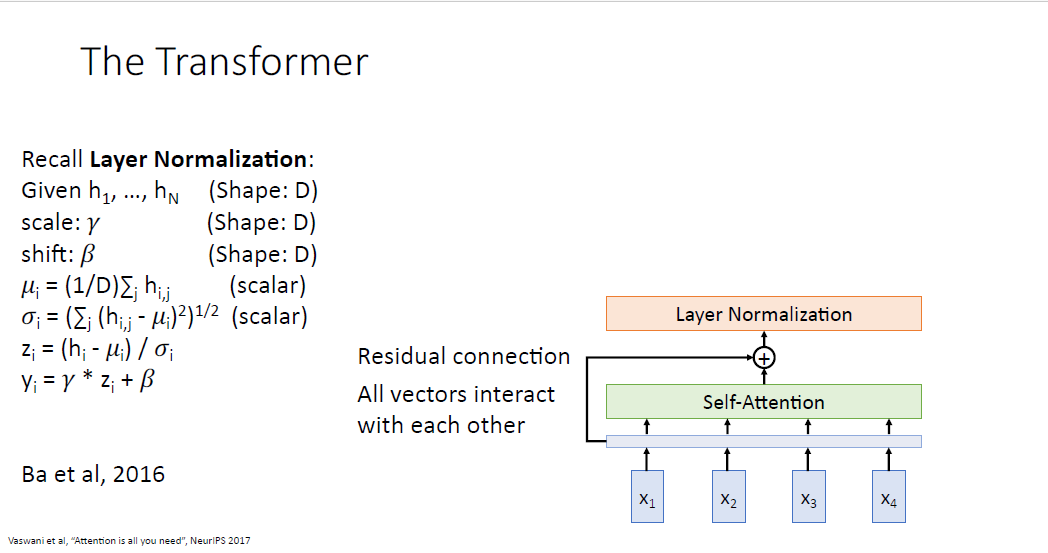
그리고 최적화를 돕는 layer nomalization을 추가한다. layer normalization은 시퀀스를 다룰때 아주 훌륭한 normalization 방법이다. layer normalization은 ouput sequence간에 어떠한 정보도 활용하지 않고 독립적으로 normalize를 수행한다.
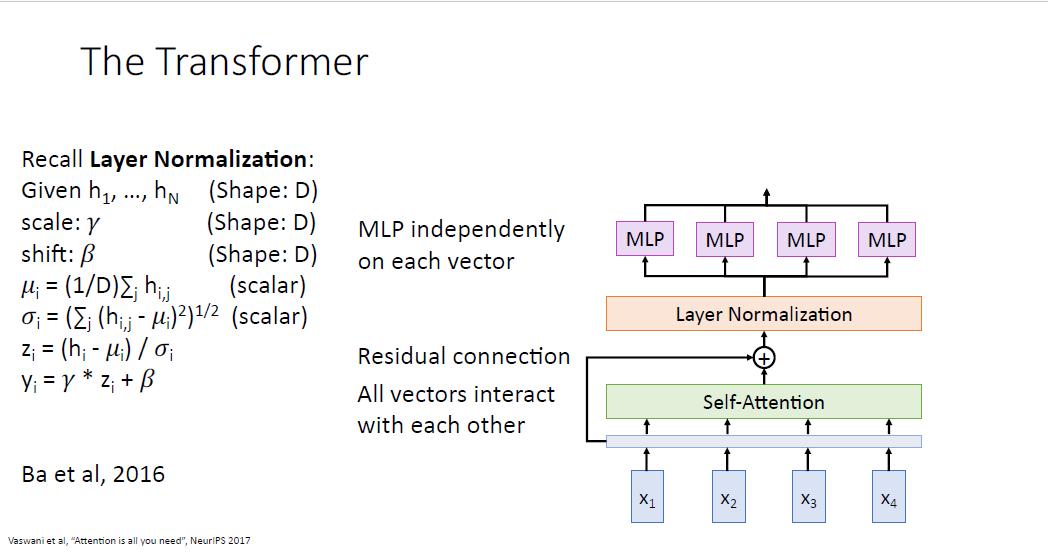
layer normalization이후엔 feed forward network(FFN) 혹은 Multi layer perceptron(MLP)라 불리는 layer를 각 output vector별로 통과하고
