
플로라도의 data workout
EECS 498-007 Lecture 04 : Optimization 정리 본문
EECS 498-007 Lecture 04 : Optimization 정리
플로라도 2024. 3. 15. 00:01

이번 강에서는 Optimization에 대해서 다룬다.

Optimization의 topic은 Loss funciton에 input으로 $W$ matrix를 주었을때 output인 Loss를 최소화하는 $W_*$를 찾는 것이다.

Optimization은 앞이 보이지 않는 남자가 산비탈을 탐험 하는것과도 같다. 이러한 산비탈은 고차원의 풍경(high dimensional landscape)이라고 표현할 수 있다. 이 사람은 앞이 보이지 않기 때문에 산비탈에서 어떻게 optimal $W_*$를 찾아가야할지 모르는 상황이다.
남자가 밟고있는 ground의 $x,y$좌표는 각 $W$ matrix의 특정값을 의미하고 비탈의 높이는 $Loss$값을 의미한다.
Linear Regression과 같이 남자가 바닥에서 출발하더라도 단박에 explicit solution을 찾을 수 있으면 좋겠지만(normal equation), 대부분의 경우에는 그렇게 할 수 없어서 Iterative method를 사용해야 한다.
Iterative method란 optimal solution $W*$에 도달하기 위해서 반복적으로 $W$를 개선시켜 나가는 방법이다.

이러한 방법으로 가장 처음으로 생각해볼 것은 random search이다.
매우 간단한 아이디어지만 교육적인 차원에서 살펴볼 필요가 있다.
random search는 $W$ matrix에 랜덤한 값을 부여해서, 각각의$W$ matrix에 대응되는 $Loss$값을 전부 계산하여 크기를 비교하는 것이다. $Loss$를 반복적으로 계산하면서 $Loss$가 개선되면 $W$를 업데이트하는 방식이다. 이는 파이썬 코드 몇 줄로 작성할 수 있다.

그러나 이러한 방법은 CIFAR-10 dataset 기준 SOTA가 95%의 정확도를 보이는데 비해 15.5%의 정확도밖에 보이지 않는다.

두번째로 생각해볼 수 있는 방법은, 실제로도 사용하는 opimization 방법인데, 이번에도 역시 남자가 눈 앞이 보이지 않는 상황이지만, 남자는 감각을 통해 서 있는 근처의 주변의 경사를 파악할 수 있는 상황이다.
따라서 어느 방향으로 가면 가파르고 어느 방향은 완만한지를 느낄 수 있다.
이럴 때 우리가 취해야할 전략은 단순히 가파른 방향으로 조금의 step만큼만 가보는 것이다.
그러한 step을 반복함으로서, 우리는 최적의 $W_*$에 도달할 수 있다.

이를 수식화 해보면 위와 같은데, 미적분학에서 자주 등장한 gradient의 수식과도 같다.
gradient가 곧 앞선 경사(slope)를 의미하는 것이다.
gradient의 의미는 어떤 점으로부터 아주 조금 움직였을때, 그에 따라 y값이 어떻게 변화하는가를 보는 것이다.
남자가 밟고있는 ground의 $x$좌표를 아주 조금 움직였을때 $y$값이 어떻게 움직이는가가 곧 slope, 경사도, gradient가 된다.
위의 수식은 단순히 single variable gradient의 수식이지만 우리는 multiple variable gradient로 확장해야 한다.
그러면 단순히 $x$좌표가 아니라 이번에는 vector형태의 입력을 통해 벡터형태의 gradient를 얻게 된다.
다변수라고 하더라도 여전히 gradient의 방향이 Loss landscape, Loss function의 가장 가파른 방향이다.
gradient의 크기는 가장 가파른 방향으로의 증가정도를 나타내는 성질을 갖는다. (greatest increase)
그래서 단순히 gradient 크기의 반대는 그 지점에서의 가장 가파르게 감소하는 정도를 나타내고 (greatest decrease)
산비탈을 내려갈 요량이면, negative gradient의 방향으로 가면 되는 것이다.

그런데 여기서 질문이 있다.
gradient는 어떻게 계산하는 것인가?

사이즈가 큰 형태의 벡터인 current $W$가 주어져있다고 가정하자. 우리는weight matrix에 대응 되는 loss의 gradient를 구하기를 원한다. 다시 상기하지면 loss는 단순히 single value이다. gradient의 shape은 w matrix의 shape과 같으며 각 값의 크기가 말하는 것은 해당 w가 조금 증가한다면, 그 방향이 가장 가파르게 증가한다는 것을 의미할 것이다.
이것이 gradient의 numerical definition의 제한적인 버전이다.

