첫 시간에는 강좌에 대한 소개와 컴퓨터 비전 그리고 딥러닝에 대한 전반적인 overview를 제공한다.
개론적인 역사에 관한 부분이니 가볍게 훑고 지나가도 될 것 같다.
키워드 : 컴퓨터 비전, 딥러닝, 인공신경망(Neural Net)의 역사

"Deep Learning for Computer Vision" 이라는 강좌의 제목이기도 한 철자에서,
각 Deep Learning과 Computer Vision이 의미하는 바가 뭘까?

우선 컴퓨터 비전은 비주얼 데이터(visual data)에 대해 가공하고, 인식하고, 추론하는 인공적인 시스템을 만드는 것이라고 할 수 있다.

시간이 지날 수록 visual data의 양은 기하 급수적으로 증가하고 있으며, 강의실에는 학생 수보다 대게 더 많은 카메라가 존재하기 마련이다. 전세계의 카메라는 매일 수백만장의 사진을 찍고 있다.
사람들은 visual data를 찍을뿐만 아니라, 공유하고, 서로 이야기한다. 따라서 이러한 visual data를 처리하는 알고리즘을 만드는 것은 중요한 일이 될것이다.
요즘 인스타그램의 인기는 상당한데, 매일 1억(100million) 이상의 사진이 업로드 된다.
유튜브의 경우는 더 심각한데, 매 분당 300시간의 동영상이 업로드 된다.
이런 방대한 양의 데이터를 사람이 직접 처리할 수는 없을 것이다.
그래서 오늘날 Deep Learning을 활용한 Computer Vision이 각광받는 이유이기도 하다.

오늘날 컴퓨터 비전에서 이러한 처리를 하게된 테크닉이 바로 "딥러닝"이다.
Computer Vision은 우리가 풀고자 하는 "문제"에 해당하고,
이 문제를 어떻게 해결 할 수 있을까에 대한 방법이 "Deep Learning"인 것이다.
(딥러닝은 visual data를 처리하는 방법중 하나이며, 딥러닝 이전 visual data를 처리하는 고전적인 알고리즘이 다수 존재하였다. 하지만 역시 최근 visual data의 처리는 딥러닝으로 대표된다.)
여기서 "Learning"의 의미가 무엇인가?
슬라이드 소개와 같이 data와 experience를 통해 학습하는 인공적인 시스템을 의미한다.
특별히, 오늘날에는 Learning가능한 알고리즘이 컴퓨터 비전뿐만 아니라 많은 데이터 사이언스의 분야에서 일반화될 수 있는 조건이라고 말한다.

딥러닝은 기본적으로 머신러닝의 하위 개념(subset)이다.
딥러닝은 많은 "layer"들로 이루어진 계층적인 학습 알고리즘이라고 소개한다.
특별히 포유류의 뇌에서, 뇌가 학습하는 방법, 뇌가 일하는 방법을 통해 영감을 받았다고는 하는데,
이러한 비유는 너무 조악한 설명(loosely inspired)으로
강의자는 이러한 비유를 진지하게 받아들이지 않아도 된다고 한다.

앞서말한 컴퓨터비전과, 머신러닝, 그리고 하위 개념인 딥러닝을 표현하고 있는 모식도이다.
본 강좌에서는 컴퓨터 비전과 딥러닝의 교집합을 다룬다고 이야기 한다.

AI = 딥러닝, 컴퓨터 비전 = 딥러닝이 아니며, AI에는 다양한 분야가 전방위적으로 존재한다.
본 강좌에서 자세히 다루지는 않지만 Robotics와 결합한 분야로 강화 학습(Reinforcement Learning)과 자연어 처리(Natural Language Processing)와 결합한 멀티 모달(multi-modal)이 최근 각광받고 있다.