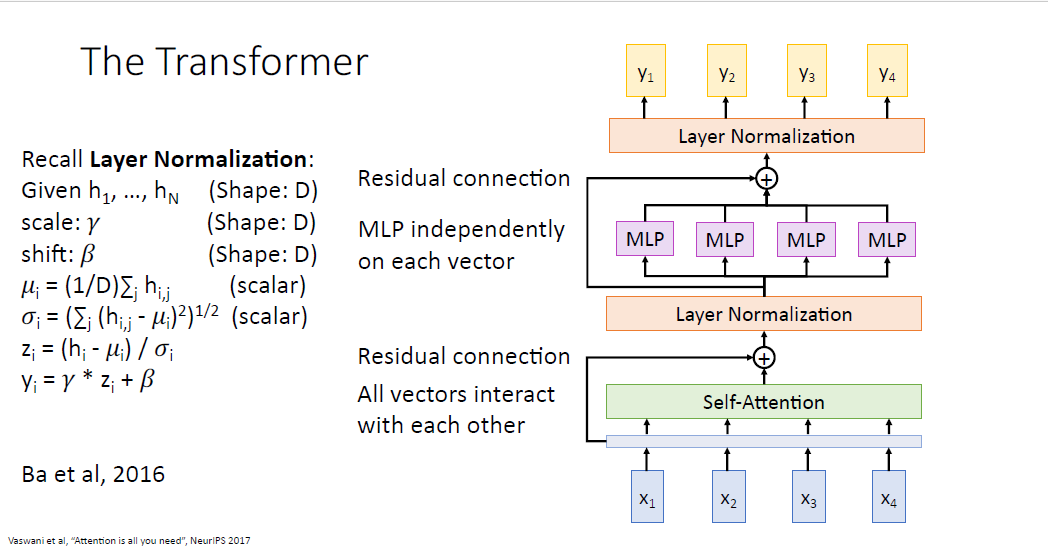
다시한번 Residual connection을 한뒤 layer normalization을 거쳐 output vector를 만들어 낸다.
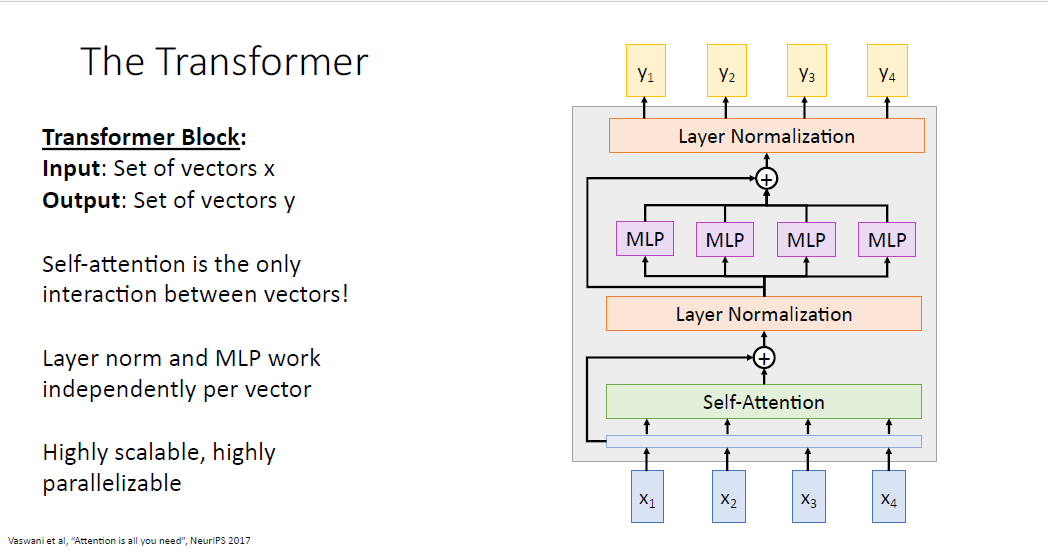
트랜스 포머는 LLM의 가장 기본적인 Building Block이다.
input vector와 output vector의 수는 갖지만, 모델 내부의 차원은 우리가 조정할 수 있다.
layer normalization과 MLP는 각각 개별적으로 작동하기 때문에, self attention에서만 communication이 일어난다.