우측과 같이 매우 작은 $h$를 0.0001로 상정하고 계산함으로써 gradient vector의 첫번째 slot을 채울 수 있다.

이러한 과정을 반복해서 역시second dimension에 대응되는 second slot을 채운다.

이러한 계산 방법은 "Numeric Gradient"라고 부른다. gradient를 고려할때 합리적인 방법처럼 보이지만, 계산이 매우 느리다. 위의 예시는 단순히 W matrix의 요솟값이 10개였지만, Weight Matrix의 크기가 크면 클수록 컴퓨팅 리소스가 상당히 많이든다.
매우 복잡한 인공신경망 시스템에서 $W$ matrix의 크기는 매우매우 매우크다. 수천, 수백만, 수십억이 될 수도 있는 parameter의 수 자체이기 때문이다. 따라서 Numeric Gardient는 high dimensional optimization problem에서는 impractical한 방법이다.
또한 이것은 true gradient에 대한 근사치 계산에 불과하다. (무한소인 $h$를 0.0001로 계산하였다.)
따라서 Numeric gradient는 계산량이 많고, 근사치에 불과하기 때문에 실제로 사용하지는 않는다.

gradient를 구하는 두번째 방법은 "Analytic Gradient" 이다.
감사히도 우리는 이 두 남자의 도움을 받아 gradient를 미분함으로써 구할 수 있게 되었다.
이 남자들이 누군지 아시는가?
우리는 아무튼 벡터 미적분학의 도움을 받아 Loss function에 대한 weight matrix의 gradient를 계산할 수 있다.

그럼 어떻게 analytic gradient를 구한다는건가? 이것은 6강의 backpropagation에서 상세히 다룰 예정이다.
아무튼 analytic gradeint의 방법으로 우리는 매우 매우 큰 형태의 weight matrix의 계산도 다룰 수 있게 된다.

지금까지의 요약이다.
Numeric gradient는 근사적이고, 느리지만 적기 쉽다
Analytic gradient는 정확하며, 빠르지만 실수하기 쉽다.
하지만 우리는 실제로 항상 analytic gradient를 사용한다. numerical gradient는 단지 디버깅 툴로서 사용한다.
만약 numerical gradient가 계산 가능한 저차원의 gradient라면 이를 analytic gradient와 비교를 통해 값을 확인하는 용도로 사용한다. 이를 gradient check라고 부른다.

pytorch에서는 gradcheck라는 간단한 함수를 제공한다. 역시 이를 사용해서 gradient check를 하는 것도 권장된다.

또한 gradgradcheck라는 함수도 있는데 second derivatve를 체크하는 것이다.
다행히 gradgradgradcheck, gradgradgradgradcheck ....는 없다.
아무튼 필요하다면 이 두가지를 사용해서 종종 체크하길 바란다.

Gradient Descent는 가장 낮은 loss값을 보이는 Weight Matrix , $W$를 찾는 과정이다.
단 4줄의 파이썬 코드로 작성할 수 있다.
Gradient Descent는 K-nn과 다르게 Neural Net을 build하고자 할때 여러분의 가장 친한 친구가 될수도, 가장 악랄한 적이 될 수도 있는 하이퍼 파라미터라는 것이 존재한다.
그 중 하나가 weight initialization방법이다. 보통은 weight의 초기값으로 random value를 사용하지만, 특정한 분포로 부터의 random value를 사용하는 전략이 많은 downstream application에서 통용되고 있다. neural net을 training시킬때 적절한 weight initialization 방법에 대해서도 곧 다룰 것이다.
두번째는 number of step이다. 우리는 언제까지고 학습시킬 순 없다. 일반적인 딥러닝에서는 특정 값까지 학습시키는 방법을 선택하는데, 대게는 학습을 시키면 시킬수록 좋은 결과를 가져온다. 하지만 언제까지 기다릴 수 있는지 혹은 컴퓨팅 리소스는 어떻게 되는지에 따라 달려있는 문제이다.
세번째는 Learning rate이다. 우리가 negative gardinet를 통해 step을 나아갈때, 이 방향을 얼마나 신뢰하는가?에 관한 문제이다. 이것은 우리의 network가 얼마나 빠르게 학습하는지와 관련되어 있다.

위는 Batch Gradient Descent 혹은 (Full) Batch Gradient Descent로 불린다
전체 Loss 라는 것은 각 훈련 데이터 샘플로부터 계산된 로스들의 총합이라는 것을 생각해보면, gradient 역시 동일하게 훈련 데이터 샘플의 gradient들에 대한 총합으로 규정되는 것을 알 수 있다.
이 때의 문제는, 만약 여러분의 데이터셋이 매우 큰 상황이라면 이러한 합의 계산의 연산 비용이 많이 든다는 것이다.
감사히 여러분이 큰 데이터셋을 갖고 있으나, gradient의 계산은 그만큼 수 많은 loop를 돌며 gradient들을 합하여 계산 된다. 따라서 단순히 한 스텝의 gradeint desent를 하기 위해서 전체 데이터셋을 순회하는 매우 긴 시간의 loop를 기다려야 한다. practical한 상황에서는 좋은 성능을 기대하기 위해서 이러한 방법을 고수하는 것은 적절하지 않다.

