범주형 변수의 인코딩
정형데이터를 다룰때, 머신러닝 알고리즘에 수치형 변수가 아닌 카테고리형 변수(범주형 변수)를 적용시키려면 반드시 범주형 변수를 숫자값으로 변환시키는 작업이 필요하다. 이 작업에서는 사이킷런에서 제공하는 아래와 같은 Encoder클래스를 사용한다.

그 중 범주형 변수의 인코딩의 가장 대표격인 원-핫 인코딩에 대해서 알아보자.
1. 원핫 인코딩이란?

원-핫 인코딩은 위의 그림과 같이 'color' 칼럼에 해당하는 'red,blue,green'을 다음과 같이 'color_red, color_blue, color_green'의 각 고유한 피쳐로 나누고 값 칼럼에 해당하는 값을 0 또는 1의 binary 값으로 매핑한다. 0의 값은 관찰 데이터에 해당 피쳐가 속하지 않는다는 뜻이고 1은 관찰 데이터에 해당 피쳐가 속한다는 뜻이다.
원핫 인코딩을 하기 위해서 대표적으로 사용되는 것이 판다스가 제공하는 pd.get_dummies()와 사이킷런이 제공하는 OneHotEncoder()클래스이다. 그러나 이들의 사용에 있어서 데이터 분석과 모델링시에 주의점이 있다.
2. pd.get_dummies() vs OneHotEncoder()
머신러닝을 모델링할때 훈련 데이터와 테스트 데이터의 카테고리형 변수의 unique한 value가 모두 일치한다면 큰 문제가 발생하지 않는다. 그러나, 일반적으로 카테고리형 변수에 대해서 아래와 같이 세가지의 경우가 발생할 수 있다.
1) train data와 test data가 모두 카테고리형 피쳐에 동일한 범주를 갖는 경우
2) train data에는 존재하는 범주가 test data에 존재하지 않는 경우
3) test data에 존재하는 범주가 train data에 존재하지 않는 경우
위의 케이스에서 1번은 큰 문제가 없을 것이나 2,3번의 케이스는 별도의 처리가 필요하다.
우선 예시를 들기 위해 다음과 같이 샘플 데이터를 생성한다.
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# 학습 데이터
df_train = pd.DataFrame({
"색상": ["빨강", "파랑", "빨강", "파랑", "검정"]
})
# 테스트 데이터
df_test = pd.DataFrame({
"색상": ["빨강", "파랑", "초록"]
})
print('훈련 데이터')
display(df_train)
print('테스트 데이터')
display(df_test)


'빨강'과 '파랑'은 두 데이터셋에 모두 존재하지만
train data에는 '검정'이 추가적으로 들어가 있고, test data에는 '초록'이 추가적으로 들어가 있는 것을 알 수 있다.
앞서 말한 2), 3)번의 경우에 모두 해당되는 것을 알 수 있다.
1. pd.get_dummies()
pd.get_dummies(df_train)

별다른 처리 없이 pd.get_dummies()를 통해 범주형 변수를 인코딩한 결과이다.
판다스의 메서드이기 때문에 결과도 자동적으로 데이터프레임의 형태로 곧바로 출력되는 모습을 볼 수 있다.
그러나 단지 train data에 해당하는 범주값에 대해서만 칼럼이 생성된것을 알 수 있다. (이때 생성되는 칼럼을 '더미 변수'라고 하여 get_dummies라는 이름이 붙었다.)
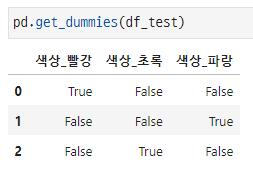
마찬가지로 test data에 pd.get_dummies()를 적용시킨 결과이다. 역시 test data에만 포함된 범주값에 대해서만 더미 변수가 생성되었다.
이러한 상태로 인코딩된 train data를 입력받아 훈련시킨 머신러닝 알고리즘은 정상적으로 작동하지 않는다. 추론시 입력받는 test data의 더미 변수가 train data와 다르기 때문이다.
pd.get_dummies()는 단순히 범주형 칼럼에 대해서 더미 변수를 생성해줄 뿐, 이러한 문제에 어떠한 해결책도 제공하지 않는다.
2.OneHotEncoder()
# OneHotEncoder 생성
ohe = OneHotEncoder(sparse=False) #희소 행렬 대신 array형태의 output을 위해 sparse=False로 설정
# 학습 데이터로 OneHotEncoder 학습
ohe.fit(df_train[['색상']]) #fit은 반드시 train데이터에 대해서만 적용해야 하며 데이터 프레임을 입력으로 받음
# 테스트 데이터 변환
df_test_encoded = ohe.transform(df_test[['색상']])
ohe라는 변수로 OneHotEncoder클래스의 인스턴스를 생성하고 train data에 fit시킨다.
주의점은 입력으로 df_train['색상']의 시리즈가 입력형태가 아닌 , df_train[['색상']] 이 들어가야 한다. (데이터프레임의 칼럼지정 방법)