또한 이 모든 구조는 병렬처리와 확장성에서 매우 우수하다.

Transformer Blcok에서는 정해야할 하이퍼 파라미터가 블럭의 갯수와 내부의 차원, 멀티헤드의 갯수인데
논문에서는 각 12개와 512차원, 6개의 헤드를 사용하였다.

Transformer는 NLP계의 ImageNet이라고 불리고 있다.
Transformer는 컴퓨터 비전처럼 NLP에서도 pre-train을 가능하게 했다.
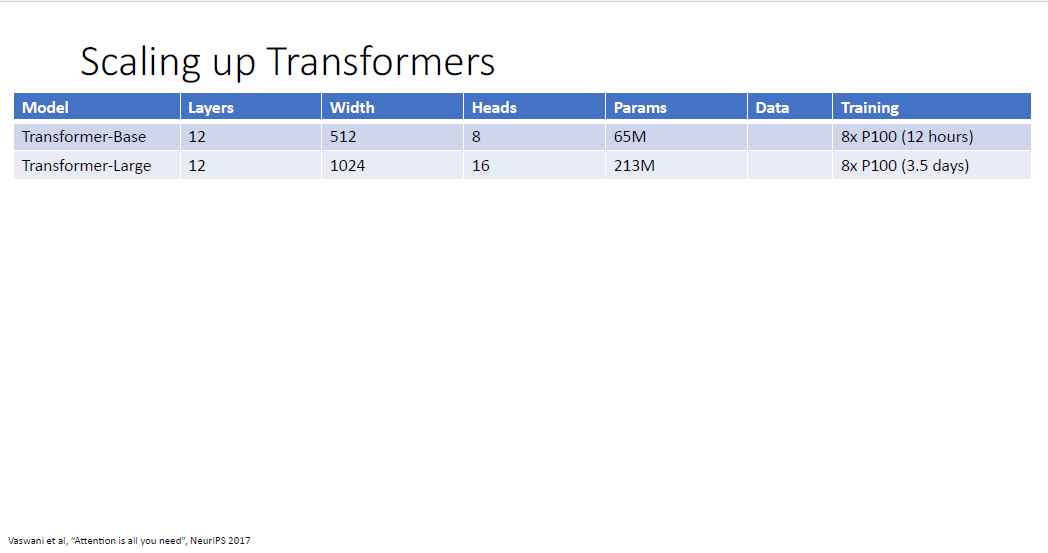
최근 몇년 AI 연구실에서는 이 Transformer의 구조를 어떻게 더 크게 만들까가 가장 큰 화두였고
처음 Attention is all you need 논문의 오리지널 버전은 65M과 213M의 파라미터 갯수를 가진 두가지 버전이었다.
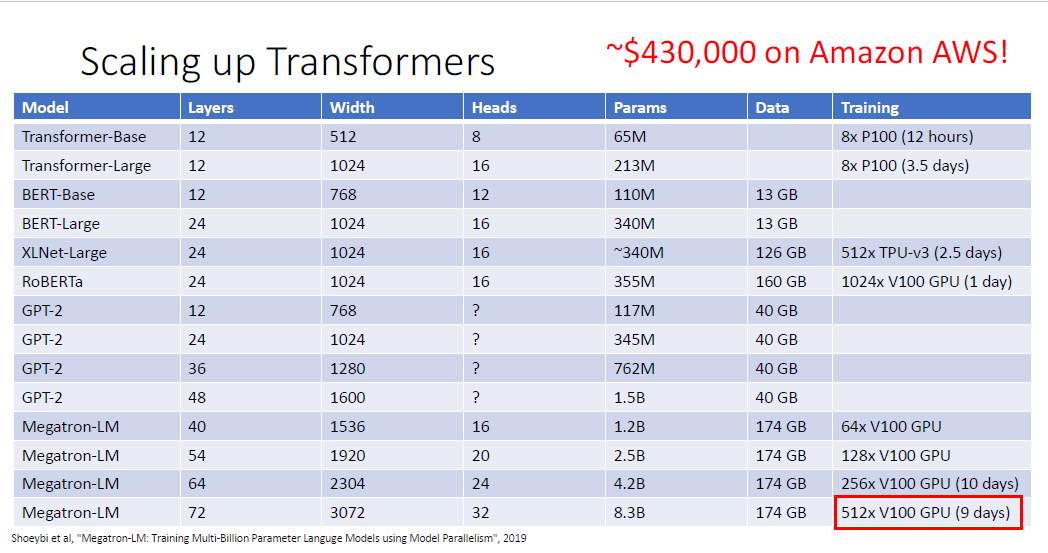
BERT는 340M까지 모델의 크기를 키웠고, 13GB의 텍스트 데이터를 통해 훈련시켰다. 텍스트 데이터로 13GB는 매우 많은 데이터이다. 이후 구글에서 계속 큰 모델들을 만들었다.