그래서 실제로는 gradient descnet의 변형인 SGD, Stochastic Gradient Descent를 사용한다.
전체 데이터셋의 gradient를 계산하여 합하기 보다는 전체 데이터셋의 작은 일부분인 subsample로 gradient를 근사하여 사용하는 방법이다. 이때 subsample의 사이즈를 일반적으로 mini-batch라고 부른다. 일반적으로 minibatch의 사이즈는 32, 64, 128를 사용하곤 한다. practical한 상황에서는 항상 SGD를 사용한다고 보면 된다. Full Batch Gradient descent에서 SGD로 넘어오면서 Weight initialization, Number of steps, Learning rate외에 새로운 하이퍼 파라미터인 Batch size가 추가 된다. Batch size의 의미는 각 mini batch마다 얼만큼의 수의 데이터 샘플이 포함되어야 되는지를 나타낸다.
그럼 Bath size는 또 얼마로 설정해야 된다는 것인가? 다행히도 batchsize는 senstive한 하이퍼 파라미터는 아니다.
경험적으로 Batch size는 gpu memory가 가용하는 한 최대로 크게 설정하는 것이 가장 휴리스틱한 접근 방법이다.
자세한 디테일은 이후에 또 다루겠지만 다시한번 말하자면 일반적인 경험적 법칙으로는 가능한 최대한 크게하면 된다.
두번째로 추가된 하이퍼 파라미터는 Data sampling이다. 우리는 매 iteration마다 데이터를 sampling해야 한다.
지금까지 이야기한 image classificatoin에서는 그다지 중요하지 않을 수 있지만, 첫번째로는 iteration마다 데이터를 랜덤하게 select하는 방법, 두번째로는 매 iteration마다 데이터의 순서를 shuffle하고 고르는 방법이 있다.
structured prediction problem 이나 triplet matching problem 혹은 ranking problem에서는 다소 중요한 부분일 수 있다.

그렇다면 이 방법이 왜 확률적 경사하강법(Stochastic Gradient Descent)라는 걸까?
왜냐 하면 loss function을 확률적으로 생각할 수 있기 때문이다.
전체 데이터 X와 레이블y에 대한 true underlying joint probability distribution이 있고, 데이터의 샘플들이 이로부터 샘플링 되었다고 생각한다면, 개별적 loss function에 대해서 가능한 모든 샘플에 대해 기댓값(expectation)을 취함으로써 loss function의 평균을 생각하고, monte carlo estimation의 방법으로 전체 데이터셋에 대한 loss function을 근사할 수 있다.
여기서, 개별적 loss function에 대하여 기댓값을 계산할때 얼마나 많은 data sample을 포함시켜야 하는지 문제가 생긴다.

이러한 확률적인 관점 때문에 Stochastic이라는 재미난 이름이 붙었다.
마찬가지로, 전체 데이터 중 일부의 샘플로 gradient를 계산 한 뒤 monte carlo estimation을 통해 전체 데이터셋에 대한 gradient 근사가 가능하다.