컴퓨터 비전에 관한 연구는 Hubel과 Wiesle에 의해 1959년에 시작되었다.
그들은 고양이로부터 시각적 자극에 대해 뇌가 어떻게 반응하는지를 관찰하여
빛의 방향이라는 자극에 대한 반응을 하는 Simple cell
빛의 방향과 움직임에 대한 반응을 하는 Complex cell
end point와 움직임에 대한 반응을하는 Hypercomplex cell이 있는 것을 알아냈다.

1963년 Larry Roberts는 3D Geometry 이미지들을 다루었다.
기하학 형태의 도형을 컴퓨터가 이해할 수 있는 형태로 처리하였다.

이러한 연구와 컴퓨터 비전에 대한 흥미를 바탕으로,
1966년 MIT에서는 유명한 study중 하나인 "THE SUMMER VISION PROJECT" 가 시작되었다.
그러나 강의자가 말하길, 그들이 풀려고 한 문제를 50여년이 지난 지금도 풀기위해 열심히 노력하고 있다고 말한다.

1970년대 David Marr는, Visual Representation의 단계를 제시하였다.
최초의 Input Image로부터,
형태의 특징들에 대한 Primal Sketch의 단계, 2.5D Sketch, 3D Model Represnetation 단계를 제안했다.

이후 사람들은 단순히 object의 edge와 같은 형태가 아니라 복잡한 형태의 object인 사람들과 같은 객체를 detect하기를 원했다.
그러나 처리속도와 visual camera가 매우 제한적이어서 잘 되지 않았다.

80년대에 들어서는 조금더 나은 디지털카메라와 computationl power를 갖게 되었고 좀더 realistic한 이미지에 대해 접근이 가능해졌다. 이 시기의 주제는 edge detection을 통한 object recognition이다.

90년대에 들어서는, 더욱 복잡한 object와 scene을 인식(recognize)하기를 원했고, object를 grouping하는 연구도 진행되었다.
단순히 edge를 matching하는것에 그치는 것이 아니라 의미론적으로 일치하는 이미지에 대해서 segement하기를 원했다.(semantically meaningful chunks)
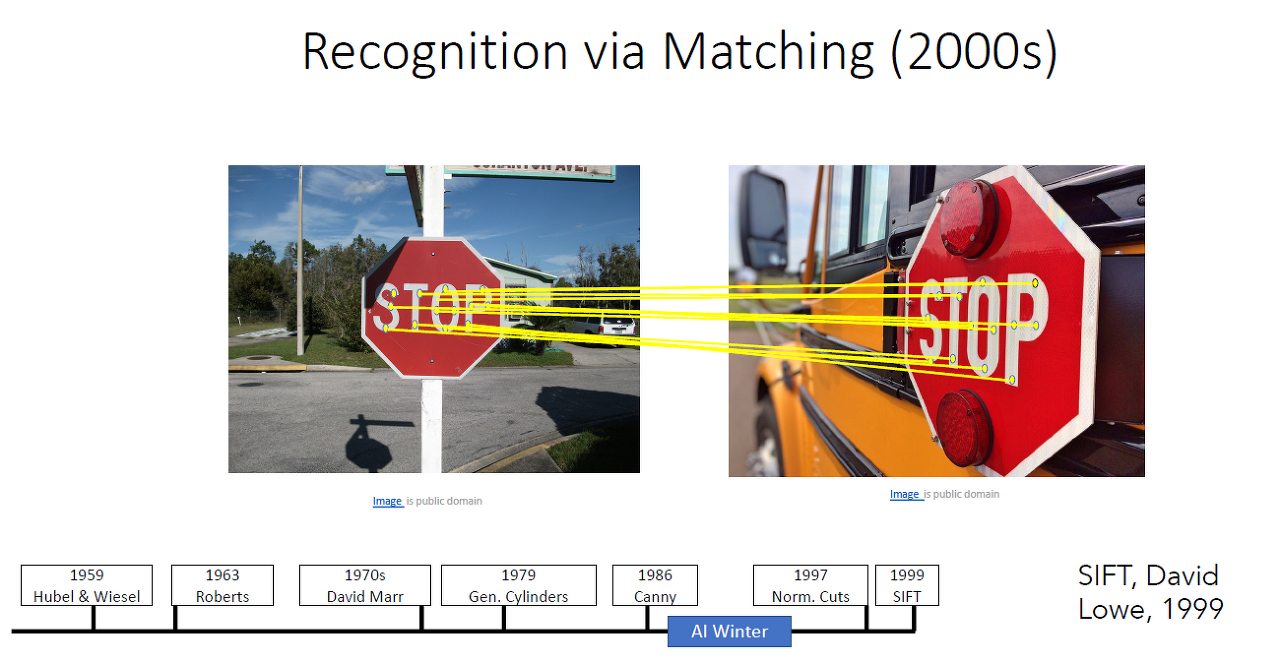
2000년대의 가장 유명한 알고리즘은 DAVID Lowe의 논문인 SIFT이다.
SIFT는 이미지를 input받아서 recognize할만한 key point를 특징벡터(feature vector)로 삼아 이미지 매칭(image matching)하는 방법이다.
feature vector는 invariant robust feature의 역할을 하며 좌측의 이미지의 특징벡터는 template으로써
우측의 이미지 처럼 다양한 각도로부터 촬영한 STOP sign이미지 등을 match 할 수 있다.