openai는 독자적인 데이터셋을 통해 더 큰 모델을 만들었고
nvidia는 트랜스포머에 등장하는 이름이기도 한 megatron이라는 모델을 만들었다.
특히 저 512대의 V100 GPU를 9일이나 훈련시킬려면 AWS에서 43만불,
훈련비로만 한화로 약 5억 7천만원이나 든다.
이러한 모델들은 text-generation에 특화되었는데
글 쓴 시점으로부터 4년전인 강좌에서도 이분야의 선두로 openai로 언급하고 프롬프트에 따른 생성 결과를 보여주는데
이분야의 발전은 정말 놀라운 것 같다.
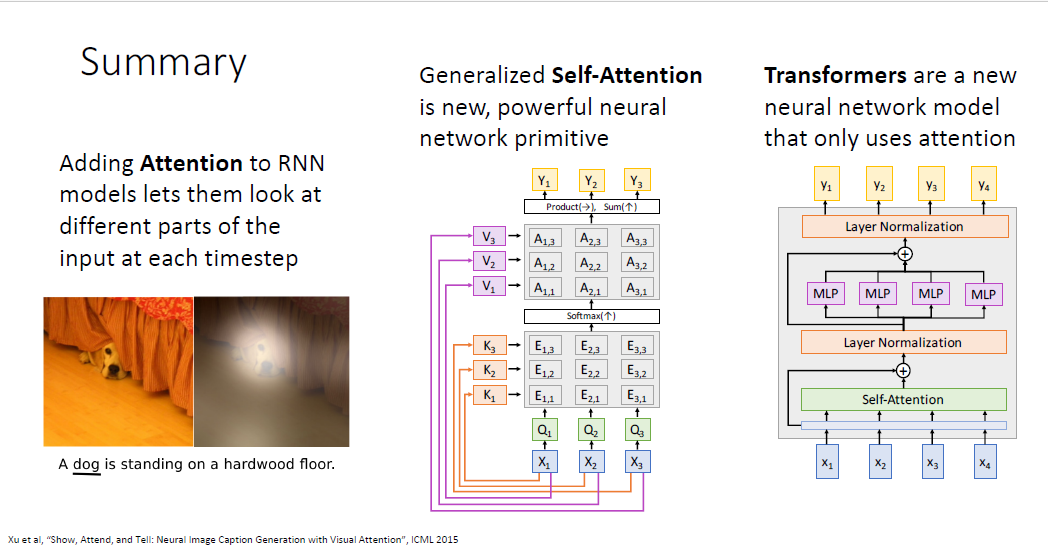
지금까지의 요약이다.
어느 부분에 집중할 수 있는지의 능력을 갖게한 어텐션 메커니즘
어텐션 메커니즘의 일반화된 버전인 Self-attention
self-attention만을 사용한 Transformer Block을 배웠다.
'기초 노트 > EECS 498-007 (ComputerVision)' 카테고리의 다른 글
| EECS 498-007 Lecture 12: Recurrent Neural Networks 정리 (1) | 2025.01.11 |
|---|---|
| EECS 498-007 Lecture11 : Training Neural Networks Part2 정리 (0) | 2025.01.11 |
| EECS 498-007 Lecture10: Training Neural Networks Part1 정리 (2) | 2025.01.11 |
| EECS 498-007 Lecture9 : Hardware and Software 정리 (0) | 2025.01.11 |
| EECS 498-007 Lecture 8: CNN Architectures 정리 (0) | 2024.04.02 |