그러나 Baisc version의 SGD는 일부 문제를 마주할 수도 있다.
어떤 Loss landcape를 생각해보자, 위의 그림은 taco shell의 과장된 형태로 Loss landscape의 contour plot을 그린 것이다.
그림을 살펴보면, 한 방향에서의 변화는 매우 빠른데에 비해(수직방향) 다른 방향에서의 변화는 매우 느리게 진행된다.(수평방향)
만약 SGD의 방법이 이러한 Loss landscape를 마주하면 어떻게 될지에 대한 문제이다.
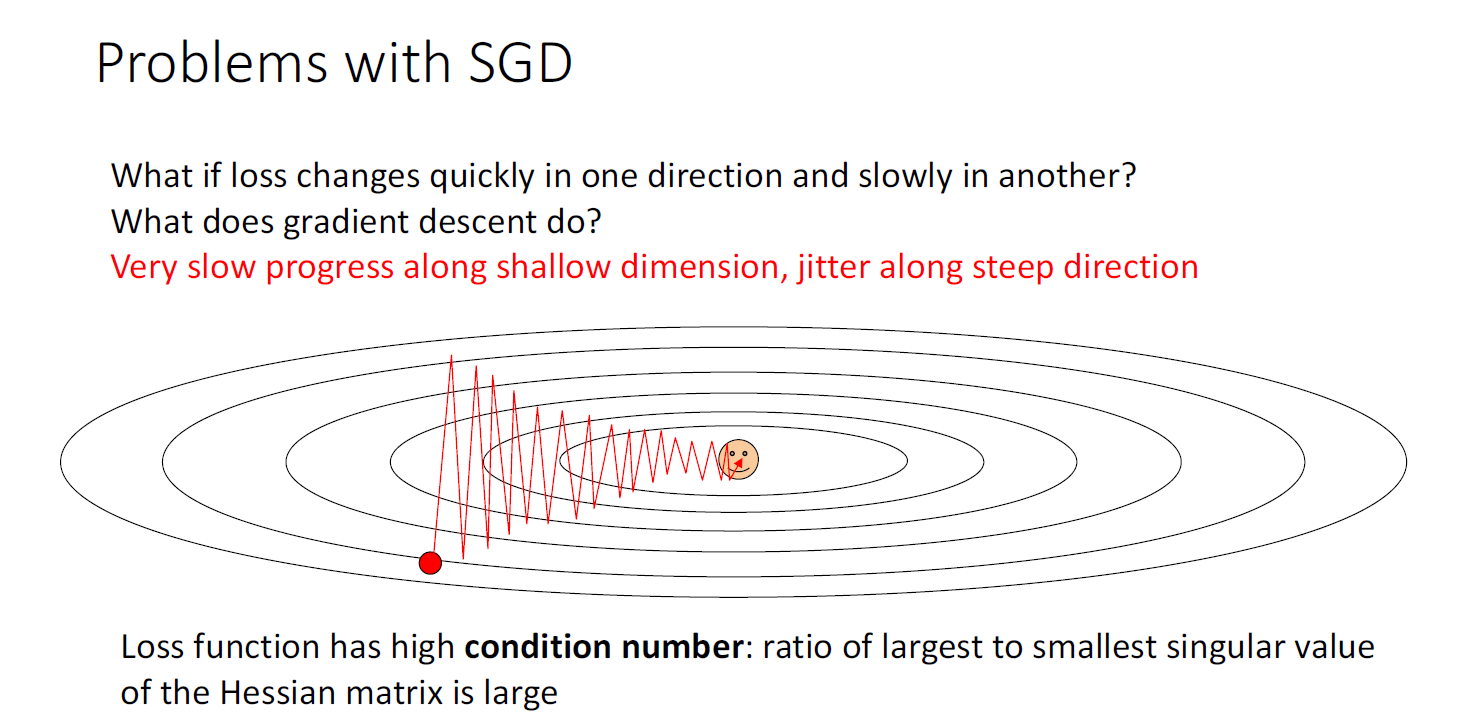
첫번째 문제는 step size를 크게 설정할 경우, 우리의 step이 진동(oscillate around)한다는 것이다. 이러한 지그재그 패턴에서는 더욱 많은 step이 필요할 수 있다. 이러한 문제를 피하기 위해 step size를 적게 설정하면, 알고리즘의 수렴속도는 매우 느려지게 된다.

SGD의 또 다른 문제의 가능성은 local minia 혹은 saddle point의 문제이다.
local minima는 함수가 zero gradient를 갖지만 함수의 최소값이 아닌 경우이다. 만약 loss function의 형태가 local minima가 형성된 경우의 상태라면 SGD를 사용할 경웅 이러한 local minima에 빠지게 될 가능성이 있다.
고차원의 optimization의 경우에 더욱 일반적인 문제의 상황은 saddle point이다. saddle point는 어느 방향으로는 함수가 증가하고 있지만, 어느 차원의 방향에서는 함수가 감소하고 있는 상태이다. saddle point라는 말은 말의 안장(saddle)과 닮아서 이름하게 되었다. 문제는 이러한 saddle point 역시 gradient가 zero라는 것이다.
따라서 local minima에 빠지는 것 처럼 saddle point에 동일하게 빠질 수 있다.
고차원의 경우, 통상 어떤 수백 수천차원에서, 어떤 차원은 증가하고, 어떤 차원은 감소하고 하는 경우가 많아 saddle point가 더욱 일반적으로 관찰된다.


SGD의 또 다른 문제는 gradient계산을 데이터 샘플의 작은 일부분인 minibatch 만큼을 사용해 계산하기 때문에 매우 noisy하다는 것이다. SGD의 방향이 gradient descent의 true direction과 정확히 일치하지 않아 최적의 W를 찾아가는데 상당한 step이 필요할 수 있다.

이러한 문제점을 피하기 위해 vanilla형태의 SGD는 잘 사용하지 않는다.