그러나 OneHotEncoder가 피팅한 train데이터의 정보에는 '초록'의 값이 없기 때문에 ( 3)test data에 존재하는 범주가 train data에 존재하지 않는 경우) test data를 원핫인코딩하려 시도하면 위와같은 ValueError : Found unknonwn categories 가 뜨게된다.
이러한 경우 해결 대처할 수 있는 방법이 두가지가 있다.
2-1. handle_unknonwn = 'ignore'
OneHotEncoder를 선언 할 때, handle_unknown='ignore' 를 추가하면, 위와 같은 에러를 해결하고 정상적으로 값이 출력 되는 것을 확인할 수 있다.
# OneHotEncoder 생성
ohe = OneHotEncoder(handle_unknown='ignore') #handle_unkown 옵션 추가
# ignore옵션이 적용된 ohe에 훈련데이터 피팅
ohe.fit(df_train[['색상']])
# 테스트 데이터 변환
df_test_encoded = ohe.transform(df_test[['색상']])
# 결과 출력
display(pd.DataFrame(df_test_encoded))
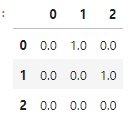
pd.DataFrame(ohe.transform(df_train[['색상']]))

결과를 원 데이터와 비교해보면, 0번 칼럼은 검정 특성을, 1번 칼럼은 빨강 특성을, 2번 칼럼은 파랑 특성을 나타내는 것을 알 수 있고, 테스트 데이터의 2번 index의 '초록' 값은 인코딩 결과 [0,0,0] 으로 어떠한 특성을 가지지 않는 데이터로 표현됨을 알 수 있다.
2-2. categories 지정 방법
두번째 방법으로는 인코더 선언시에 인코딩할 데이터 요솟값을 categories라는 파라미터로 리스트 형식으로 입력하는 것이다. 우리의 예시에서 train data와 test data에 모두 등장하는 요솟값들을 하나의 리스트 ["검정","빨강", "파랑", "초록"]으로 만들어 파라미터로 입력하였다.
ohe = OneHotEncoder(categories=[["검정","빨강", "파랑", "초록"]], sparse=False)
ohe.fit(df_train[["색상"]])
df_test_encoded = ohe.transform(df_test[["색상"]])
다만 categories를 통해 명시적으로 원-핫 인코딩할 train과 test의 데이터 요솟값을 지정해주는 것은, `data leakage`의 문제와 관련이 있으니 세심한 주의가 필요하다. test data를 참조하여 인코딩하지 못하는 경우에는 이러한 방법은 적용 할 수 없다.
또한 참고적으로, categories선언 시 이중 리스트의 형태로 값을 넣어주어야 한다. 카테고리의 목록을 감싼 리스트 안에 카테고리의 범주값을 리스트로 다시금 넣어줘야되기 때문이다.
그렇지 않고 단일 리스트로 사용하면 아래와 같은 에러가 뜨게 된다. (ValueError: Shape mismatch : if categories is an array, it has to be shape (n_features,).)

feature_names = ohe.get_feature_names_out()
pd.DataFrame(df_test_encoded,columns=feature_names)

pd.DataFrame(ohe.transform(df_train[['색상']]), columns=feature_names)
명시적으로 칼럼의 이름까지 설정해주면 위와 같은 결과를 얻게 되는 것을 알 수 있다.
3. 완전 공선성(Perfect multicollinearity)
원핫 인코딩시에 또 다른 주의점이 있는데 , 바로 완전 공선성(Perfect multicollinearity)이다.
완전 공선성이란 하나의 변수가 나머지 변수에 의해 완벽히 설명되는 것을 말한다.
1. 두 변수가 서로 동일한 정보를 나타내는 경우
예를 들어 성별이라는 칼럼은 , 남자여부 라는 칼럼과 동일한 정보를 제공할 뿐이다.
2. 한 변수가 다른 변수의 선형 조합으로 표현 되는 경우
예를 들어 키와 몸무게 사이에 "키 = 몸무게 * 2 + 100" 과 같은 선형식이 성립한다면 이 역시 완전 공선성이다.
이러한 완전 공선성은 여러 변수를 통해 데이터의 차원은 늘리지만 서로 동일한 정보를 제공하기 때문에 문제가 발생할 수 있다.
우리의 예시에서,

