
1. 선형성(Linearity)
독립변수와 종속변수, 설명변수와 응답변수, 다시말해 데이터 과학에서의 피처의 집합인 $X$와 타겟 값 $y$가 선형적인 관계를 가져야만 한다. 가장 잘 피팅된 선형 회귀 모델은 곧은 직선 형태임으로, 가장 직관적인 특징이다.
여기서 선형은 $X$와 $y$간의 "관계"의 선형성, 즉 파라미터의 선형성을 일컫는 말로
독립변수$X$의 선형과는 관계가 없다. 종종 독립변수 $X$에 제곱이나 혹은 교차항(interaction)을 추가하기도 하는데 이는 다항 회귀(Polynomial Regression)으로 불린다.

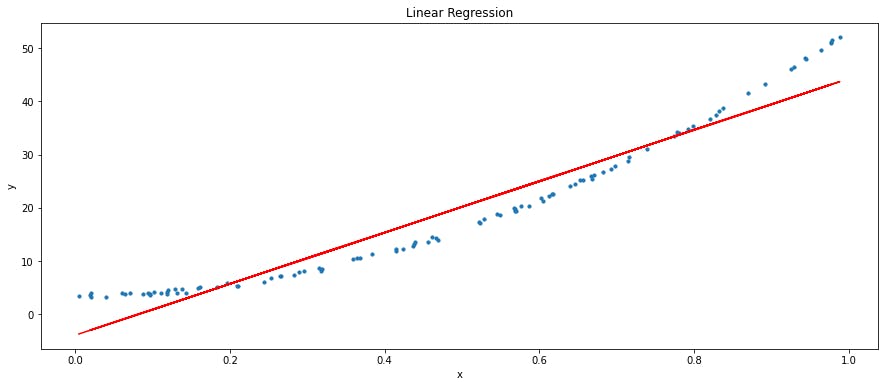
조금 더 부연하자면, 피처의 집합인 $X$와 타겟 값 $y$가 선형적인 관계를 가져야만 하는 이유는 애초에 선형모델이 해당 가정하에 설계된 모델(inductive bias)이기 때문이다. 그렇지 않으면, 변수의 관계를 제대로 표현하지 못하는 것은 당연하다.
2. 독립성
잔차(Residual)는 서로 독립적이며, 한 관측치의 오차가 다른 관측치의 오차에 영향을 주지 않아야 한다.

시계열 분석에서 주로 볼 수 있는 자기상관(autocorrelation)는 오차 항 간의 상관관계가 존재하는 현상으로, 시계열 데이터의 경우 과거 데이터와 미래 상태의 데이터가 밀접한 연관을 보인다. 이는 대표적으로 잔차의 독립성을 위배하는 현상이다.

3. 등분산성
잔차(Residual)의 분산이 일정한 상수여야 한다. 아래의 그림과 같이 잔차의 분포가 특정한 패턴을 보이면 안된다.
데이터의 어떠한 값과 상관없이 잔차는 좌측의 그림처럼 고르게 분포되어 있어야 한다.

4. 정규성
잔차가 정규분포를 따라야 한다. 잔차의 정규성 가정아래 회귀 계수에 대한 우도의 최대화(MLE)하는 것은 잔차의 제곱합을 최소화(OLS)를 통해 계산된 회귀 계수와 동일한 값을 갖게 됨으로, 우리는 이러한 가정아래 OLS를 통해 회귀계수를 추정하게 된다.
회귀 계수$\beta$의 가정하에 target $y$에 대한 우도(likelihood)함수는 아래와 같이 쓸 수 있다.
$$L(\boldsymbol{\beta}; \mathbf{y}) = P(\mathbf{y} | \boldsymbol{\beta})$$
이 때 선형회귀 모델의 추정값은 각 오차항을 포함한 아래의 식으로 표현이 가능하며, 오차(잔차)는 정규성을 가정하게 된다.
$$y_i = \boldsymbol{x}_i^T \boldsymbol{\beta} + \epsilon_i \quad \text{for } i = 1, 2, ..., n$$
$$\epsilon_i \sim N(0, \sigma^2)$$
$$y_i \sim N(\boldsymbol{x}_i^T \boldsymbol{\beta}, \sigma^2)$$
따라서 선형회귀 모델을 통해 구하는 추정치의 확률 밀도 함수는 다음과 같이 표현할 수 있게 된다.
$$f(y_i | \boldsymbol{\beta}, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - \boldsymbol{x}_i^T \boldsymbol{\beta})^2}{2\sigma^2}\right)$$
이때, 각 관측치(데이터)는 독립성을 가정함으로 개별 확률 밀도를 모두 곱한 값으로 표현할 수 있다.
$$L(\boldsymbol{\beta}, \sigma^2 | \mathbf{y}) = \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - \boldsymbol{x}_i^T \boldsymbol{\beta})^2}{2\sigma^2}\right)$$
이 우도 함수를 최대화하기 위해 로그 우도를 취하면 계산이 간단해지며, 로그 우도 함수는 다음과 같게 된다.
$$\log L(\boldsymbol{\beta}, \sigma^2 | \mathbf{y}) = -\frac{n}{2} \log(2\pi) - \frac{n}{2} \log(\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^{n} (y_i - \boldsymbol{x}_i^T \boldsymbol{\beta})^2$$
$MLE$(maxiumum log likelihood)는 위 로그 우도 함수를 최대화 하는 $\beta$값을 찾는 과정이다. 로그 우도 함수에서 $\beta$와 관련된 항은 잔차 제곱합에 해당하는 항이고,
$$-\frac{1}{2\sigma^2} \sum_{i=1}^{n} (y_i - \boldsymbol{x}_i^T \boldsymbol{\beta})^2$$
따라서, 로그 우도를 최대화 하는 것은 잔차 제곱합을 최소화 하는 것이므로, $MLE$에서 추정된 $\beta$는 OLS(최소제곱법)을 통해 계산된 회귀 계수와 동일하다. 즉, 잔차가 정규분포를 따를 경우 MLE와 OLS가 일치하게 된다.
(이러한 논리적 배경과 근거는 선형회귀를 모두 모은 딥러닝 MLP 모델에서도 이어지게 된다.)
reference)
https://kantschants.com/assumptions-of-linear-regression
https://www.originlab.com/doc/Origin-Help/Residual-Plot-Analysis
'기초 노트 > DataScience' 카테고리의 다른 글
| L1,L2 Regularization은 우리의 prior knowlege를 반영한다. (2) | 2024.03.15 |
|---|---|
| 선형회귀 분석에서 로그 변환을 취하는 이유 (0) | 2024.03.14 |
| 데이터의 Cardinality란 무엇인가? (2) | 2024.03.07 |
| 차원의 저주(Curse of dimensionality) (0) | 2024.03.07 |
| Stacking과 Blending의 차이 설명 (3) | 2024.03.06 |