Neural Net을 훈련시킬때는 좀 더 스마트한 방법인 SGD+Momentum을 사용하곤 한다.
Momentum의 방식의 직관은 velocity vector를 추가하는 것이다. 공이 down hill을 따라 내려갈때의 관성을 생각이라고 생각하면 된다.
velocity vector는 현재 시점의 gradient와 gardient의 moving average인 velocity vector사이의 가중합으로 계산함으로써
이를 통해 업데이트를 하게 된다. 정확한 gradient의 방향이 아니라 계산된 velocity vector의 방향으로 이동하게 된다.
여기서 새로운 scalar 하이퍼 파라미터인 rho를 도입하게 된다. decay rate와도 같다.
우리는 postion에 관한 벡터인 $x_t$와 velocitiy vector인 $v_t$를 tracking하게 된다.

어떤 책이나 논문을 보느냐에 따라 SGD+Momentum의 위의 슬라이드 처럼 다른 형태의 식을 보게 될 수 도있는데,
두 수식은 같다. 어떤 수식을 사용하더라도 동일한 W matrix를 얻게 된다. 따라서 둘중 어느 방법을 선택하느냐는 구현의 차이이다.

Momentum의 방법은 앞서 언급한 Baisc version의 SGD의 문제들을 해결한다.
Local Minima와 같은 상황에서 현재의 gradient가 0이더라도, 이전의 gradient의 지수이동 평균인 velocity vector덕분에 이러한 local minma를 탈출할 수 있고
Saddle point의 경우에도 마찬가지로 서로 다른 차원의 서로 다른 velocity로부터 saddle point를 탈출할 수 있다.
또한, gradient가 지그재그 패턴으로 튀어 더 많은 step이 필요했던 문제에 대해서도 가중합의 영향으로 gradient를 smoothing하는 효과를 준다.

gradient의 noisy에 대해서도 vanilla SGD보다 더욱 개선된 방향을 보이는 것을 알 수 있다.

모멘텀의 업데이트 방식을 위의 그림처럼 생각해 볼 수 있는데,
매 시점마다, 빨간점에서 training동안 gradient들의 과거 지수이동평균의 결과인 초록색 벡터 Velocity vector 를 계산할 수 있고, 현시점의 gradient인 Gradient vector를 weight average를 통해 새로운 Velocity vector인 Actual step이라는 방향의 벡터를 얻게 되고, 이를 통해 weight matrix를 업데이트하게 된다.
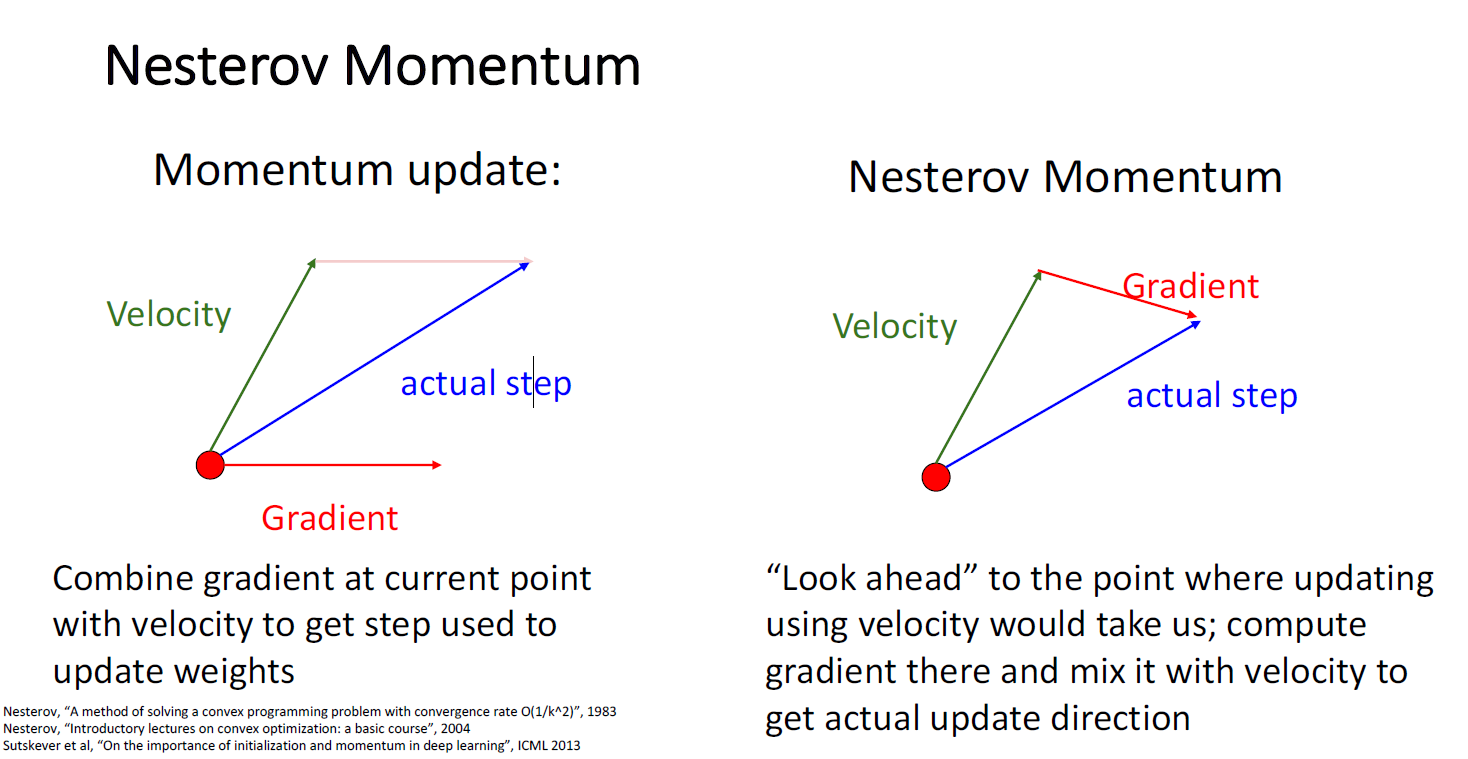
Momentum의 또 다른 버전으로 Nesterov Momentum도 있다. Momentum과 비슷한 직관을 가지고 있지만, 벡터를 더하는 순서가 다르다. Nesterove Momentum은 '앞을 보는것(Look ahead)'과 같다.
동일하게 빨간점으로 부터 시작해서, 여전히 gradient들의 과거 지수이동평균의 결과인 초록색 벡터 Velocity vector 를 계산할 수 있다. Nesterov와 일반적인 SGD+Momentum의 다른점은 만약 Velocity vector의 방향대로 간다면 미래의 gradient의방향이 어떻게 될지 앞을 보는 것이다. Actual Step은 이러한 두 벡터의 선형결합(Linear Combination)으로 이루어진다.