4번 인덱스의 데이터를 예로 들면 '색상_검정' 칼럼이 굳이 없어도, 빨강, 파랑 ,초록 칼럼이 (0,0,0) 이라면 그 자체로 검정색임을 표현 할 수 있게된다. 따라서 '색상_검정'은 다른 나머지 세개의 칼럼과 완전 공선성을 갖게 되고 이를 삭제하는 것이 공선성 때문에 야기될 수 있는 문제를 피하는 방법으로 사용 되고 있다.
다만 머신러닝을 모델링은 결코 regularized 되지 않은 단순한 모델을 사용하는 것이 아니라, 더욱 복잡한 형태의 모델에 추가적으로 regularization을 취하는 형태로 모델링을 하곤 하기 때문에, 큰 문제가 되지 않을 수도 있다고 한다.
4. Decision tree-based model에서
그러나 사실 정형 데이터에서 잘 작동하는 트리계열의 모델에서 이러한 원-핫 인코딩의 고려는 불필요하다.
트리 계열의 범주형 변수의 처리는 다른 어느 알고리즘(Neural Net, SVM, Linear Regression,...etc) 보다 더욱 우수하다.
데이터를 단순히 정렬하는 것을 통해 범주형 데이터를 처리하는 Decision tree의 기본 아이디어로부터 출발하여, 다양한 트리계열 모델(random forest, gradient boosting machine, xgb, lgbm , catboost..)이 어떻게 범주형 변수를 처리하는지에 대한 직관을 알고 있다면 트리계열 모델들은 원-핫 인코딩시 성능이 매우 떨어지게 됨을 알 수 있을 것이다.
원-핫 인코딩 된 대부분의 요솟값은 0일 것이고, 트리모델은 level과 다음 level로의 분기를 정보의 획득을 기준으로 수행하기 때문에, 매우 낮은 정보획득량으로는 좋은 모델이 만들어질 수 없다.
5. 카테고리형 변수가 너무 많은 경우
카테고리형 변수가 너무나 많은 경우, 이를 원-핫 인코딩하게 되면 기존의 칼럼 수 보다 칼럼 수가 엄청나게 늘어날 것이다.
이럴 경우에는 원-핫 인코딩이 일반적으로 권장되지 않는다. 원-핫 인코딩으로 sparse data가 만들어지게 된다면, 다른 방식의 인코딩을 취하는 것이 나은 선택이 될 수 있다.
EDA와 적절한 feature engineering을 통해 이러한 상황을 미연에 방지해야 한다.
또한, 최소한 데이터 샘플의수가 피쳐의 수보다 5배는 많길 권하고 있다.
6. 원핫 인코딩을 언제해야하는가? 주의점
원-핫 인코딩을 train data와 test data로 split 한 뒤에 수행해야 할까? split하기 전에 수행해야 할까? 이부분에서 사람들이 많은 실수를 하게 된다.
일반적으로 test data를 볼 수 없는 상황을 가정한다면, 원-핫 인코딩은 train_test_split을 수행한 뒤 이루어져야 data leakage의 문제를 피할 수 있다. split을 하지 않은 원본 데이터셋에서, 원-핫 인코딩을 수행하고 train_test_split을 수행하게되면 train 데이터의 정보가 test 데이터에 누수되기 때문이다.
하지만 단순히 EDA 등이 목적이라면 이러한 구분은 의미가 없다.
결론
EDA에는 판다스의 pd.get_dummies() 메서드를 활용해도 좋으나, 모델링 혹은 피쳐 엔지니어링시에는 반드시 사이킷런의 OneHotEncoder 클래스의 기능을 활용하도록 하자.
Reference
2) 사이킷런 공식 문서 : https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
3) 캐글 discussion :https://www.kaggle.com/code/marcinrutecki/one-hot-encoding-everything-you-need-to-know
'기초 노트 > DataScience' 카테고리의 다른 글
| 차원의 저주(Curse of dimensionality) (0) | 2024.03.07 |
|---|---|
| Stacking과 Blending의 차이 설명 (5) | 2024.03.06 |
| 편향(Bias)와 분산(Variance) 그리고 Bias-Variance Decomposition (2) | 2024.02.16 |
| Loss Function vs Cost Function vs Objective Function은 무슨 차이 인가요? (0) | 2023.07.01 |
| 경사하강법 (gradient desecent) vs 뉴턴-랩슨 방법 (Newton–Raphson method) (0) | 2023.07.01 |