Stacking
Stacking은 단일 모델의 예측값을 조합하여 최종적인 예측을 함으로써, 개별 모델의 강점을 활용하고 약점을 상쇄시키는 방법이다. 트리기반 모델은 데이터의 비선형 관계를 잘 포착하고, 선형 모델들은 데이터의 선형관계를 잘 포착한다. 이러한 모델의 예측 결과를 조합함으로써, 단일 모델이 놓칠 수 있는 정보를 포착하고자 하는 것이다.
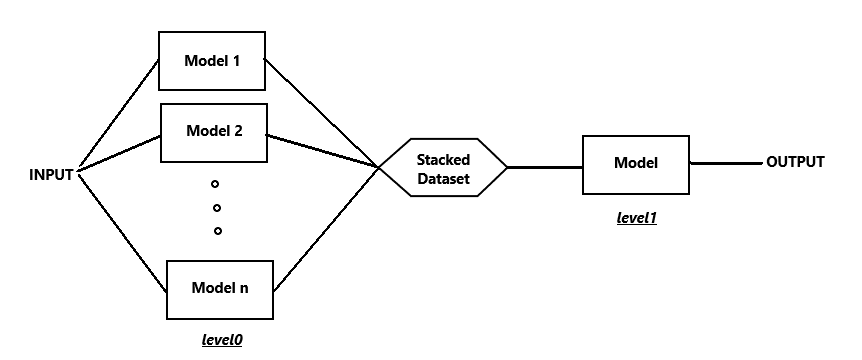
먼저 Stacking은 위의 그림과 같이 진행된다.
각 level0에 위차한 각기의 learner(모델)들은 예측값을 생성하고, 이러한 예측값들을 결합하여 Stacked Dataset을 만든다.
이러한 Stacked Dataset을 Meta model이라고하는 level1에 있는 최종 모델이 다시 한번 예측을 수행하고, 이러한 예측의 결과를 최종적인 output으로 채택한다. 물론 경우에 따라 level1에도 여러 단일 모델을 사용하여, 다시한번 스태킹을 하고 level2에서 최종적인 예측을 수행할 수도 있다.

stacking은 기본적으로 cross validation(cv)의 방법을 사용한다.
먼저 다음과 같이 train data와 test data가 나뉘었다고 하자. 위는 4개의 fold로 train data를 나눈 모습이다.

k-fold의 방법대로 4개의 fold중 3개는 훈련에 사용되고, 1개의 fold만 validation에 사용되게 된다. 이때 train을 통해 학습한 정보로 validation fold의 데이터를 예측하고, 이를 새로운 피쳐 'pred_m1'에 추가한다.

각 fold를 순회하면서 'pred_m1'을 모두 채워 넣는다.

즉 이로써, Model1이 Stacked Dataset에 들어갈 새로운 피처인 'pred_m1'을 생성한 것이다.
마찬가지로 서로 다른 모델, 혹은 하이퍼 파라미터 튜닝 및 피처엔지니어링을 달리한 여러 학습조건의 모델들의 각기의 예측값을 모두 Stacked Dataset에 채워 넣는다.

예를 들어 3개의 모델을 사용한다고 가정하면 [ 'pred_m1', 'pred_m2', 'pred_m3'] 가 Stacked_Dataset을 구성하게 된다.
훈련 데이터뿐만 아니라, 테스트 데이터에서도 동일하게 각각의 모델을 이용하여 test data의 예측값인 [ 'pred_m1', 'pred_m2', 'pred_m3'] 를 채워 넣는다.
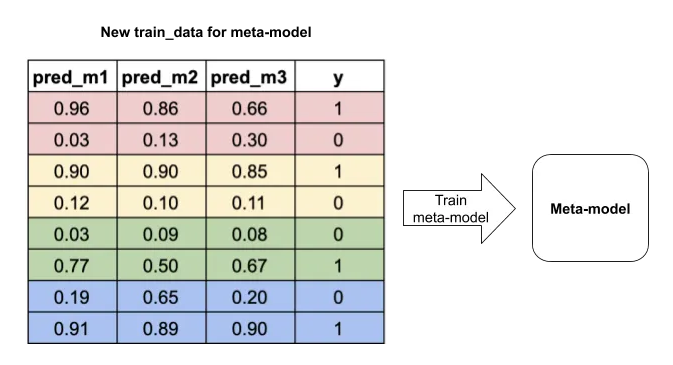
마지막으로 true label y는 원본 데이터의 y값을 그대로 사용하고, 최종 예측모델인 메타 모델로 [ 'pred_m1', 'pred_m2', 'pred_m3'] 라는 세개의 피쳐로 y값의 예측을 진행하면 된다.
Stacking과 Blending의 차이점
지금까지 Stacking의 과정만 쭈욱 살펴봤다. 사실 Stacking과 Blending의 차이는 k-fold 세트, holdout세트의 활용 차이다. Blending은 holdout set(train과 validation 두가지 fold로만 나누어진)만 학습에 사용하고 holdout세트인 validation data에 대한 예측값만을 새로운 데이터셋에 추가함으로 구현이 좀 더 간단하나 사용하는 데이터의양이 validataion data로 한정되어stacking보다 오버피팅에 빠질 위험성이 있다.
왜 Stacking이 잘 되는가?
대부분의 머신러닝 모델들은 특정한 가정과 상황에 잘 맞도록 구성된다. 이로 인해서 모델 아키텍처상의 bias가 존재하기 때문에 훈련 데이터의 noise가 아니더라도 bias는 항상 존재할 수 밖에 없다. Stacking은 여러 모델의 예측값을 결합함으로써 이러한 모델 자체의 bias를 상쇄하고자 하는 것이다.
Reference)
https://iq.opengenus.org/stacked-generalization-blending/#google_vignette
'기초 노트 > DataScience' 카테고리의 다른 글
| 데이터의 Cardinality란 무엇인가? (2) | 2024.03.07 |
|---|---|
| 차원의 저주(Curse of dimensionality) (0) | 2024.03.07 |
| 원-핫 인코딩의 모든 것(feat.OneHotEncoder vs pd.get_dummies) (1) | 2024.03.05 |
| 편향(Bias)와 분산(Variance) 그리고 Bias-Variance Decomposition (2) | 2024.02.16 |
| Loss Function vs Cost Function vs Objective Function은 무슨 차이 인가요? (0) | 2023.07.01 |