Nesterov Momentum의 formulation은 다음과 같다.
Nesterrov Momentum의 계산 방식은 조금 어색하게 들릴 수도 있다.
왜냐하면 대부분의 optimization의 문제는 current point에 대한 gradient에 대해서만 계산하기 때문에 velocity vector를 이동해서 간 point에 대한 gradient를 구하기가 쉽지 않다.

따라서 대부분의 API들은 current point에 대한 gradient를 다루는 방식으로 변형한 방식을 적용해서 사용한다.

SGD+Momentum과 Nesterov의 차이점은 traning process의 초반 optimization 단계에서는 SGD+Momentum의 경우 overshoot하는 경향(볼록 곡선)이 있다는 것이나 SGD+Momentum과 Nesterov 모두 수렴하는 부근에서는 step이 매우 천천히 진행된다는 것을 알 수 있다.

AdaGrad는 다른 문제를 극복하고자 했는데, 과거 전체 gradient들을 추적하기 보다는 과거 전체의 squared gradient를 추적한다.
이 때의 squared_gradient는 element wise의 gradient들의 곱이고 이를 누적해서 더하고,
이를 learning rate에 제곱근을 취해 나눠줌으로써 weight를 업데이트하게 된다.
이 방식은 파라미터별 learning rate 혹은, Adaptive learning rate 방식이라고도 불린다.

AdaGrad의 motivation을 이해하기 위해 다시 한번 타코 쉘을 떠올려 보자.
각 차원에 대하여
gradient가 클 경우, grad_squared값은 더욱 커지고, learning rate에 큰 값으로 나누기에 step size가 작아지게 된다.
gradient가 작을 경우, grad_squared값은 작고, learning rate를 작은 값으로 나누기에 (1보다 작은 값) step size가 커진다. 그래서 gradient의 지그재그 패턴인 Poor Conditioning을 완화시킬 수 있다.
하지만 AdaGrad는 step이 많이 진행되면 진행될수록 결국엔 누적합인 grad_squared가 커져서 gradient descent가 멈춰버릴 가능성이 있다.

따라서 이러한 문제를 개선하기 위해서 또 다른 알고리즘인 'RMS Prop'이 제시되었다.
Leaky version of Adagrad라고 생각할 수 있다.
SGD + Momentum에서 velocity를 decaying하는 상수인 rho가 있었다.
RMS Prop은 마찬가지로 grad_squared에 decaying term을 추가하여 step이 0으로 가지 않게 하고,
전체 기간 동안 gradient descent가 느려지지 않도록 한다.