2001년 Face Detection은 머신러닝과 컴퓨터 비전으로 가장 유용하고 상업적으로 성공한 연구다. 해당 연구는 boosted decision tree algorithm을 사용하여 face recognition에 필요한 feature를 결정하는 방식이다. 2001년 발표 이후 디지털 카메라에 곧이어 적용되었다. 알다시피 자동적으로 얼굴에 집중하는 박스가 쳐지는 기능은 Viola and Jones의 알고리즘을 사용한 것이다.

가장 유명하고 영향력 있는 작업 중 하나가 PASCAL Visual Object Challege이다.
PASCAL VOC 데이터셋으로 잘 알려져 있으며, 2005년 이래로 2011년까지 쭈욱 성능이 향상된 모습이다.
인터넷에서 다운받을 수 있는 이미지로부터 라벨링하여 제작된 데이터셋이다.
농담인지 모르겠는데 강의자는 대학원생들이 라벨링에 참여하였다고 한다.

매우 매우 큰 스케일의 이미지 데이터셋인 ImageNet 데이터셋이다.
컴퓨터비전에서 현재까지 가장 영향력있고 가장 메인인 벤치마크 데이터셋이기도 하다.
140만장의, 1000개 이상의 레이블을 포함하고 있으며, 크라우드 소싱 방식으로 라벨링이 되었다.
ImageNet 데이터셋은 Large Scale Visual Recognition Challenge (ILSVRC)라고 불리는 IMAGENET challenge에서 사용되었다.
컴퓨터비전계의 올림픽으로서 연구자들은 이 데이터셋으로 classifier의 성능을 평가하였다.

딥러닝의 등장을 알리는 2012년 AlexNet의 등장에 오분류율이 큰 폭으로 줄어든 모습이다. (breakthrough moment)
AlexNet의 등장은 지금까지도 딥러닝의 시작을 알리는 역사적 사건으로 화자되고 있다.
이후 오분류율은 매우 빠른속도로 감소하기 시작했고,
이후 소개될 VGG Net, GoogLeNet이 당대의 SOTA(State of the Art)를 달성한 모습이다.
2015년 ResNet은 인간이 범하는 오류로 알려진 5%의 벽을 뛰어넘었다.

AlexNet의 등장은 AI Winter를 종식시킬만한 소식이었다.
1950년대~ 2000년대까지 오랜 기간동안 Neural Netowrk가 컴퓨터 비전의 주류가 아니었고
Neural Network 가 사실 갑자기 등장한 것은 아니나,
비로소 AlexNet의 등장으로 maintstream의 반열에 오르게 된것이었다. 매우 shocking한 사건이다.