이러한 두가지 아이디어를 합치는 방식은 어떨까?
킹마가 2015년 발표한 Adam이다. Adam은 딥러닝에서 가장 많이 사용하는 optimization 방법중 하나이다.
Adam은 SGD+Momentum과 RMSprop(Leaky AdaGrad)의 장점을 합쳤다.
Adam은 optimization process동안 두가지 변수를 추적한다. 하나는 SGD+Momentum에서 봤던 velocity이고(moment1)
하나는 RMSProp에서 봤던 Leaky squared_grad(moment2)이다.

Momentum의 아이디어는 빨간색 박스 부분이고 SGD+Momentum의 Basic version과 비교하면 다음과 같다.

RMSProp의 아이디어는 파란색 박스이고 역시 비교하면 다음과 같다.

Adam에는 약간의 문제가 있는데 optimization 초기, 즉 $time step = 0 $일때 일반적으로 설정되는 beta2의 값인 0.999를 가정해보면 moment2의 값은 0으로 initializaiton되기 때문에 $time step = 0 $ 에서 0에 매우 가까운 값을 얻게 된다.
그렇다면 weight를 0에 가까운 값으로 나눈값으로 업데이트를 한다는 것인데 이는 매우 큰 gradient step이 될 것이다.
이는 매우 좋지 않은 결과를 초래한다.

따라서 이러한 문제를 해결하기 위해서 Adam에서는 Bias correction term을 추가하였다.
Bias correction에 대한 full-formulation은 논문에서 확인해보길 바란다.
다만 아이디어 자체는 moment2가 optimization 초기에 0으로 편향되어있는 것을 해결하기 위한 것이다.

Adam은 매우 많은 딥러닝 시스템에서 practical하게 잘 작동한다. 사실상 처음 Neural Net을 빌딩할때 우선적으로 Adam을 적용시키는 것이 거의 루틴이다. 일반적으로 beta1=0.9, beta2=0.999를 사용하고 learnig_rate같은 경우에는 범위 내에서 다양한 값을 사용한다.

최근 서로 다른 테스크의 논문에서는 모두 Adam을 사용하였지만 각기의 learning_rate를 사용하였다.
Adam은 어떤 task든 매우 robust하게 잘 작동하고, 튜닝할 하이퍼 파라미터도 크게 많지 않아 가장 우선적으로 적용하면 된다.

지금까지 배운 Optimization 알고리즘에 대한 비교이다.

지금까지 배운 모든 알고리즘은 First-Order Optimization의 영역이다.
그들은 전부 gradient의 정보(first derivative; 일차 미분)만을 가지고 사용하여 gradient step을 만들어 내기 때문이다.


물론 higher-Order Optimization도 존재한다.
Second-Order Optimization같은 경우에는 gradient 뿐만 아니라 hessain의 정보도 사용한다.
이 아이디어가 나이스한 점은 얼마나 step이 커야 하는지를 adaptive하게 선택한다는 것이다.
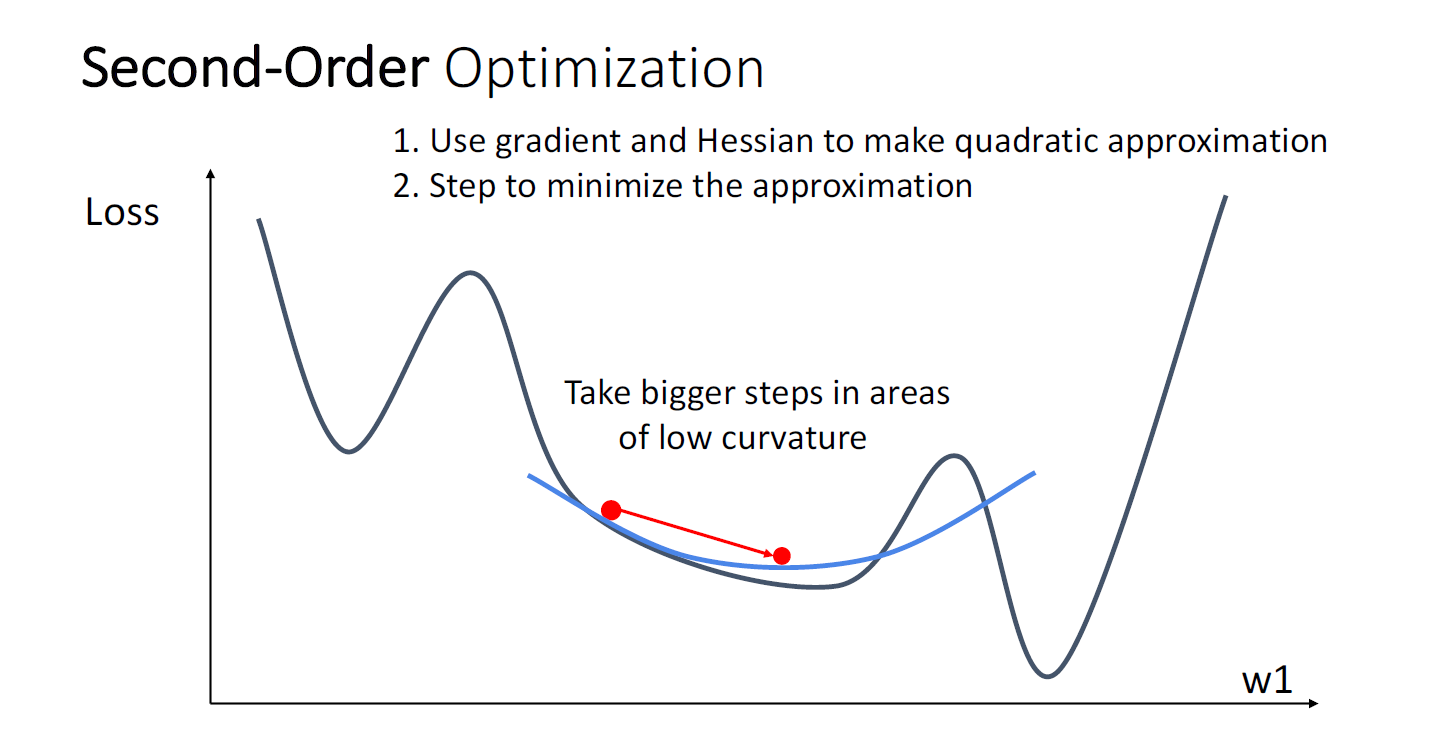
만약 gradient가 크고 quadratic curvature가 크다면 small step만큼 이동한다.
즉 이차 미분에 대한 정보를 봄으로써, 얼만큼 이동해야 되는지에 대해 더욱 안전하게 판단하게 된다.
즉 step을 세팅하는 것, learnig_rate를 세팅하는것에 대해 매우 robust하다.
AdaGrad가 이러한 Second-Order Optimization의 diagonal approximation의 일종이라고 한다.

Second Order Optimization은 quadratic taylor approximation을 통해 위와 같이 기술할 수 있다.

그러나 Second-Order Optimization는 딥러닝 시스템에 사실 실용적이지 않다

딥러닝은 엄청난 고차원의 파라미터를 다루고, gradient의 같은 경우는 파리미터의 갯수와 같은 요소의 개수를 갖지만 hessian matrix의 경우는 $n^2$ value를 갖아 메모리적 리소스 때문에 상당히 제한되고,
또한 hessian matrix의 역행렬을 필요로 하는데, 이는 $O(N^3)$의 계산을 요구한다.



지금까지를 요약하자면 일반적으로 Neural Net을 빌딩할때 Adam부터 적용해보고, SGD+Momentum을 잘 튜닝한다면 때로는 Adam보다 더 좋은 성능을 보일 수 있다.
그리고 데이터의 차원이 그리 크지 않아서 full batch를 통한 업데이트를 할 수 있고, stochastic한 특징을 피하고 싶다면 L-BFGS와 같은 Second-Order optimization을 사용할 수 있다.
그러나 아무튼 대부분은 Adam과 SGD+Momentum이다.

지금까지 강좌에 대한 요약이다.
1. Linear Model을 통한 image classification
2. Loss Function을 통해 가중치의 선택에 대한 우리의 선호("Preference")를 표현하는 방법을 배웠다.
3. Loss Fuction을 minimize하여 우리의 모델을 훈련시키는 SGD라는 방법을 배웠다.

Gradient Descent의 변형에 대한 계보이다.
위의 슬라이드에서 말하는 직관이 이해된다면 OK이다. (Nadam은 본 강좌에서 다루지 않았다.)
이후 2017년, Adam에 weight decay를 추가한 AdamW까지 추가되었다.

다음시간에는 드디어 Neural Networks에 대해서 다룬다.
'기초 노트 > EECS 498-007 (ComputerVision)' 카테고리의 다른 글
| EECS 498-007 Lecture 06 : Backpropagation 정리 (0) | 2024.03.21 |
|---|---|
| EECS 498-007 Lecture 05 : Neural Networks 정리 (0) | 2024.03.17 |
| EECS 498-007 Lecture3 : Linear Classifiers 정리 (0) | 2024.03.04 |
| EECS 498-007 Lecture2 : Image Classification 정리 (0) | 2024.03.04 |
| EECS 498-007 Lecture1 : Introduction (0) | 2024.02.21 |