Hubel and Wisel이 고양이의 시각반응에 대한 연구를 진행할 당시에 Perceptron이라는 개념과 알고리즘은 존재하였다.
당시에는 사람보다도 큰 기계, 하드웨어 자체로 적용되었다.

그러나 1969년 Minsky and Papert는 Percetron이 마법의 기계가 아니라고 지적하였다.
learning algorithm이 magical method라고 아니라고 지적하고, 학습을 통해서 특정 함수만 표현할 수 있을 뿐,
XOR Problem을 해결하지 못한다고 말한다.
그러나 이후에 Multi-layer perceptron은 이러한 문제를 해결하였고,
오늘날까지도 Multi-later percetorn(이하 "MLP")는 매우 flexible한 representation이 가능한 함수, 혹은 모델로 알려져 있다.

일본의 후쿠시마(과학자 이름)로부터 제안된 Neocognitorn이다. Hubel과 Wiesel의 뉴런의 계층적 처리(hierarchcical processing of neurons)에 영감 받아, 현대의 convolutional layer와 같은 기능을하는 computational simple cell,
현대의 pooling layer와 같은 기능을하는 computational complex cell을 제안하였다.

사실 1980년의 Neocognitron의 아키텍쳐는 2012년 AlexNet의 아키텍쳐와 매우 흡사하다.
그러나 그들은 매우 훌륭한 아키텍쳐를 제안했지만 어떻게 훈련시킬지에 대한 practical한 idea는 없었다.

1986년, Multi-layer perceptron을 훈련시키기위한 Backpropagation(역전파)가 소개 되었다.
오늘날 Neural Network를 만들고 훈련시킬때 사용되는 gradient, jacobian, hessian의 개념이 모두 소개되었다.

1998년 얀 르쿤은 Convolutional Neural Network를 제안하였다.

2000년대 사람들은 Neural Net을 bigger, deeper ,wider하게 훈련시킬 수 있는 방법을 모색했다.
이때 처음으로 "Deep Learning"의 개념이 등장하였다. 여기서 Deep은 Multiple Layer를 의미한다.

이러한 모든 것이 2012년에 통합되었다. 컴퓨터 비전뿐만 아니라 다른 모든 분야의 AI에서도 마찬가지다.
이러한 경향은 구글 트렌드와 CVPR의 Accepted Paper에서도 잘 보여준다.

2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다. (1) - Image Classification, Image Retrieval

2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다. (2) - Obeject Detection, Image Segmentation

2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다. (3) - Video Classification, Activity Reconition

2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다. (4)
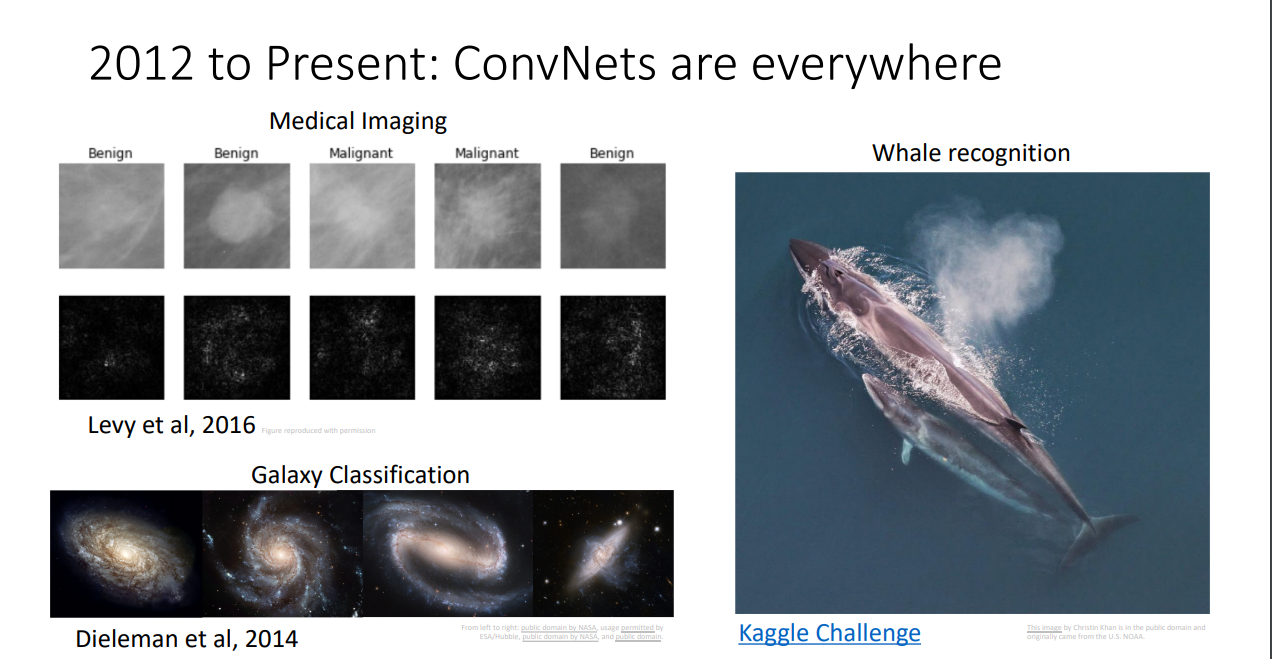
2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다. (5)
Whale recognition Kaggle Challenge(https://www.kaggle.com/c/whale-categorization-playground)

2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다. (6) - Image Captioning

2012년부터 지금까지, ConvNet은 이미지 처리의 모든 분야에 쓰인다 . (7) - Neural Style transfer

위와 같은 2012년의 매직, 컴퓨터 비전에 있어 딥러닝의 발전은 (1)CNN 알고리즘과, (2)매우 방대한 양의 빅데이터, 그리고 (3)Computational power가 있기에 가능했다.


이후 딥러닝의 선구자들, 요슈아 벤지오, 제프리 힌튼, 얀르쿤은 2018년 튜링상을 수상하였다.

하지만 아직도 사람의 인식처럼 정확히 작동하는 컴퓨터 비전 시스템으로서는 갈 길이 멀다.

대표적인 예시로 드는 사진이다.
위 사진을 보고 CNN은 라커룸, 사람들, 체중계 정도로 대답할 수 있을것이다. 그러나 사람들은 훨씬 더 다양한 방식으로 대답할 수 있다.
체중계를 주의깊게 보고 있는사람, 그런데 체중계의 수치가 생각한 수치보다 크게 의식하고 있는 사람, 그 사람 뒤에 서 있는 수 많은 사람, 그런데 사실 뒤에 남자가 체중계를 누르고 있는 모습, 그걸 파악하지 못한 사람, ...
Neural Network가 인간 수준의 인식 정확도에 도달하기까지에는 아직 많은 발전이 필요하다

다음 시간에는 Image Classification라는 주제로 본격적으로 Computer Vision과 Deep Learning이라는 주제를 다룬다.
'기초 노트 > EECS 498-007 (ComputerVision)' 카테고리의 다른 글
| EECS 498-007 Lecture 05 : Neural Networks 정리 (0) | 2024.03.17 |
|---|---|
| EECS 498-007 Lecture 04 : Optimization 정리 (0) | 2024.03.15 |
| EECS 498-007 Lecture3 : Linear Classifiers 정리 (0) | 2024.03.04 |
| EECS 498-007 Lecture2 : Image Classification 정리 (0) | 2024.03.04 |
| EECS 498-007 : Deep Learning for Computer Vision 소개 (0) | 2024.02.14 |